
对于大批量文件的解析操作优化_go语言案例
分析
日常开发中, 往往有这样一直需求 – 解析文件。
针对文件的解析工作, 有两种场景让人头疼:
- 单个文件过大, 如 5G 以上甚至更大。 -> 常见于年久失修的 log 日志。
I/O 瓶颈 是一个无法逾越的鸿沟, 因此 对于此种情况的常用处理方式 通常会利用 linux的tmpfs这个内存挂载, 也就是 这个路径目录 -> /dev/shm/
- 整体文件夹大小过大, 但内部都是些小文件组成的, 也就是需要解析的文件数量过多, 通常一个解析文件夹中就包含了成千上万个文件, 但是单个文件小, 通常不到10M。 -> 常见于 测试报告之类的报告集合。
虽然也存在I/O瓶颈, 但由于单个文件过小, 往往根本无法触及 I/O 瓶颈, 达不到其吞吐量, 因此利用 内存文件系统 对其进行操作的意义不大, 存在较大的优化空间, 可以利用多线程来磨平I/O瓶颈, 是其瞬间吃满吞吐量, 从而保证读取文件的速度。 此种情况下, 是否利用 linux的 tmpfs内存挂载, 意义已经不大了, 因为此时的读取速度限制, 主要在 多个文件描述符号的切换上, 也就是在cpu使用率上其次是内存的使用率上。 -> 举个例子, 你的硬盘读写速度很快, 而且在大多数文件的复制粘贴中也确实可以达到这个速度, 但是总有一些文件在复制粘贴时, 速度会降低到 1-2M 甚至 几十kb/s , 就有可能与这个有关(硬盘读取速度不稳定原因: 硬盘本身的硬件问题-> 如老旧硬盘、硬盘坏道、电路版老化、硬盘协议i/o限制; 其他问题 -> 如 cpu使用率过高、 内存使用率过高等。 ), 也就是说, 全都是1k的随便文件, 让你去读, 你的cpu使用率挂满了, 读取速度也达不到i/o瓶颈, 顶多达到 1-2M左右的速度, 别说突破瓶颈了, 此时就算你换了内存挂载盘, 又如何? cpu已经到顶了, 速度已经限制到如此了。
本文针对的主要是第二种情况做验证:
下面是两段个验证代码(第一段性能不如第二段全面, 因此只做第二段的演示):
代码段1->通道多个任务写, 单个任务读:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146package main
import (
"bufio"
"fmt"
"io"
"os"
"path/filepath"
"strconv"
"strings"
"sync"
"time"
"github.com/panjf2000/ants/v2"
)
type text struct {
name string
lines []string
}
type textChan struct {
path string
chText chan *text
}
// 文件读取到内存并返回。
func readFile(p string) *text {
text := new(text)
text.name = strings.Split(p, "/")[len(strings.Split(p, "/"))-1]
file, err := os.Open(p)
if err != nil {
fmt.Println("打开文件失败", err)
return nil
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF { // End Of File
break
} else {
fmt.Println("读文件发生错误", err)
return nil
}
}
text.lines = append(text.lines, line)
}
fmt.Println("我要返回text")
return text
}
func analysis(text_arg *text) {
time.Sleep(20000 * time.Microsecond)
fmt.Println(text_arg.name)
fmt.Println(len(text_arg.lines))
}
func main() {
args := os.Args[1:] // 获取系统变量, 我们注意使用了 测试文件夹路径 、 配置最大线程数的 两个参数
startTime := time.Now() // 获取开始时间, 用于计算任务总耗时
dir := args[0] // "/dev/shm/项目架构文件验证包" // 替换成目标文件夹的路径
files, err := os.ReadDir(dir) // 得到文件夹中所有文件名的列表
if err != nil {
fmt.Println(err)
return
}
paths := []string{}
// 将所有文件夹名列表,组合成所有文件路径列表
for _, file := range files {
path := filepath.Join(dir, file.Name())
paths = append(paths, path)
}
// fmt.Println(paths)
var wg sync.WaitGroup // 用于控制 读取文件到内存作用 的 线程池
var wgCh sync.WaitGroup // 用户控制 解析线程 (这里仅使用了单个线程, 模拟解析处理 , 也可在此个线程中, 再申请一个线程池来使用, 用于解析文件的作用, 此处不演示 )
var wgAnalysis sync.WaitGroup
goNum, _ := strconv.Atoi(args[1]) // 线程池 最大线程数量
// 创建一个自定义配置的线程池
p, _ := ants.NewPoolWithFunc(goNum, func(textChan_arg interface{}) {
fmt.Println("我是一个子线程")
p := textChan_arg.(*textChan).path
ch := textChan_arg.(*textChan).chText
text := readFile(p)
ch <- text
fmt.Println("我要退出子线程")
wg.Done()
})
goNum, _ = strconv.Atoi(args[2])
pAnalysis, _ := ants.NewPoolWithFunc(goNum, func(text_arg interface{}) {
text := text_arg.(*text)
analysis(text)
wgAnalysis.Done()
})
// 通道, 用于读取文件的线程池中的线程, 与 解析文件线程直接的通信
chText := make(chan *text, 10)
// 提前开启接收者线程,避免线程池中 , 用于读取文件的线程 因通道chText阻塞从而导致的线程池死锁(不限制最大线程数的话,不会有线程池死锁现象)
wgCh.Add(1)
go func(ch chan *text, pAnalysis *ants.PoolWithFunc) {
for text_arg := range ch {
wgAnalysis.Add(1)
_ = pAnalysis.Invoke(text_arg)
// analysis(text_arg)
// time.Sleep(2000 * time.Microsecond)
// fmt.Println(text_arg.name)
// fmt.Println(len(text_arg.lines))
}
// 等待所有的解析池中的解析线程退出
wgAnalysis.Wait()
// 全部解析完成
wgCh.Done()
}(chText, pAnalysis)
// 往线程池的任务队列中, 放任务。
for _, path := range paths {
wg.Add(1)
textChan_arg := new(textChan)
textChan_arg.path = path
textChan_arg.chText = chText
_ = p.Invoke(textChan_arg)
// text := readFile(path)
// fmt.Println(text.name)
// fmt.Println(len(text.lines))
// fmt.Println("---------------------")
}
wg.Wait()
fmt.Printf("readFile running goroutines: %d\n", p.Running())
// 所有协程退出后 ,关闭通道
close(chText)
wgCh.Wait()
fmt.Println("我要把通道打印")
println("用时:", time.Since(startTime).Microseconds())
}代码段2->通道多个任务写, 多个任务读:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141package main
import (
"bufio"
"fmt"
"io"
"os"
"path/filepath"
"strconv"
"strings"
"sync"
"time"
"github.com/panjf2000/ants/v2"
)
type text struct {
name string
lines []string
}
type textChan struct {
path string
chText chan *text
}
// 文件读取到内存并返回。
func readFile(p string) *text {
text := new(text)
text.name = strings.Split(p, "/")[len(strings.Split(p, "/"))-1]
file, err := os.Open(p)
if err != nil {
fmt.Println("打开文件失败", err)
return nil
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF { // End Of File
break
} else {
fmt.Println("读文件发生错误", err)
return nil
}
}
text.lines = append(text.lines, line)
}
fmt.Println("我要返回text")
return text
}
func analysis(text_arg *text) {
time.Sleep(20000 * time.Microsecond)
fmt.Println(text_arg.name)
fmt.Println(len(text_arg.lines))
}
func main() {
args := os.Args[1:] // 获取系统变量, 我们注意使用了 测试文件夹路径 、 配置最大线程数的 两个参数
startTime := time.Now() // 获取开始时间, 用于计算任务总耗时
dir := args[0] // "/dev/shm/项目架构文件验证包" // 替换成目标文件夹的路径
files, err := os.ReadDir(dir) // 得到文件夹中所有文件名的列表
if err != nil {
fmt.Println(err)
return
}
paths := []string{}
// 将所有文件夹名列表,组合成所有文件路径列表
for _, file := range files {
path := filepath.Join(dir, file.Name())
paths = append(paths, path)
}
// fmt.Println(paths)
var wg sync.WaitGroup // 用于控制 读取文件到内存作用 的 线程池
var wgAnalysis sync.WaitGroup
goNum, _ := strconv.Atoi(args[1]) // 线程池 最大线程数量
// 创建一个自定义配置的线程池
p, _ := ants.NewPoolWithFunc(goNum, func(textChan_arg interface{}) {
fmt.Println("我是一个子线程")
p := textChan_arg.(*textChan).path
ch := textChan_arg.(*textChan).chText
text := readFile(p)
ch <- text
fmt.Println("我要退出子线程")
wg.Done()
})
goNum, _ = strconv.Atoi(args[2])
pAnalysis, _ := ants.NewPoolWithFunc(goNum, func(ch interface{}) {
for text := range ch.(chan *text) {
analysis(text)
}
wgAnalysis.Done()
})
// 通道, 用于读取文件的线程池中的线程, 与 解析文件线程直接的通信
chText := make(chan *text, 10)
// 提前开启接收者线程,避免线程池中 , 用于读取文件的线程 因通道chText阻塞从而导致的线程池死锁(不限制最大线程数的话,不会有线程池死锁现象)
for i:=0 ; i<goNum; i++ {
wgAnalysis.Add(1)
_ = pAnalysis.Invoke(chText)
// analysis(text_arg)
// time.Sleep(2000 * time.Microsecond)
// fmt.Println(text_arg.name)
// fmt.Println(len(text_arg.lines))
}
// 全部解析完成
// 往线程池的任务队列中, 放任务。
for _, path := range paths {
wg.Add(1)
textChan_arg := new(textChan)
textChan_arg.path = path
textChan_arg.chText = chText
_ = p.Invoke(textChan_arg)
// text := readFile(path)
// fmt.Println(text.name)
// fmt.Println(len(text.lines))
// fmt.Println("---------------------")
}
wg.Wait()
fmt.Printf("readFile running goroutines: %d\n", p.Running())
// 所有协程退出后 ,关闭通道
close(chText)
// 等待所有的解析池中的解析线程退出
wgAnalysis.Wait()
fmt.Println("我要把通道打印")
println("用时:", time.Since(startTime).Microseconds())
}代码段3->利用sync.Pool对象池, 复用对象:
sync.Pool 主要用于复用内存占用大的对象, 因为这类对象的 内存申请 , 以及内存回收(GC) 都是比较耗时的, 因此复用可以大大提高效率。 如您还不了解sync.Pool, 可以移步这篇文章Go临时对象池pool(1.13后的版本), 并且这篇文章中, 有个更为简单易理解的用例可以证明这一点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149package main
import (
"bufio"
"fmt"
"io"
"os"
"path/filepath"
"strconv"
"strings"
"sync"
"time"
"github.com/panjf2000/ants/v2"
)
type text struct {
name string
lines []string
}
type textChan struct {
path string
chText chan *text
}
var textPool = sync.Pool{
New: func() interface{} {
return new(text)
},
}
// 文件读取到内存并返回。
func readFile(p string) *text {
text := textPool.Get().(*text)
text.name = strings.Split(p, "/")[len(strings.Split(p, "/"))-1]
file, err := os.Open(p)
if err != nil {
fmt.Println("打开文件失败", err)
return nil
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF { // End Of File
break
} else {
fmt.Println("读文件发生错误", err)
return nil
}
}
text.lines = append(text.lines, line)
}
fmt.Println("我要返回text")
return text
}
func analysis(text_arg *text) {
time.Sleep(20000 * time.Microsecond)
fmt.Println(text_arg.name)
fmt.Println(len(text_arg.lines))
text_arg.lines = text_arg.lines[:0]
textPool.Put(text_arg)
}
func main() {
args := os.Args[1:] // 获取系统变量, 我们注意使用了 测试文件夹路径 、 配置最大线程数的 两个参数
startTime := time.Now() // 获取开始时间, 用于计算任务总耗时
dir := args[0] // "/dev/shm/项目架构文件验证包" // 替换成目标文件夹的路径
files, err := os.ReadDir(dir) // 得到文件夹中所有文件名的列表
if err != nil {
fmt.Println(err)
return
}
paths := []string{}
// 将所有文件夹名列表,组合成所有文件路径列表
for _, file := range files {
path := filepath.Join(dir, file.Name())
paths = append(paths, path)
}
// fmt.Println(paths)
var wg sync.WaitGroup // 用于控制 读取文件到内存作用 的 线程池
var wgAnalysis sync.WaitGroup
goNum, _ := strconv.Atoi(args[1]) // 线程池 最大线程数量
// 创建一个自定义配置的线程池
p, _ := ants.NewPoolWithFunc(goNum, func(textChan_arg interface{}) {
fmt.Println("我是一个子线程")
p := textChan_arg.(*textChan).path
ch := textChan_arg.(*textChan).chText
text := readFile(p)
ch <- text
fmt.Println("我要退出子线程")
wg.Done()
})
goNum, _ = strconv.Atoi(args[2])
pAnalysis, _ := ants.NewPoolWithFunc(goNum, func(ch interface{}) {
for text := range ch.(chan *text) {
analysis(text)
}
wgAnalysis.Done()
})
// 通道, 用于读取文件的线程池中的线程, 与 解析文件线程直接的通信
chText := make(chan *text, 10)
// 提前开启接收者线程,避免线程池中 , 用于读取文件的线程 因通道chText阻塞从而导致的线程池死锁(不限制最大线程数的话,不会有线程池死锁现象)
for i := 0; i < goNum; i++ {
wgAnalysis.Add(1)
_ = pAnalysis.Invoke(chText)
// analysis(text_arg)
// time.Sleep(2000 * time.Microsecond)
// fmt.Println(text_arg.name)
// fmt.Println(len(text_arg.lines))
}
// 全部解析完成
// 往线程池的任务队列中, 放任务。
for _, path := range paths {
wg.Add(1)
textChan_arg := new(textChan)
textChan_arg.path = path
textChan_arg.chText = chText
_ = p.Invoke(textChan_arg)
// text := readFile(path)
// fmt.Println(text.name)
// fmt.Println(len(text.lines))
// fmt.Println("---------------------")
}
wg.Wait()
fmt.Printf("readFile running goroutines: %d\n", p.Running())
// 所有协程退出后 ,关闭通道
close(chText)
// 等待所有的解析池中的解析线程退出
wgAnalysis.Wait()
fmt.Println("我要把通道打印")
println("用时:", time.Since(startTime).Microseconds())
}代码段4->主要为了更直观的说明, 对于非大内存占用的对象, 引入sync.Pool是在做无用功。(给另一篇文章提供下实例哈哈)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159package main
import (
"bufio"
"fmt"
"io"
"os"
"path/filepath"
"strconv"
"strings"
"sync"
"time"
"github.com/panjf2000/ants/v2"
)
type text struct {
name string
lines []string
}
type textChan struct {
path string
chText chan *text
}
var textPool = sync.Pool{
New: func() interface{} {
return new(text)
},
}
var textChanPool = sync.Pool{
New: func() interface{} {
return new(textChan)
},
}
// 文件读取到内存并返回。
func readFile(p string) *text {
text := textPool.Get().(*text)
text.name = strings.Split(p, "/")[len(strings.Split(p, "/"))-1]
file, err := os.Open(p)
if err != nil {
fmt.Println("打开文件失败", err)
return nil
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF { // End Of File
break
} else {
fmt.Println("读文件发生错误", err)
return nil
}
}
text.lines = append(text.lines, line)
}
fmt.Println("我要返回text")
return text
}
func analysis(text_arg *text) {
time.Sleep(20000 * time.Microsecond)
fmt.Println(text_arg.name)
fmt.Println(len(text_arg.lines))
text_arg.lines = text_arg.lines[:0]
textPool.Put(text_arg)
}
func main() {
args := os.Args[1:] // 获取系统变量, 我们注意使用了 测试文件夹路径 、 配置最大线程数的 两个参数
startTime := time.Now() // 获取开始时间, 用于计算任务总耗时
dir := args[0] // "/dev/shm/项目架构文件验证包" // 替换成目标文件夹的路径
files, err := os.ReadDir(dir) // 得到文件夹中所有文件名的列表
if err != nil {
fmt.Println(err)
return
}
paths := []string{}
// 将所有文件夹名列表,组合成所有文件路径列表
for _, file := range files {
path := filepath.Join(dir, file.Name())
paths = append(paths, path)
}
// fmt.Println(paths)
var wg sync.WaitGroup // 用于控制 读取文件到内存作用 的 线程池
var wgAnalysis sync.WaitGroup
goNum, _ := strconv.Atoi(args[1]) // 线程池 最大线程数量
// 创建一个自定义配置的线程池
p, _ := ants.NewPoolWithFunc(goNum, func(textChan_arg interface{}) {
fmt.Println("我是一个子线程")
p := textChan_arg.(*textChan).path
ch := textChan_arg.(*textChan).chText
// 它的周期到此为止就结束了
textChanPool.Put(textChan_arg)
text := readFile(p)
ch <- text
fmt.Println("我要退出子线程")
wg.Done()
})
goNum, _ = strconv.Atoi(args[2])
pAnalysis, _ := ants.NewPoolWithFunc(goNum, func(ch interface{}) {
for text := range ch.(chan *text) {
analysis(text)
}
wgAnalysis.Done()
})
// 通道, 用于读取文件的线程池中的线程, 与 解析文件线程直接的通信
chText := make(chan *text, 10)
// 提前开启接收者线程,避免线程池中 , 用于读取文件的线程 因通道chText阻塞从而导致的线程池死锁(不限制最大线程数的话,不会有线程池死锁现象)
for i := 0; i < goNum; i++ {
wgAnalysis.Add(1)
_ = pAnalysis.Invoke(chText)
// analysis(text_arg)
// time.Sleep(2000 * time.Microsecond)
// fmt.Println(text_arg.name)
// fmt.Println(len(text_arg.lines))
}
// 全部解析完成
// 往线程池的任务队列中, 放任务。
for _, path := range paths {
wg.Add(1)
textChan_arg := textChanPool.Get().(* textChan)
textChan_arg.path = path
if textChan_arg.chText == nil {
textChan_arg.chText = chText
}
_ = p.Invoke(textChan_arg)
// text := readFile(path)
// fmt.Println(text.name)
// fmt.Println(len(text.lines))
// fmt.Println("---------------------")
}
wg.Wait()
fmt.Printf("readFile running goroutines: %d\n", p.Running())
// 所有协程退出后 ,关闭通道
close(chText)
// 等待所有的解析池中的解析线程退出
wgAnalysis.Wait()
fmt.Println("我要把通道打印")
println("用时:", time.Since(startTime).Microseconds())
}
实验
为保证本节的所有实验结果数据的可靠与真实性。 所有数据对应的实验过程, 皆可在下节内容中检索到。
- 代码段2 对于编译后的可执行文件名 -> 文件验证处理
- 代码段3 对于编译后的可执行文件名 -> pool文件验证处理
- 代码段4 对于编译后的可执行文件名 -> poolpool文件验证处理
基于代码段2的实验
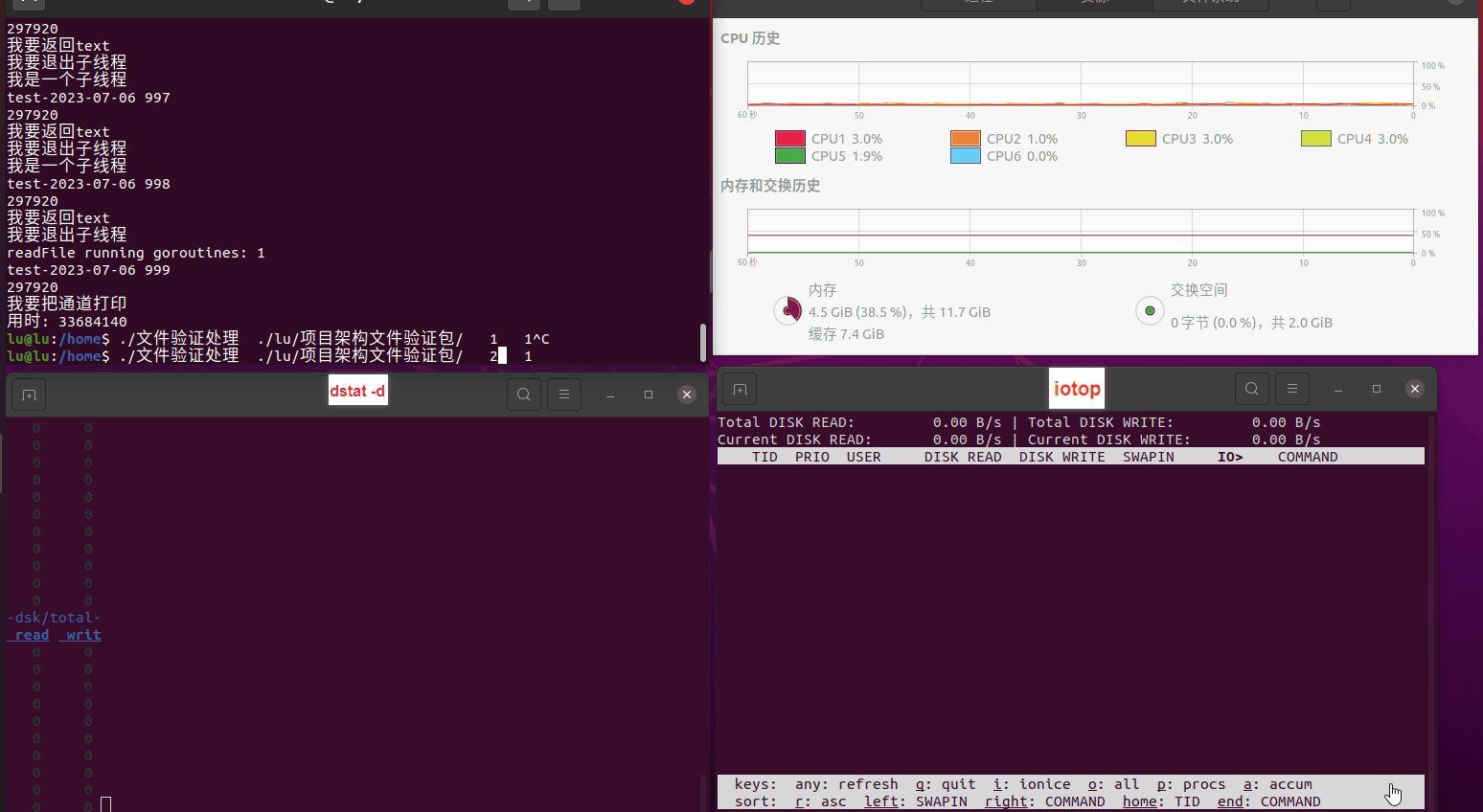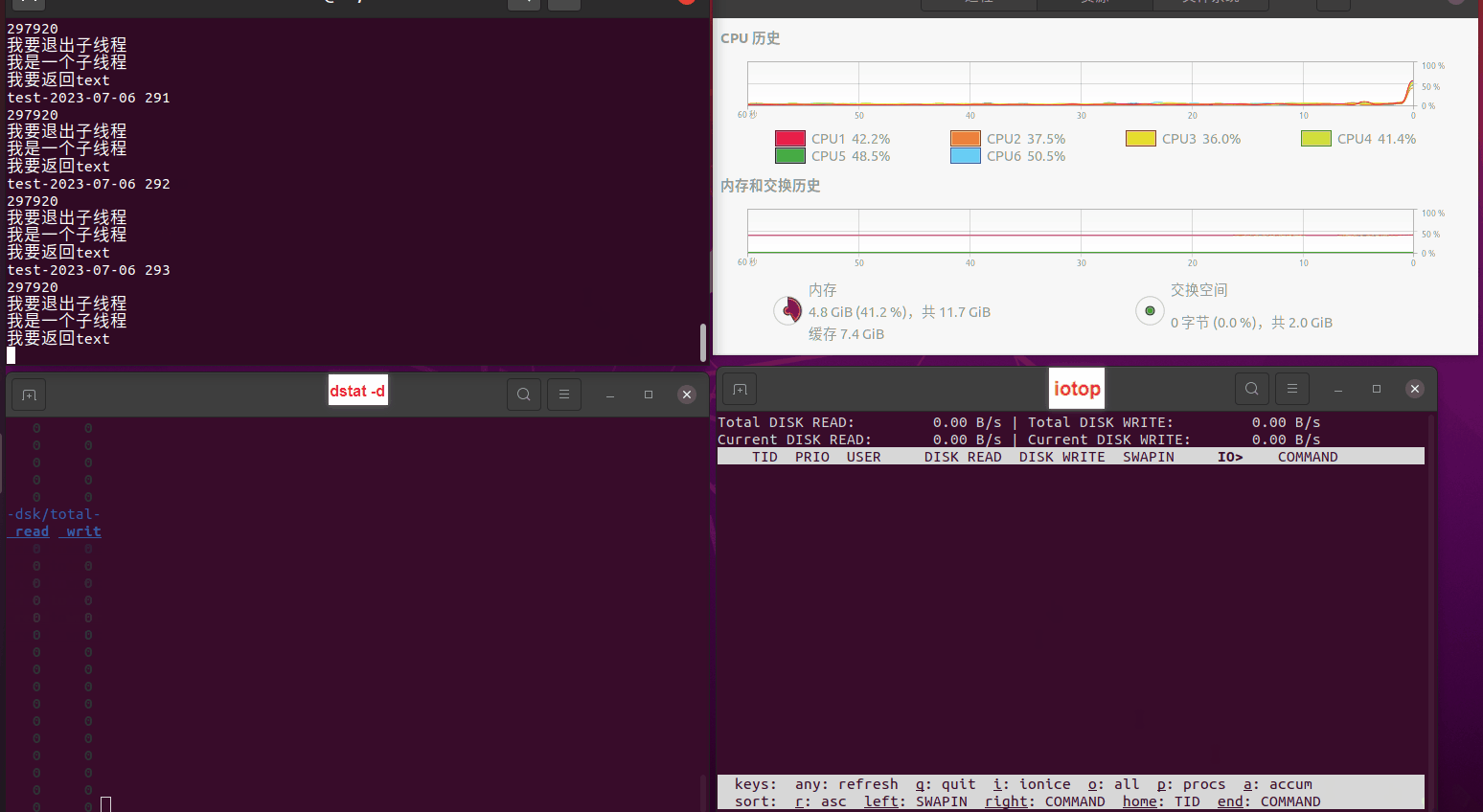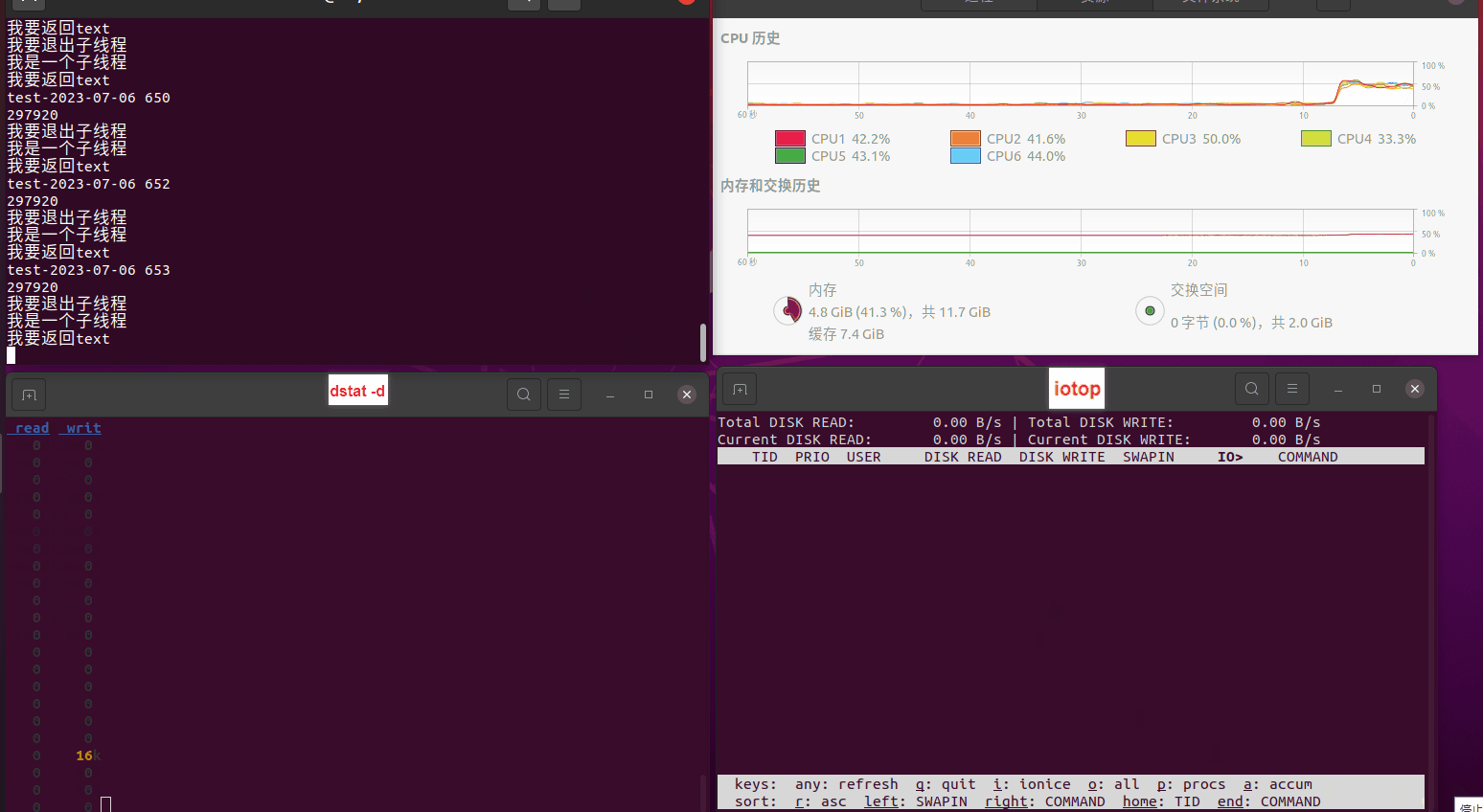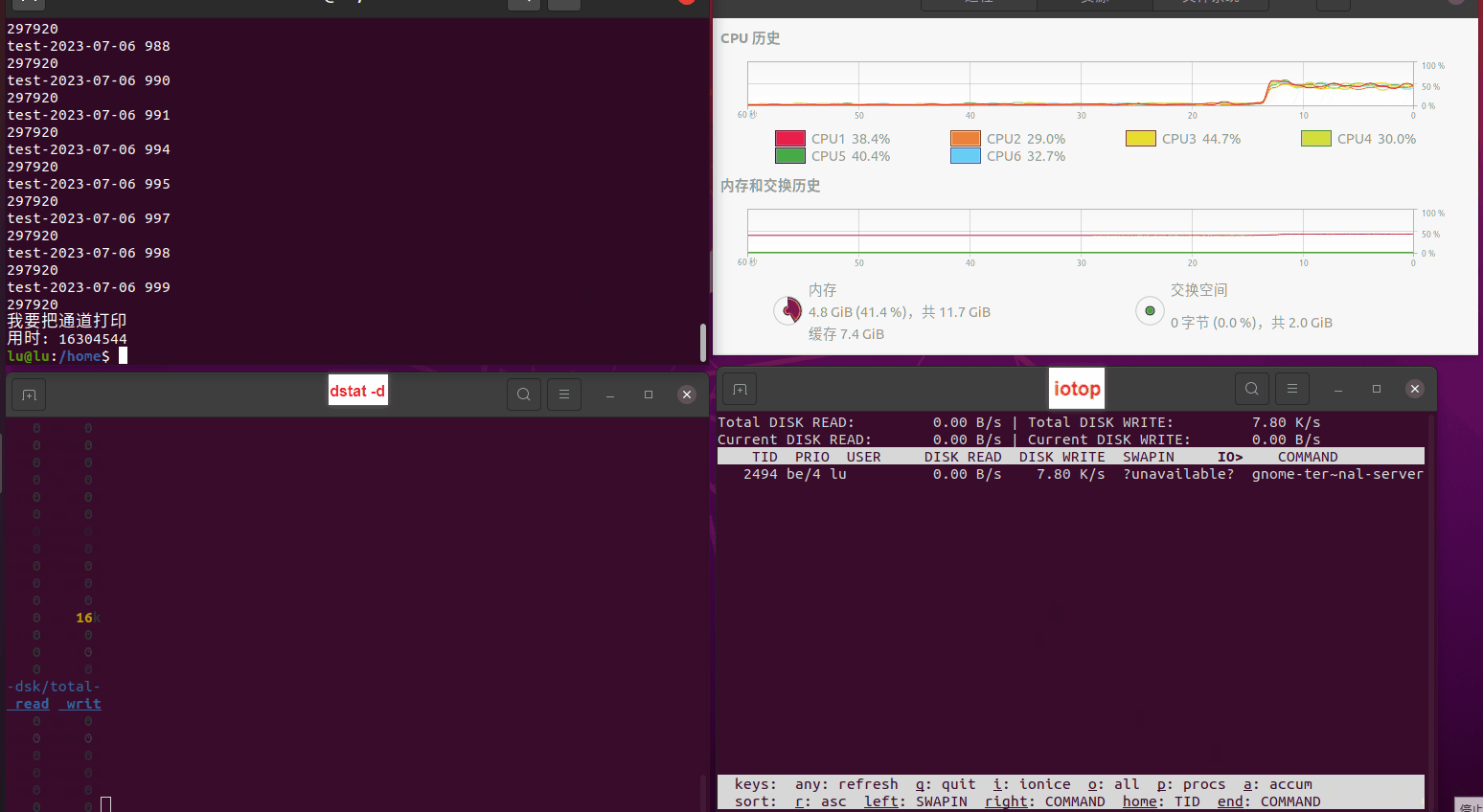
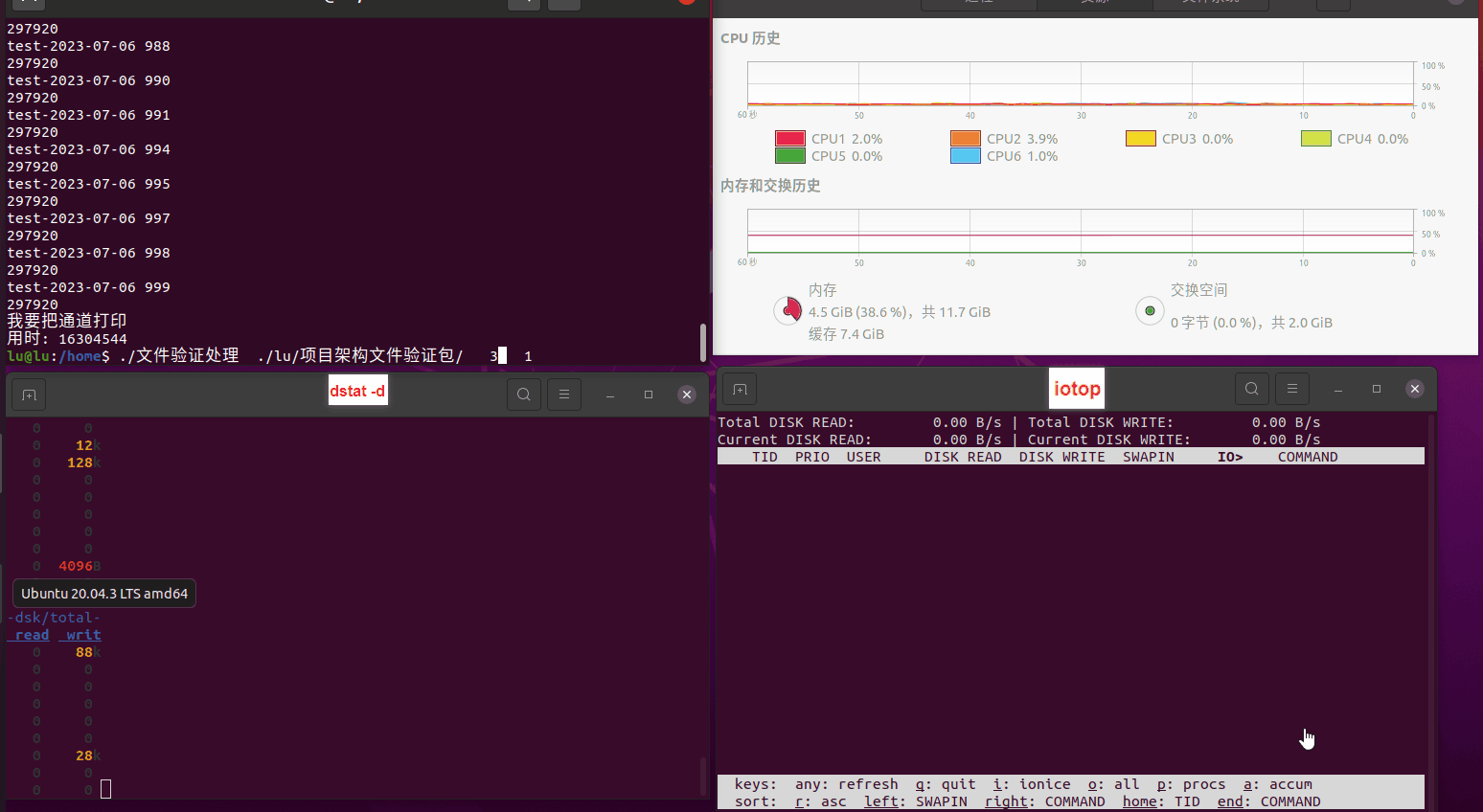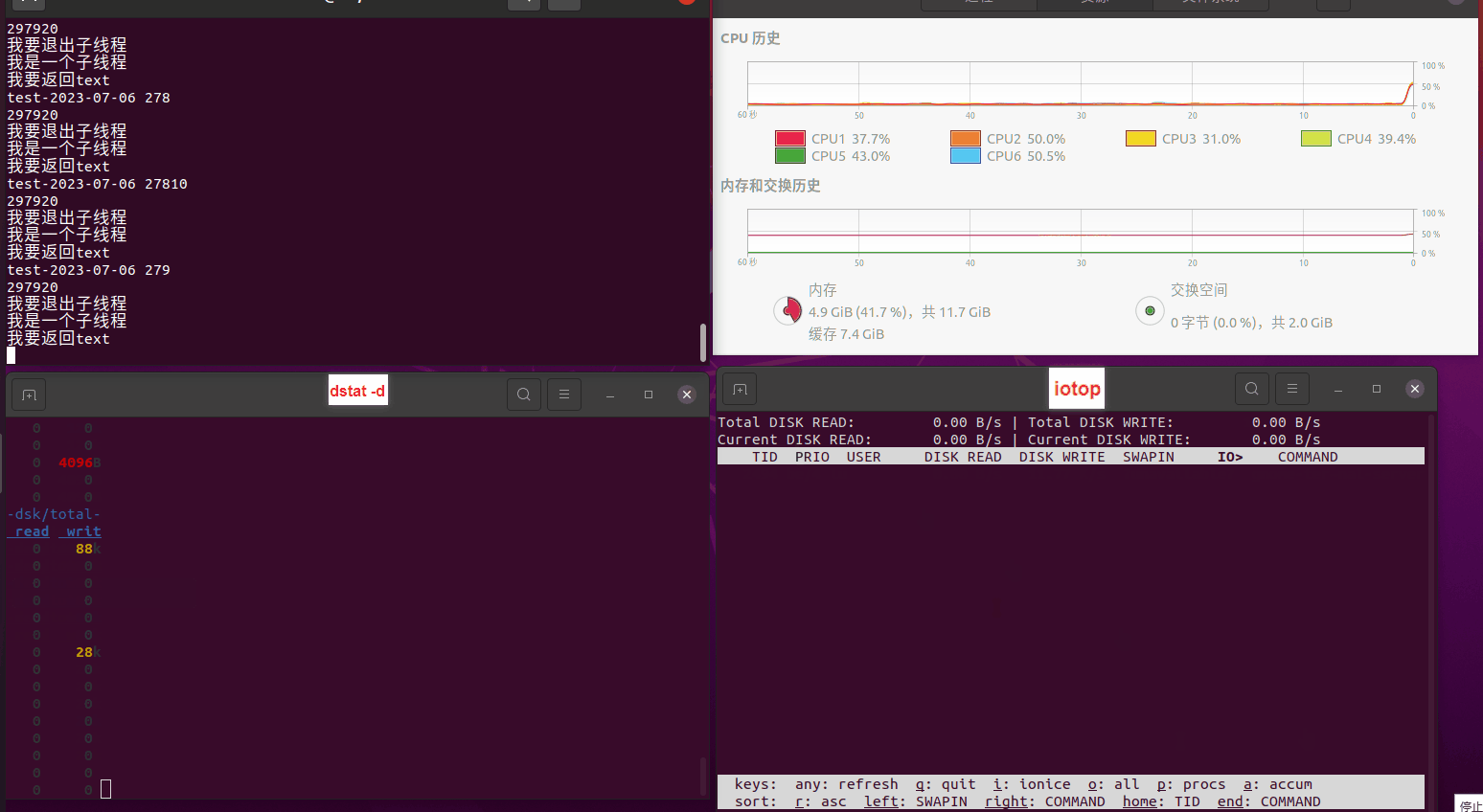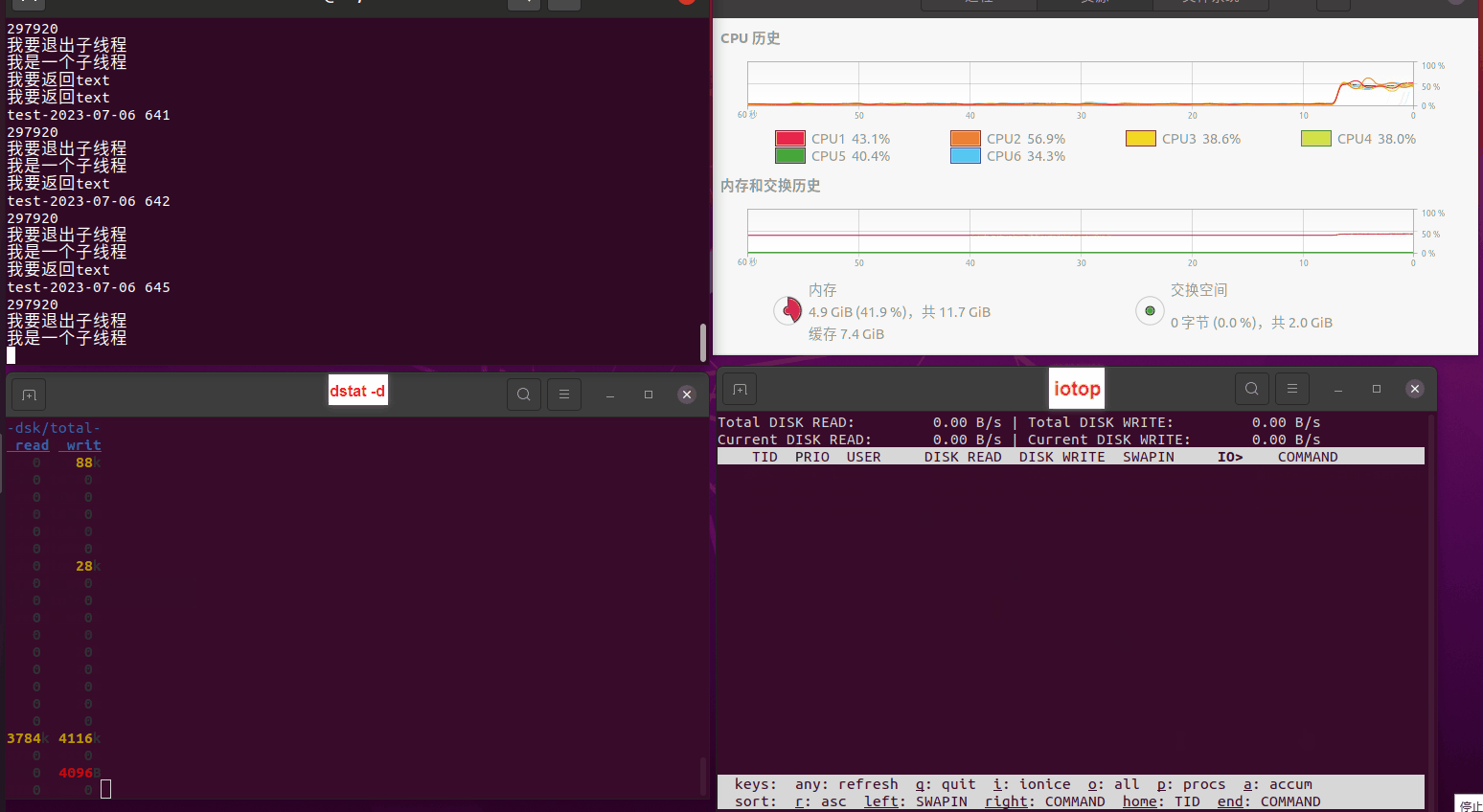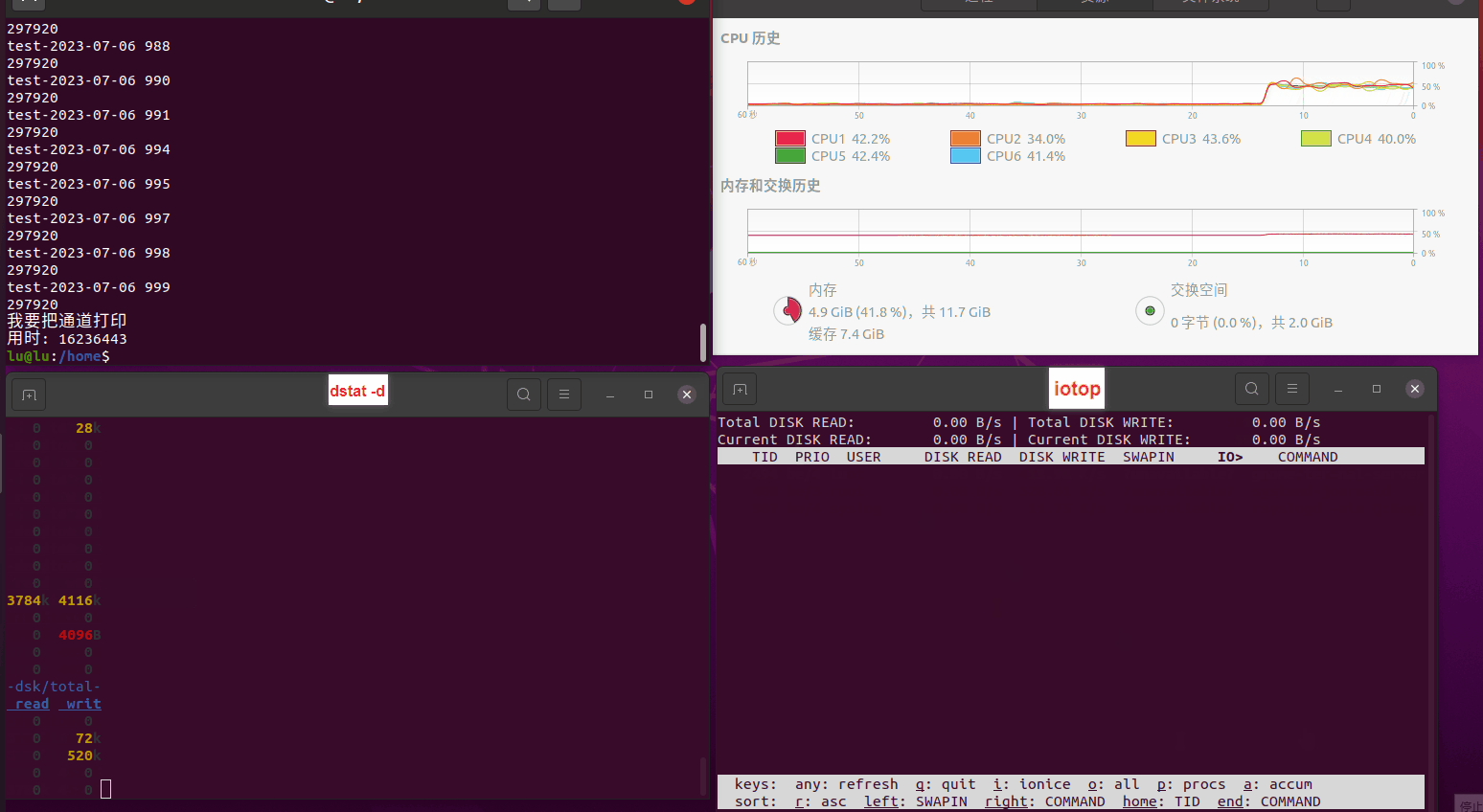
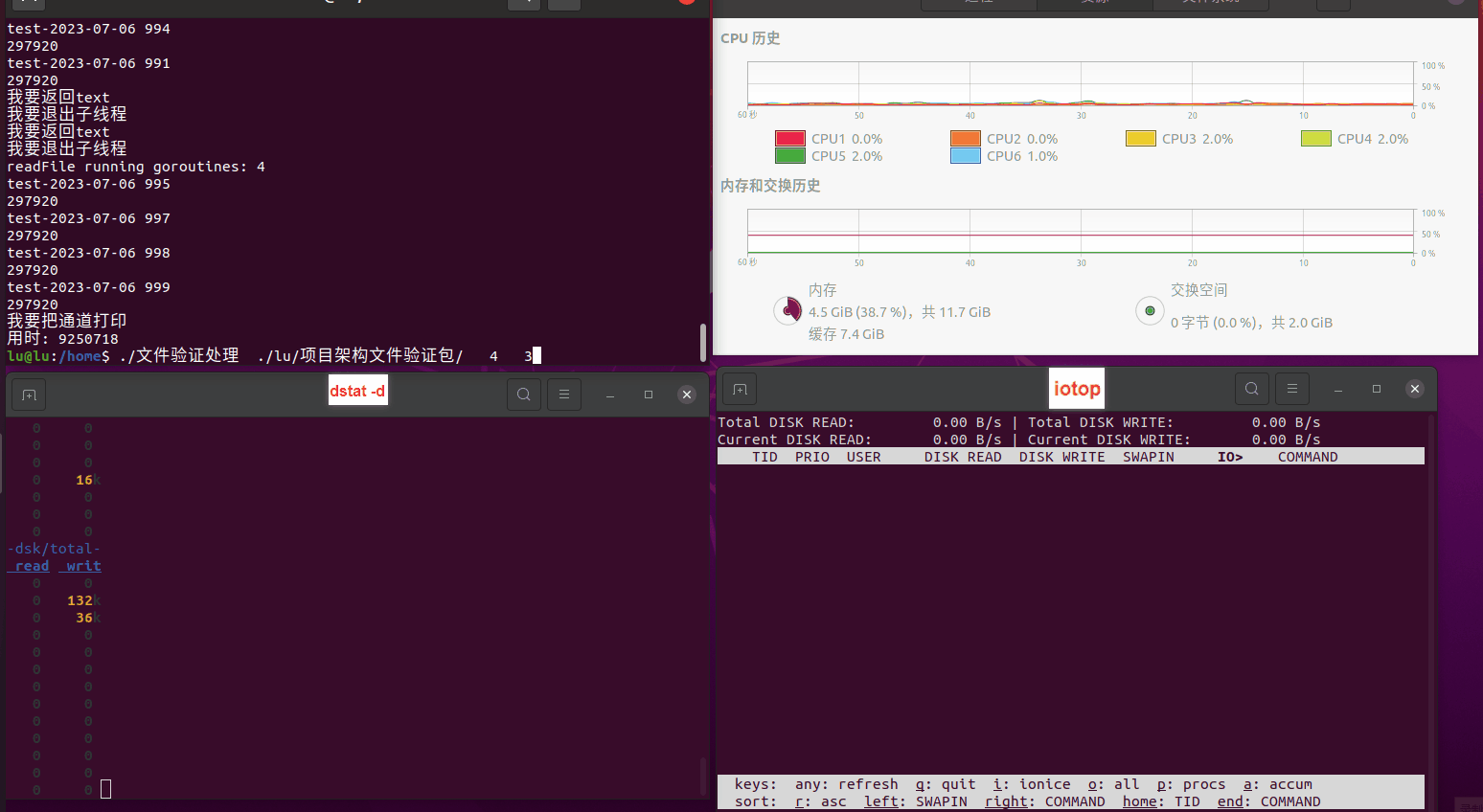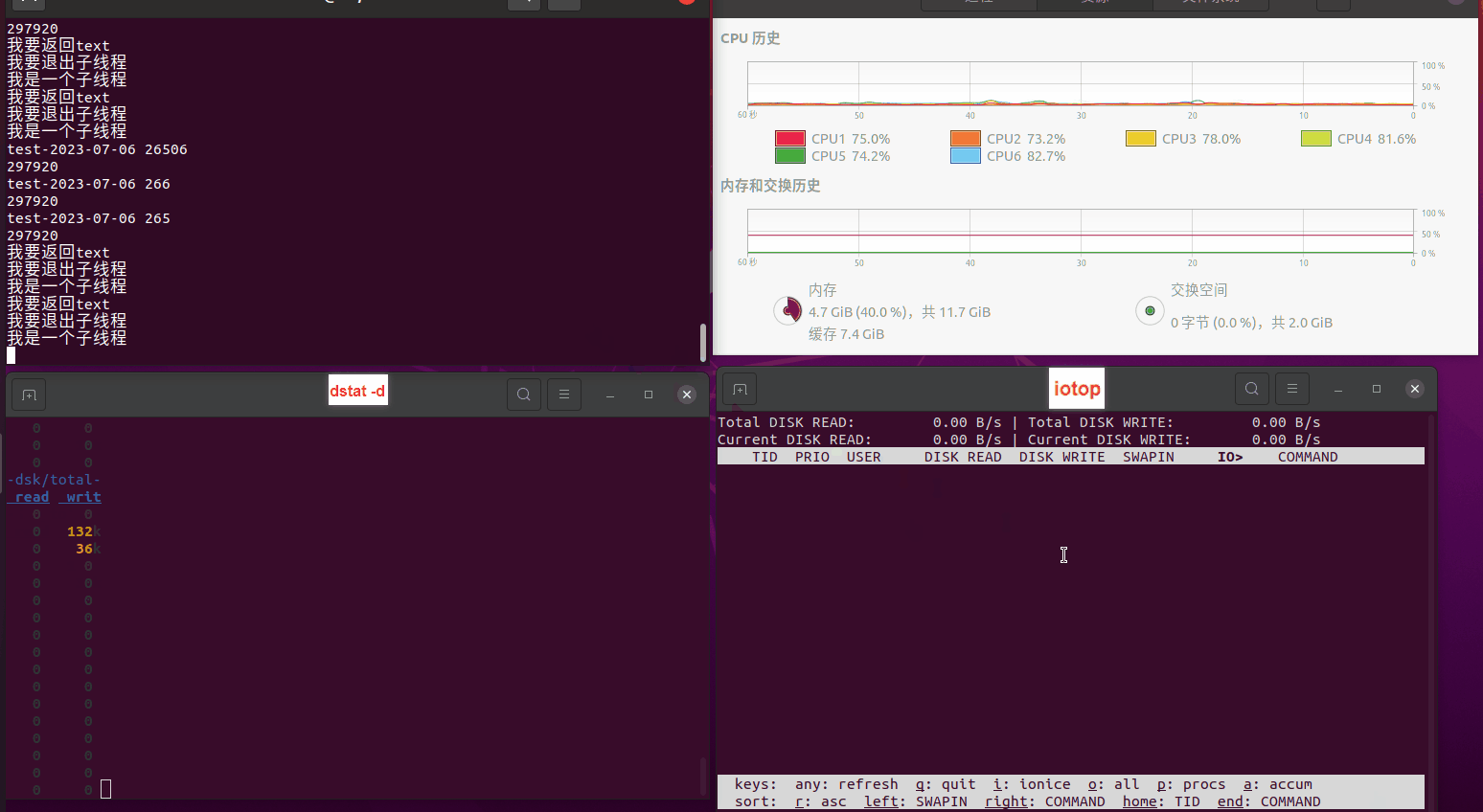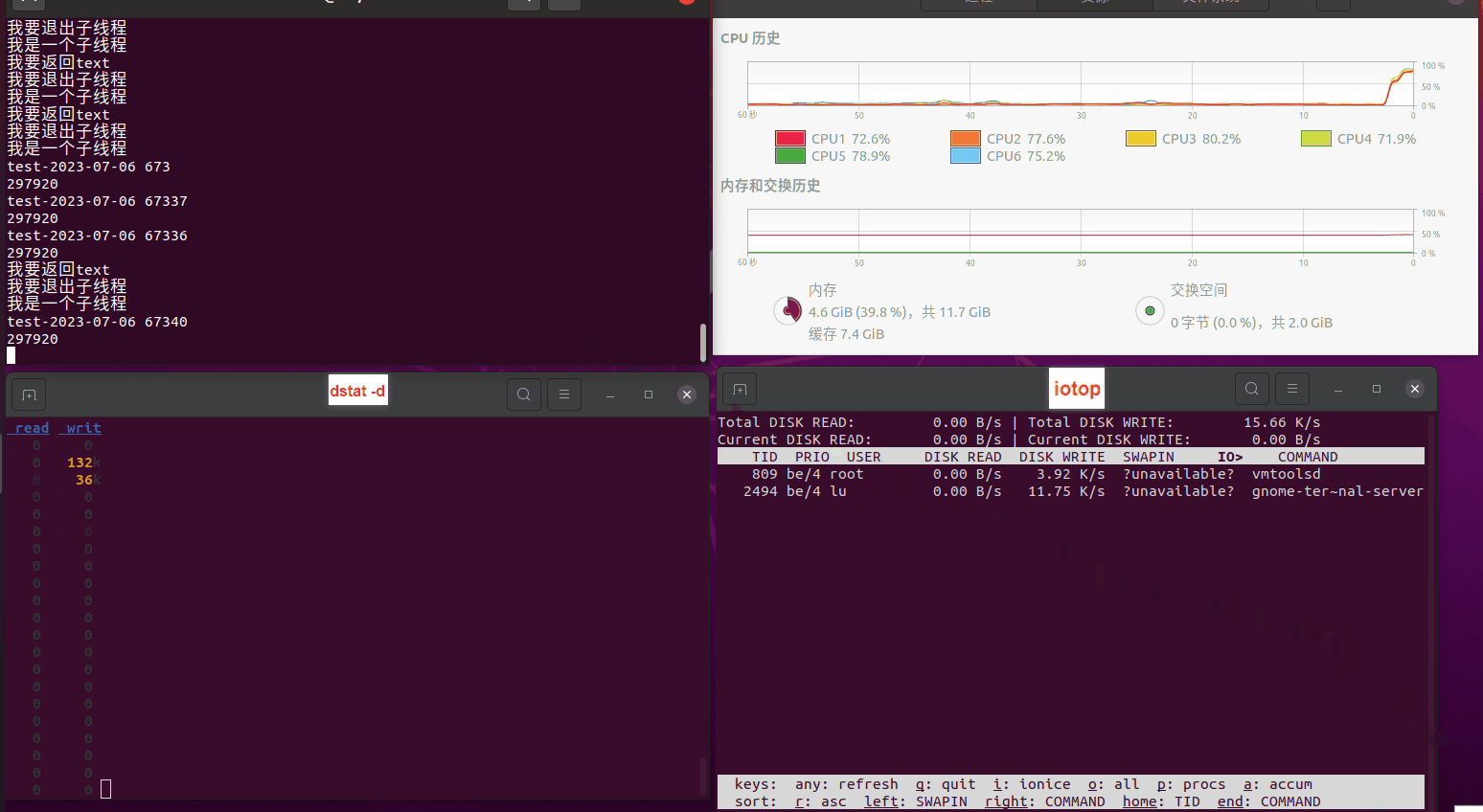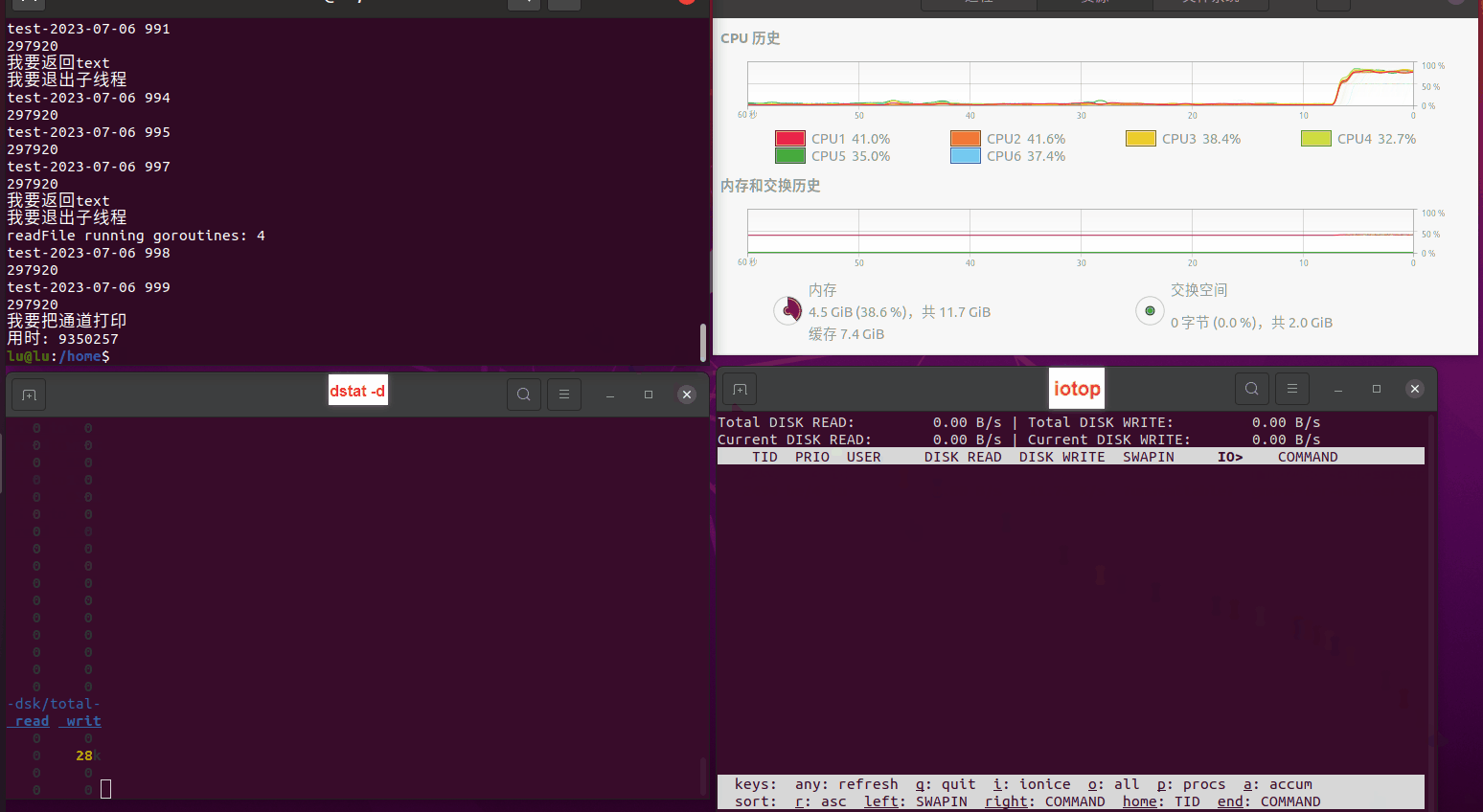
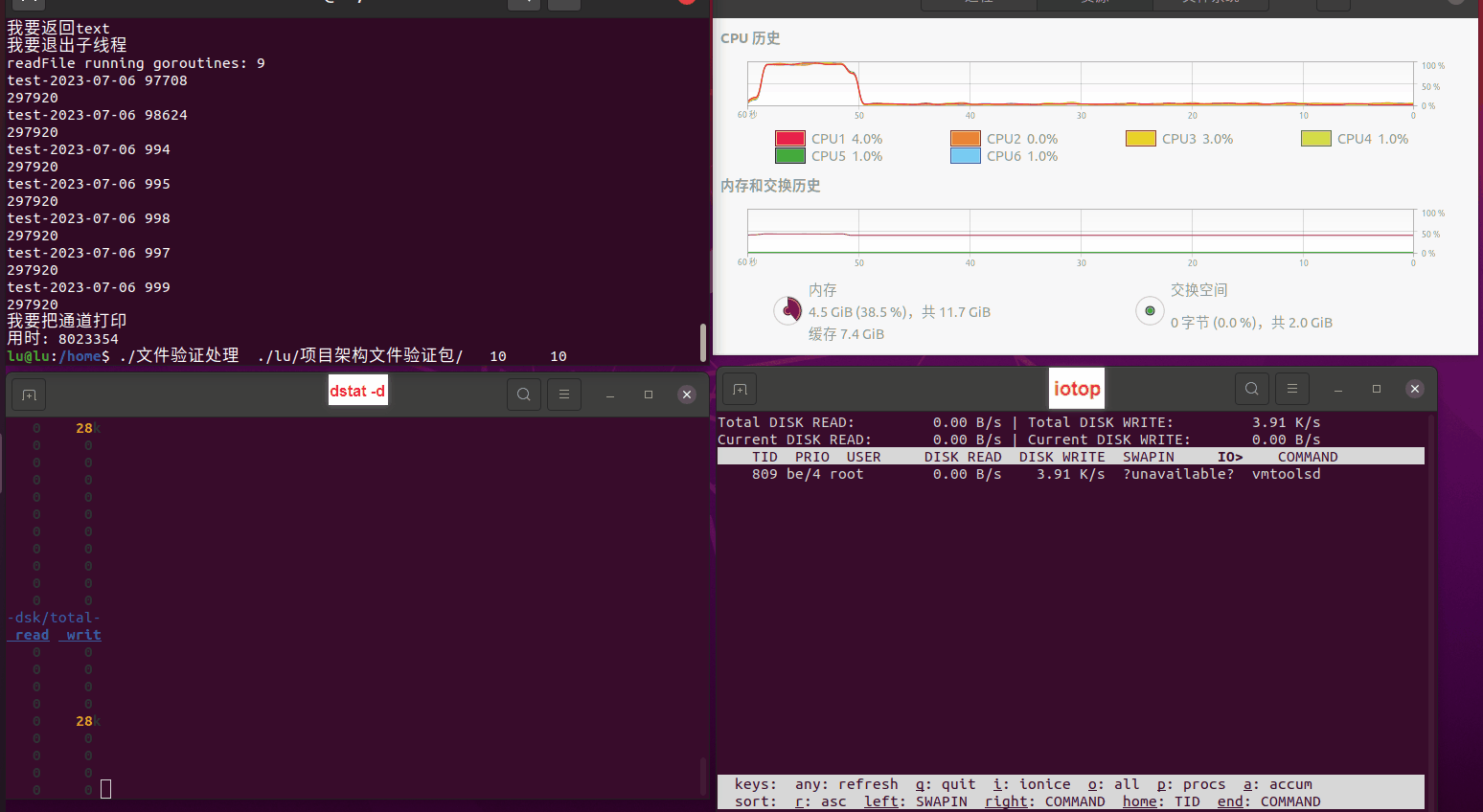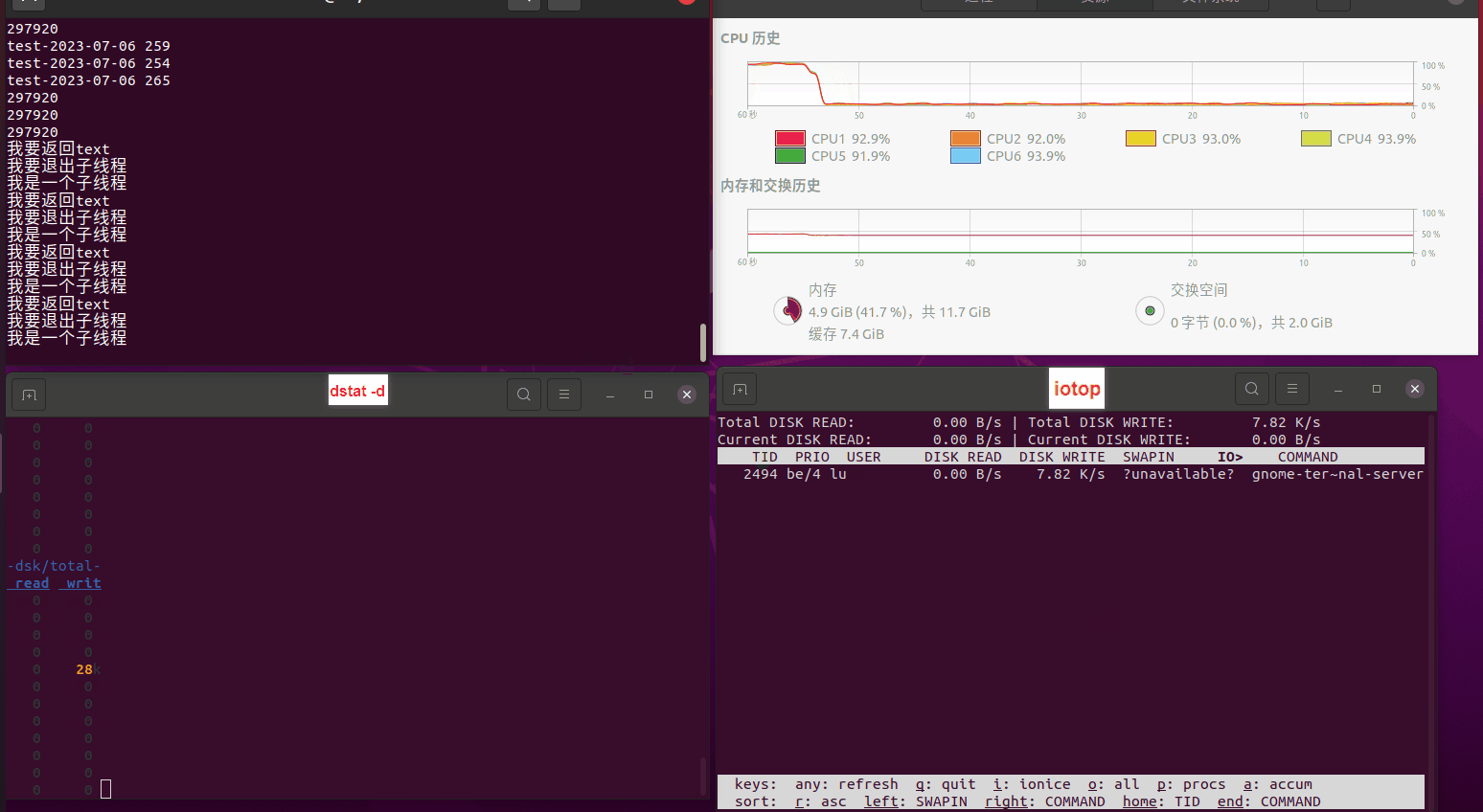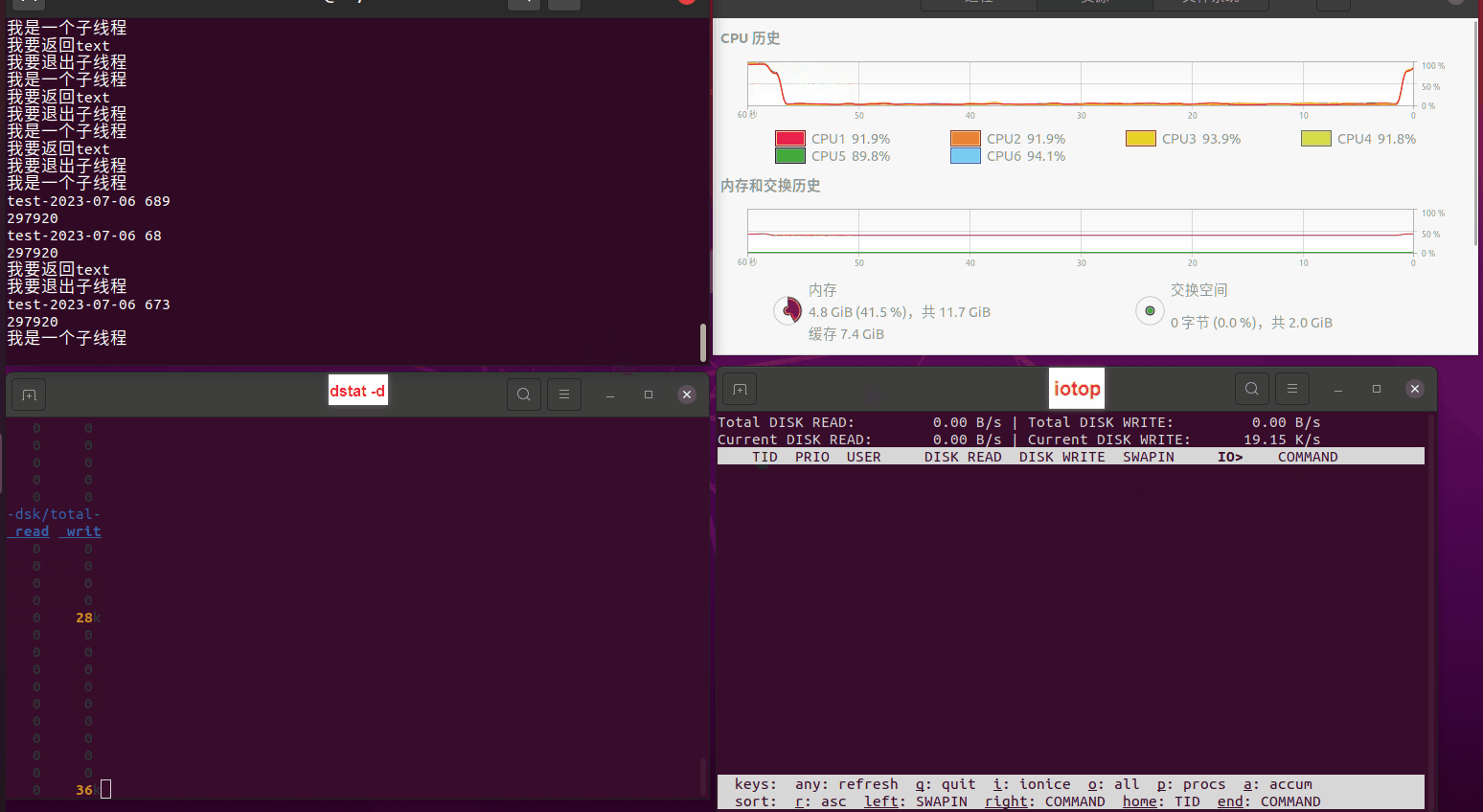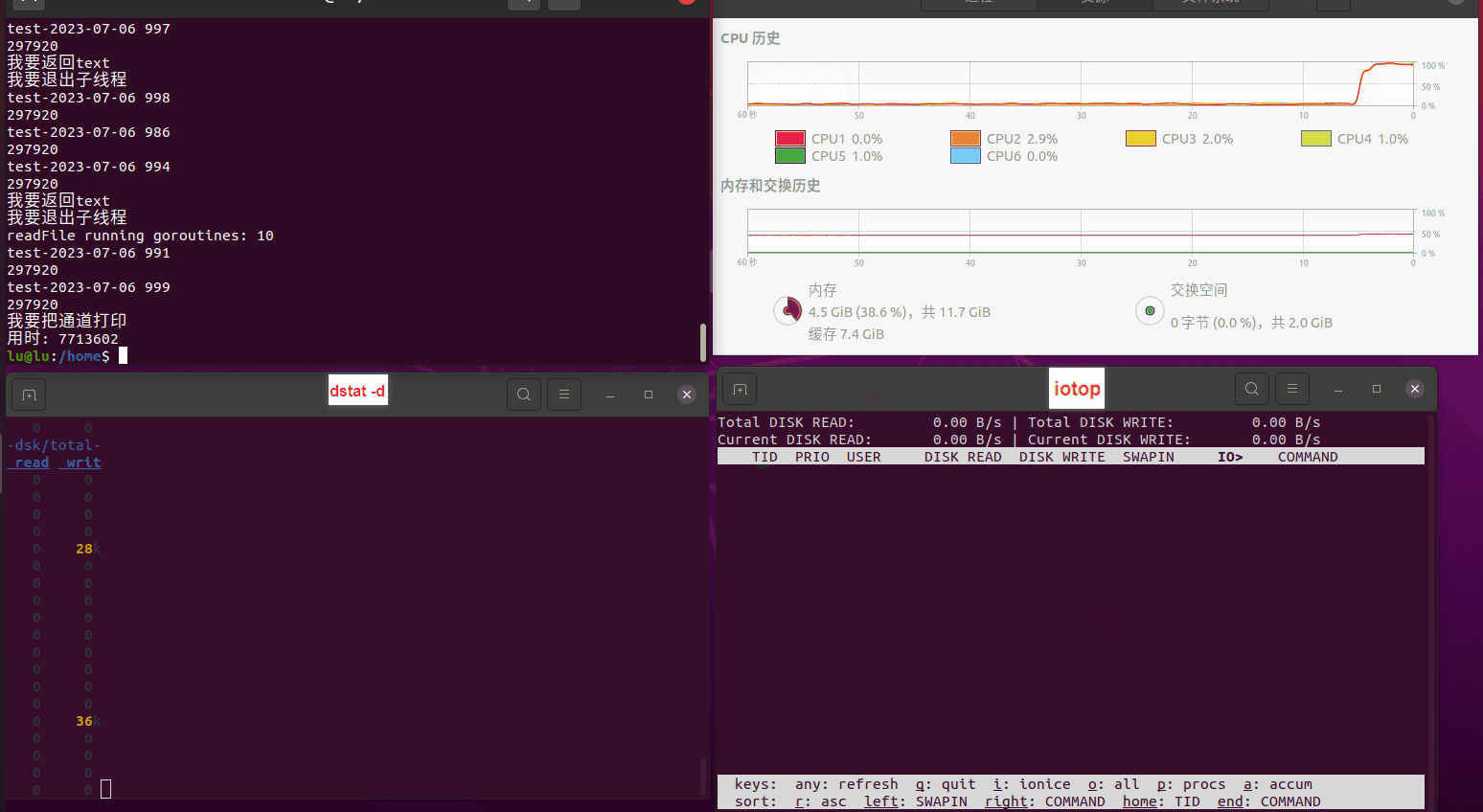
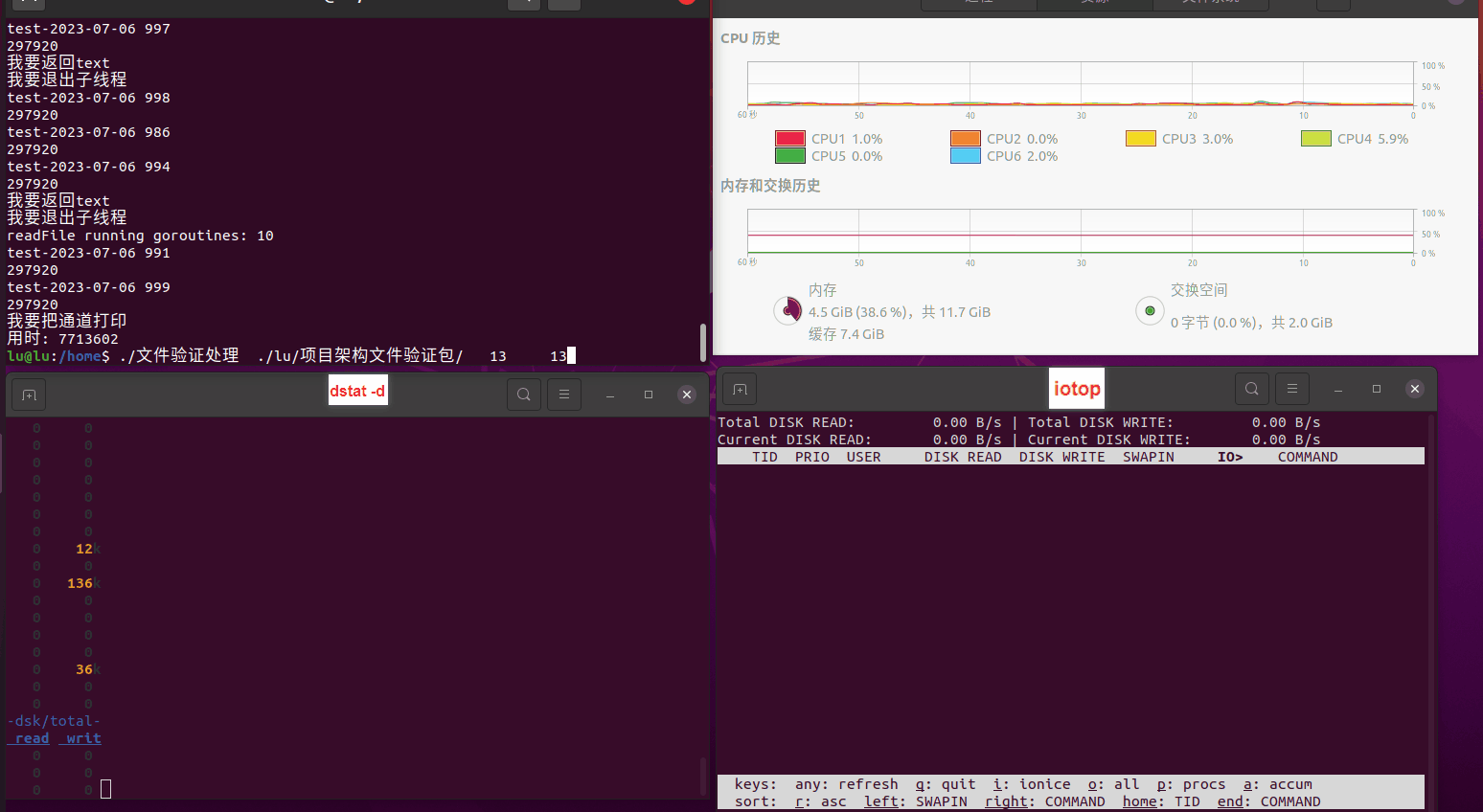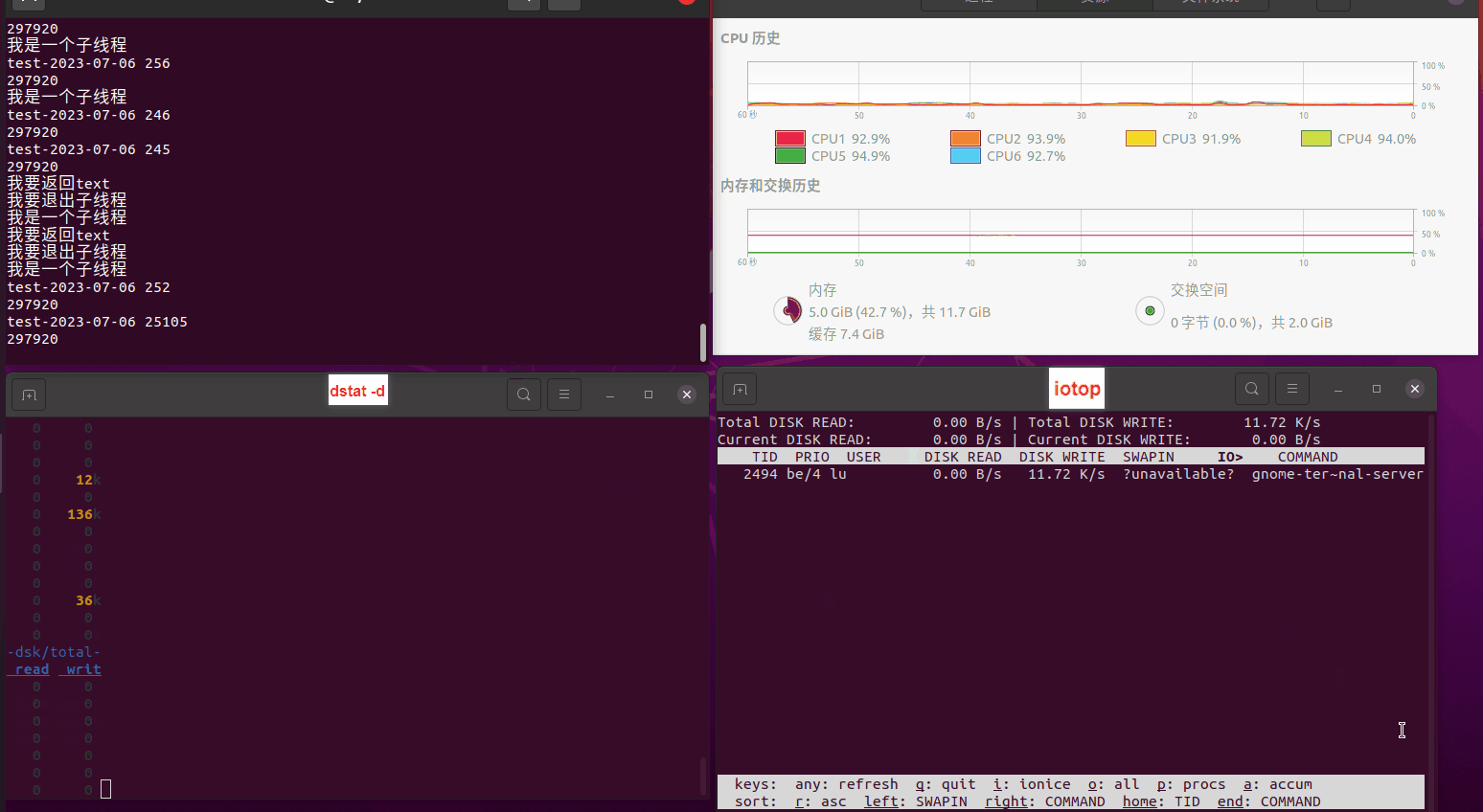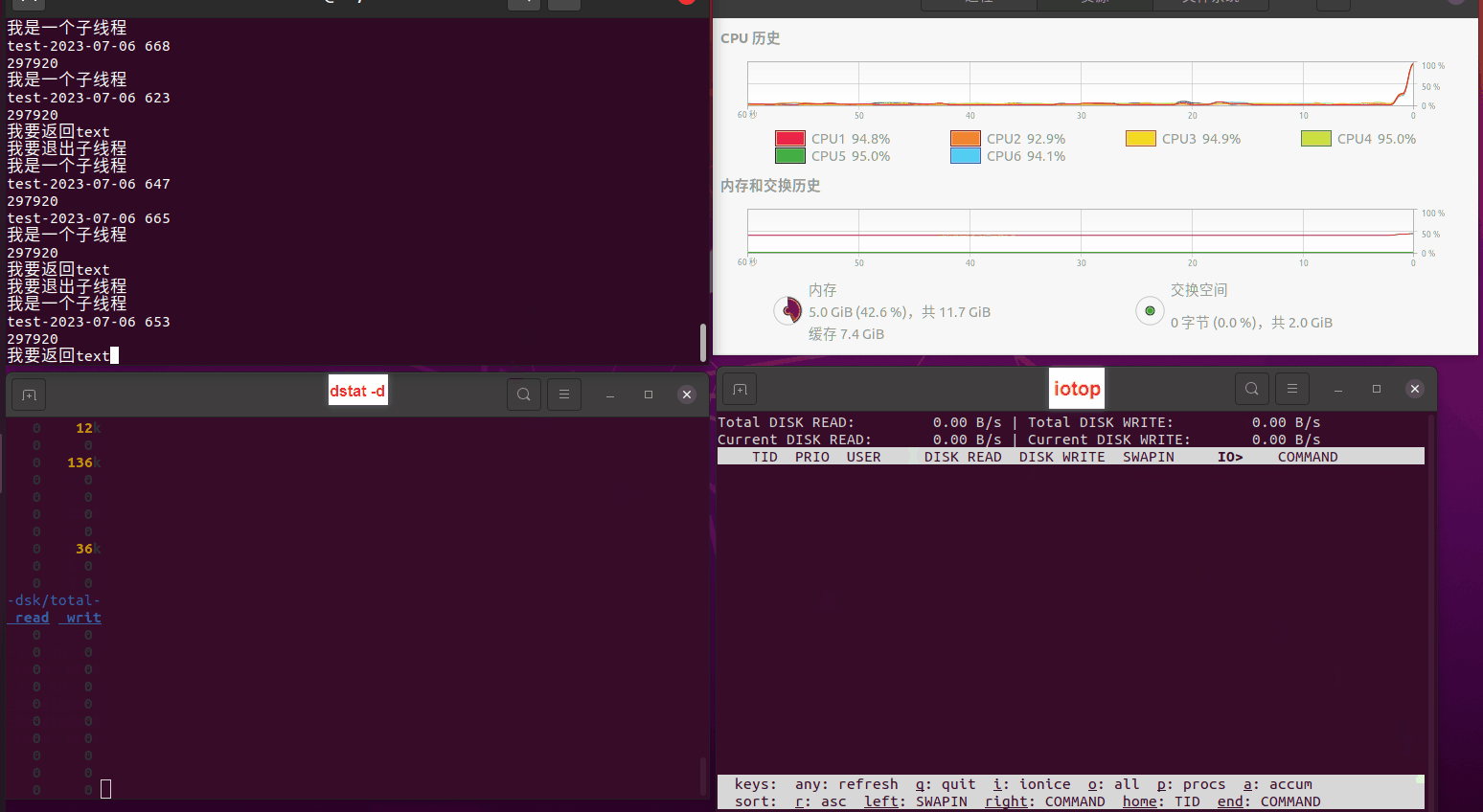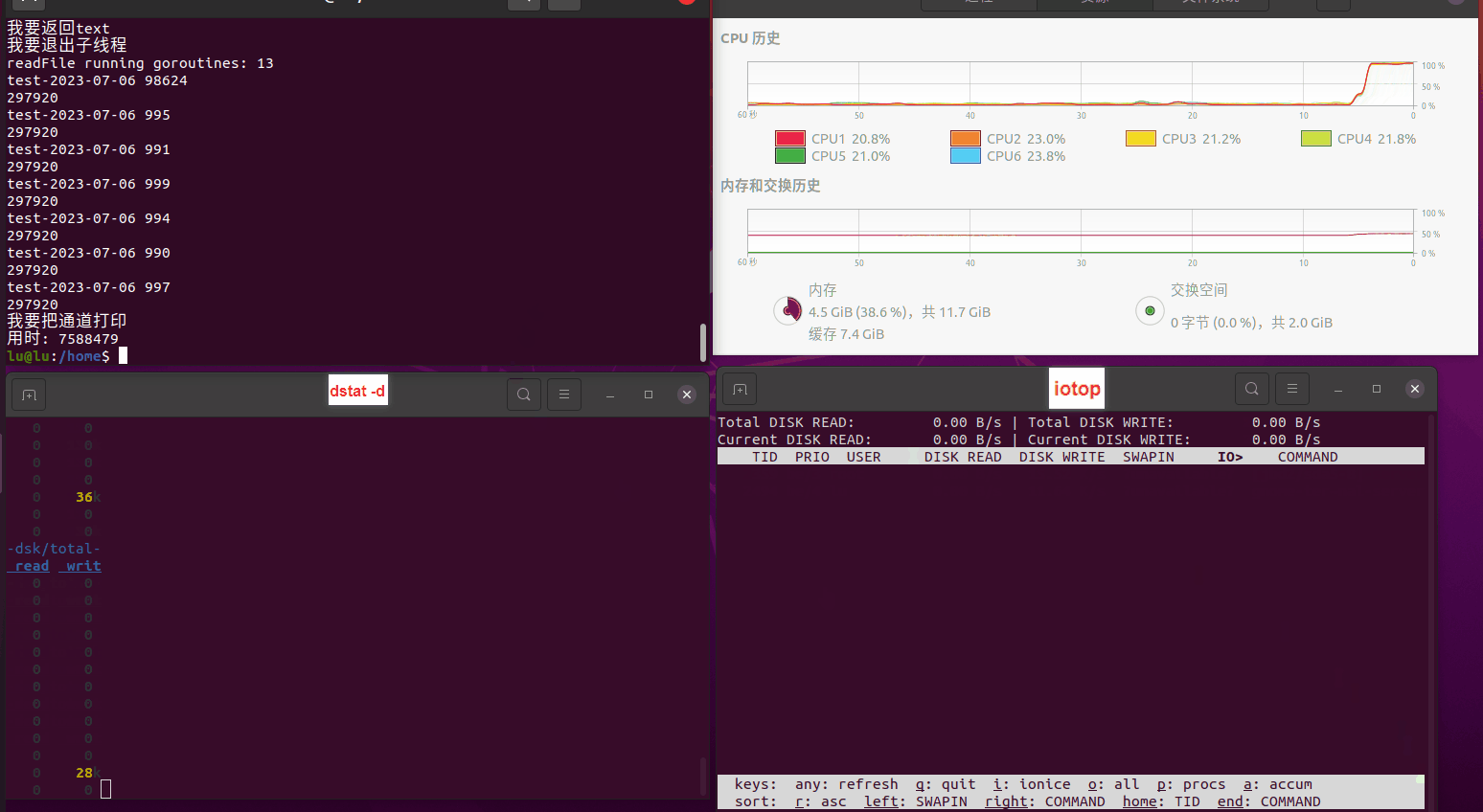
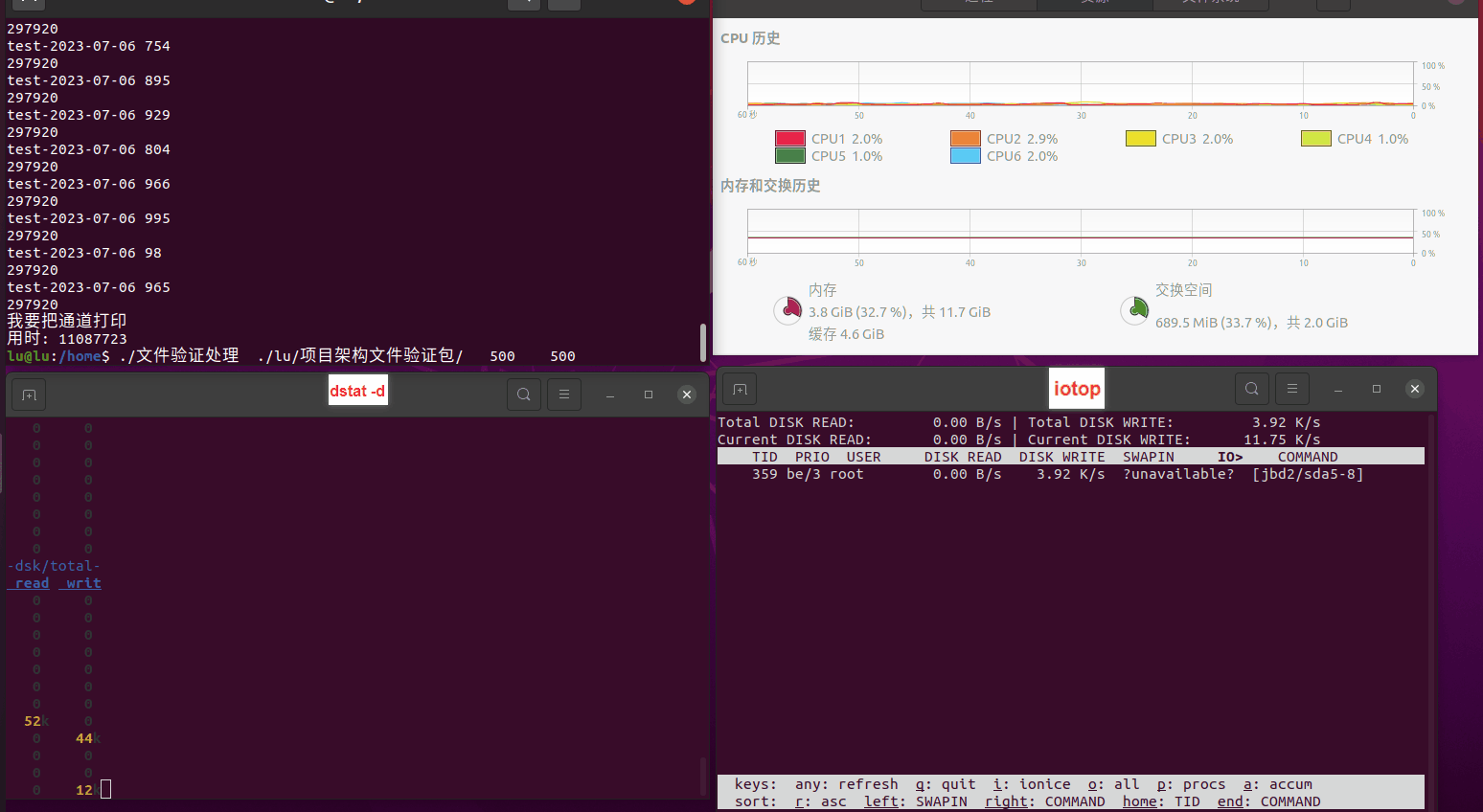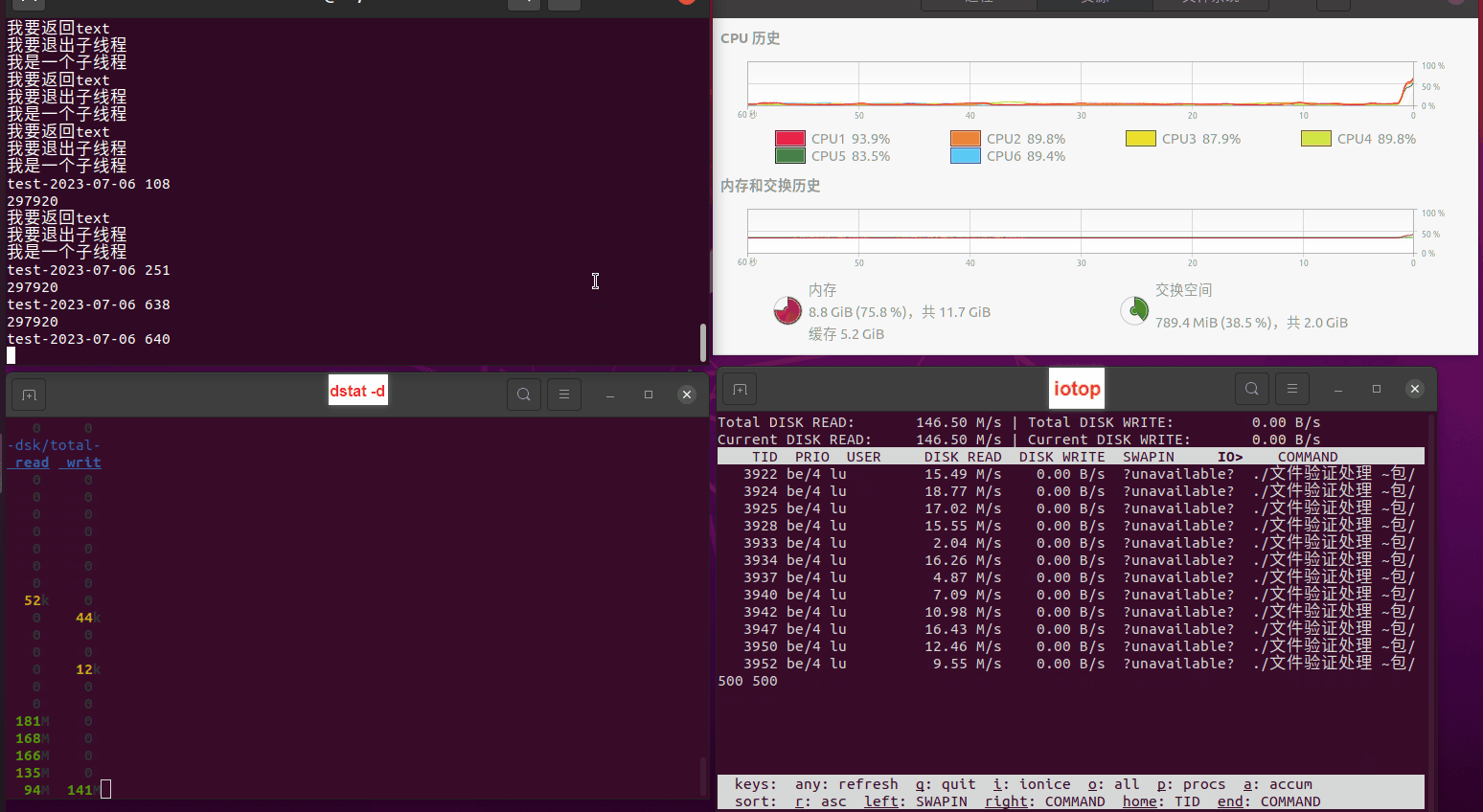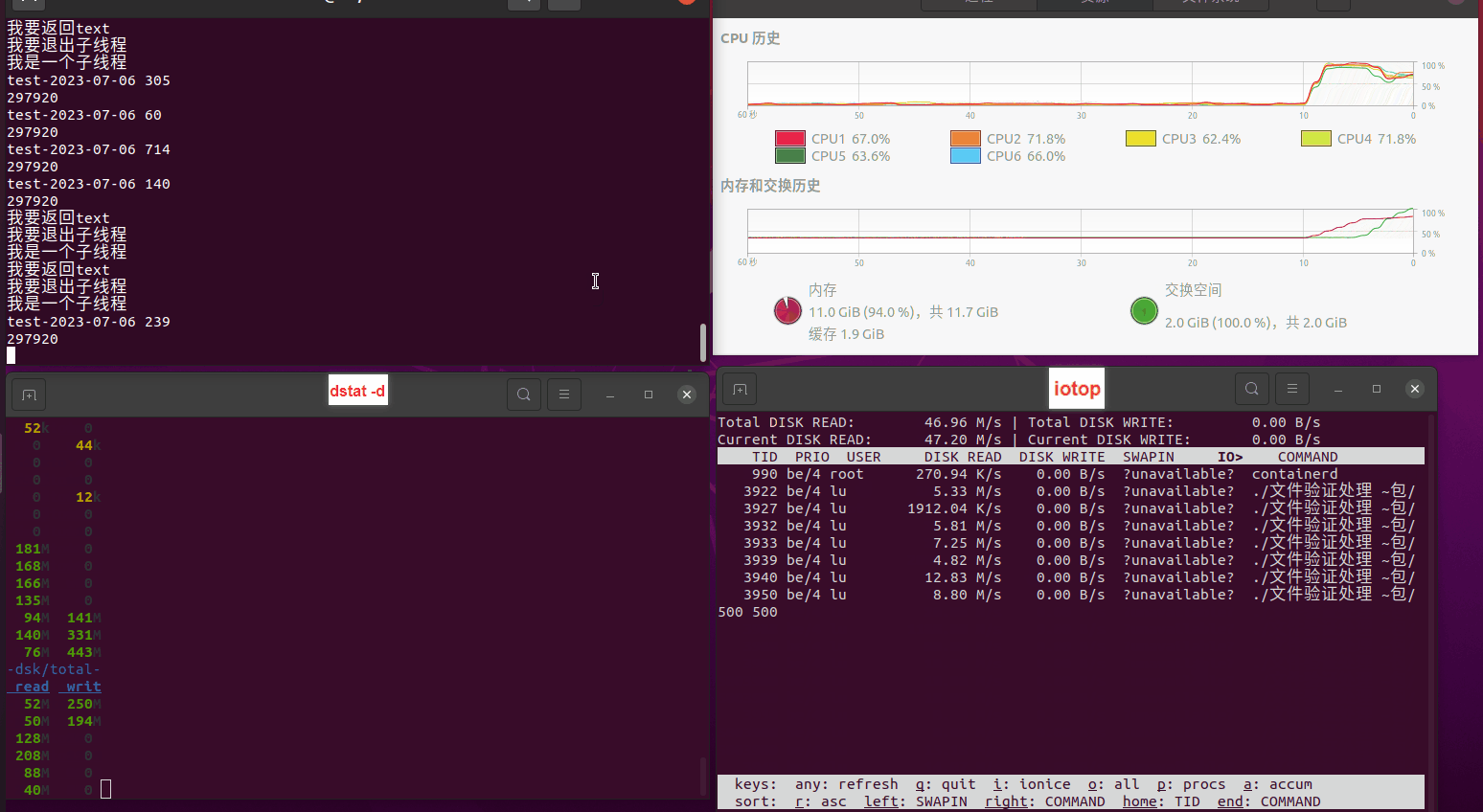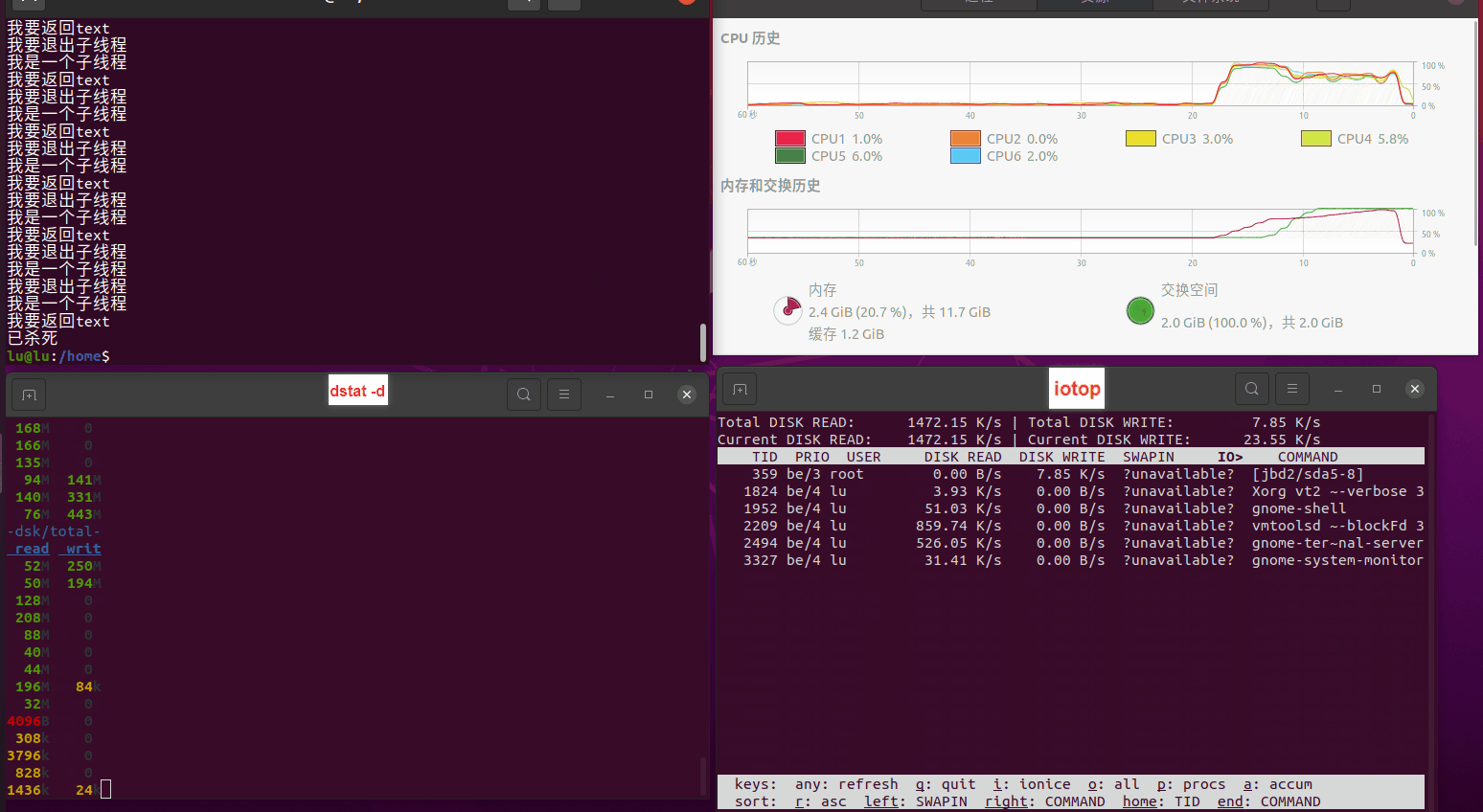
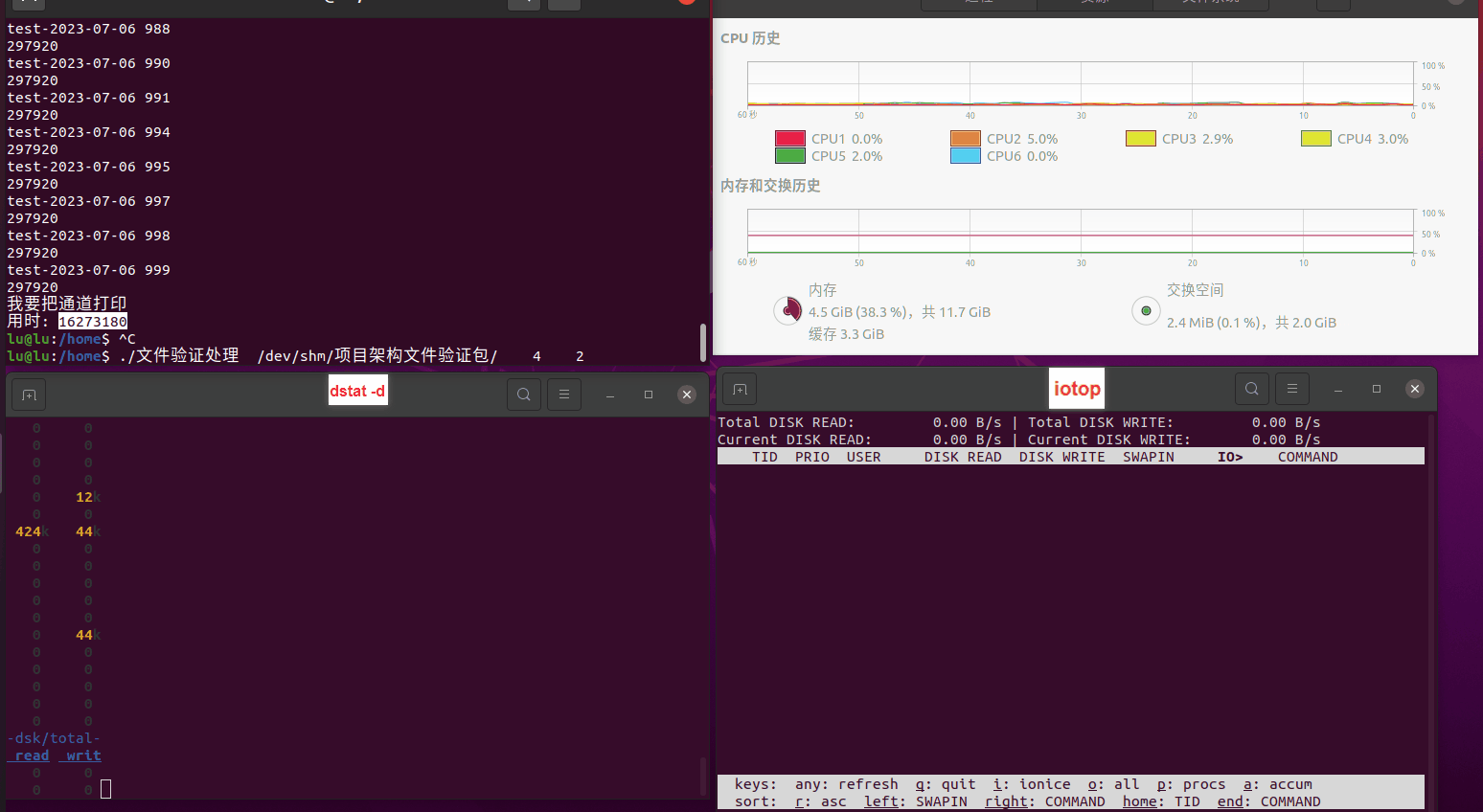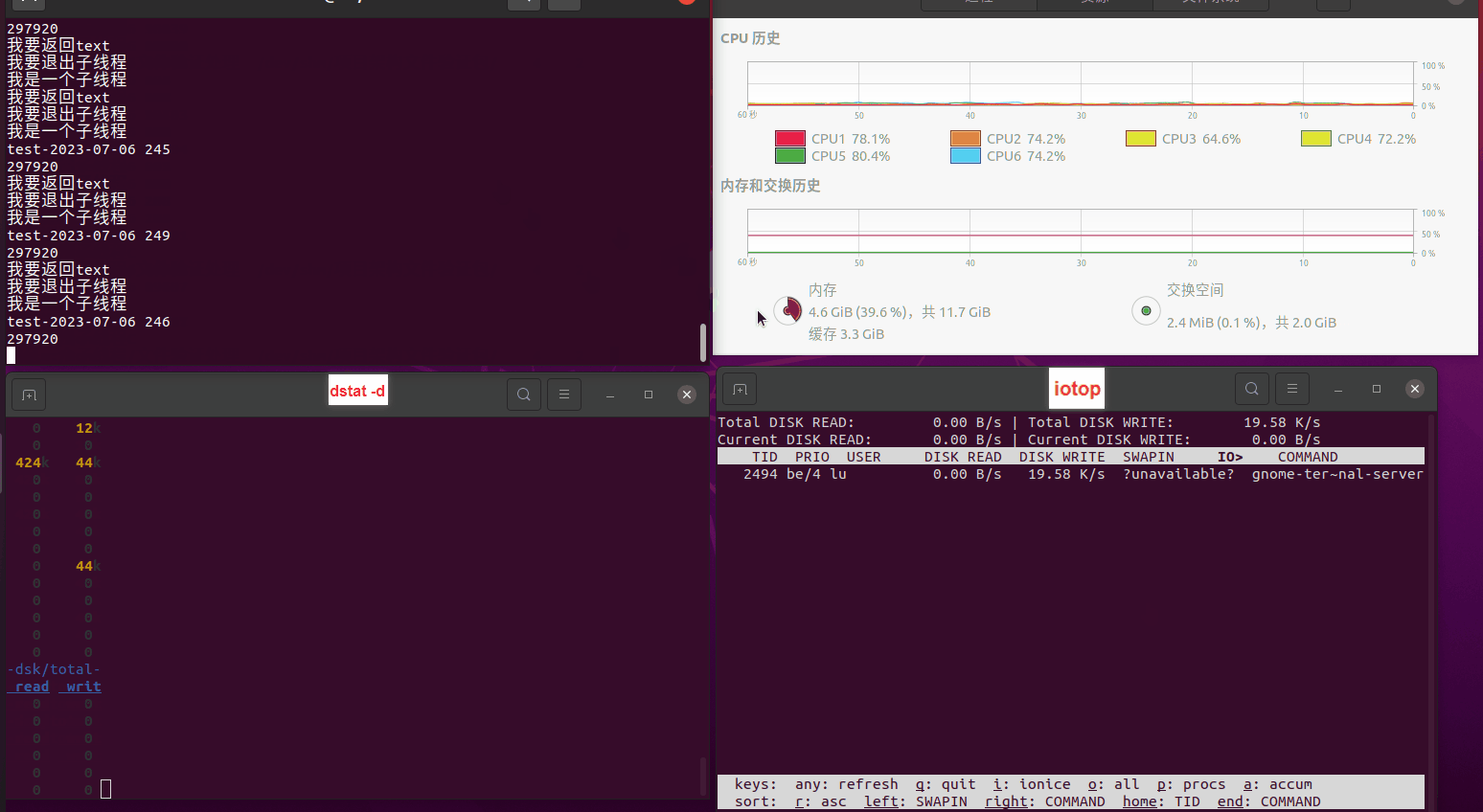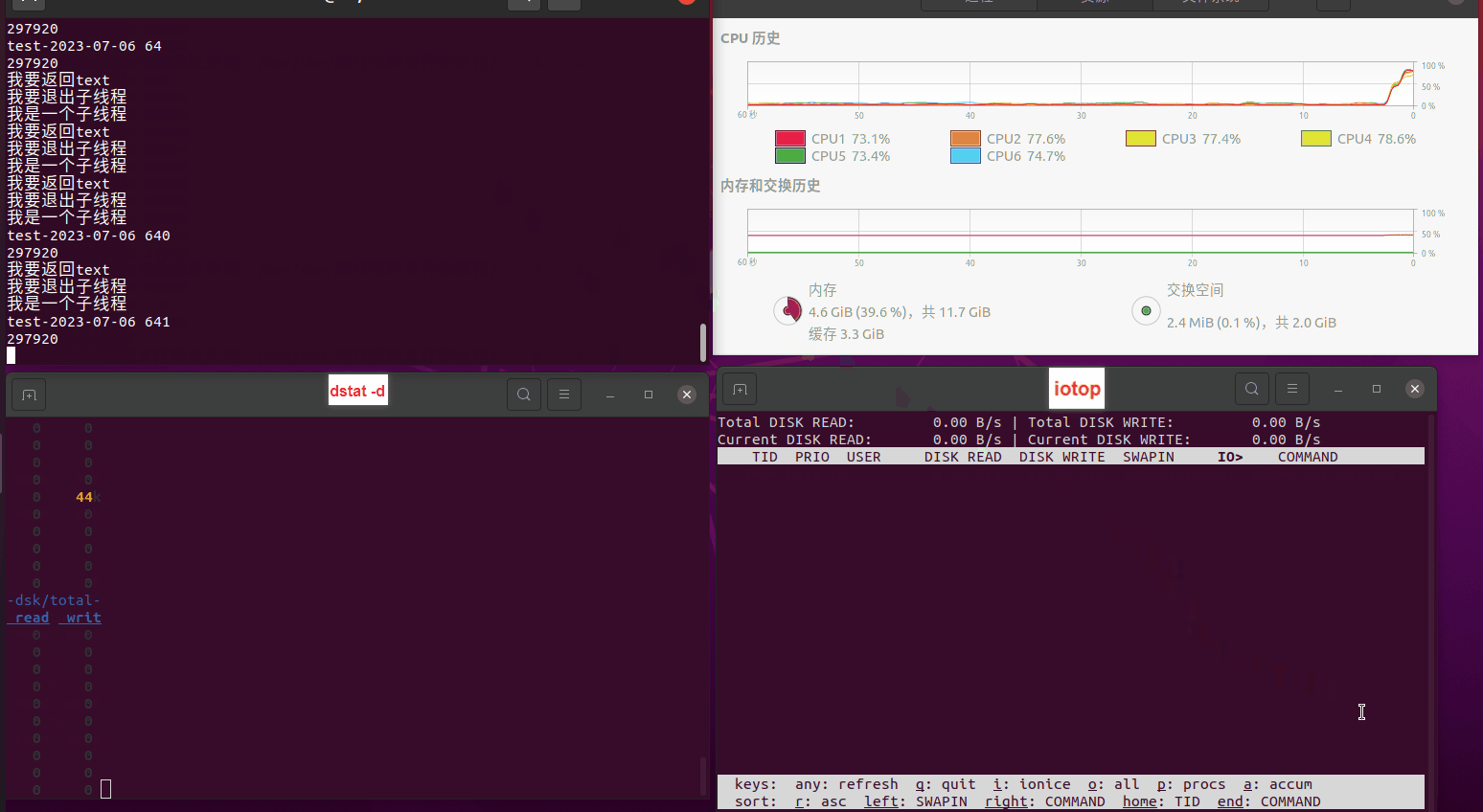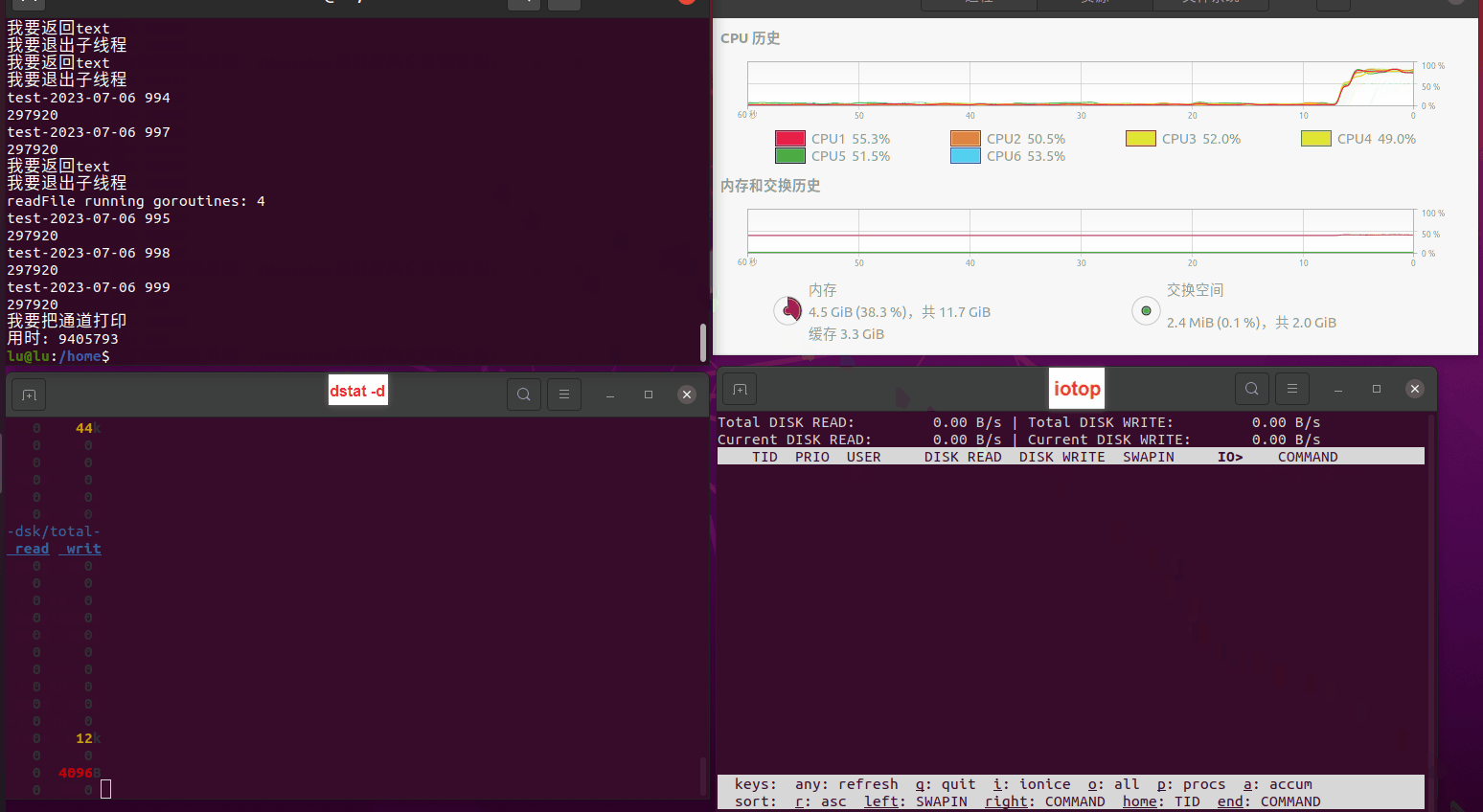
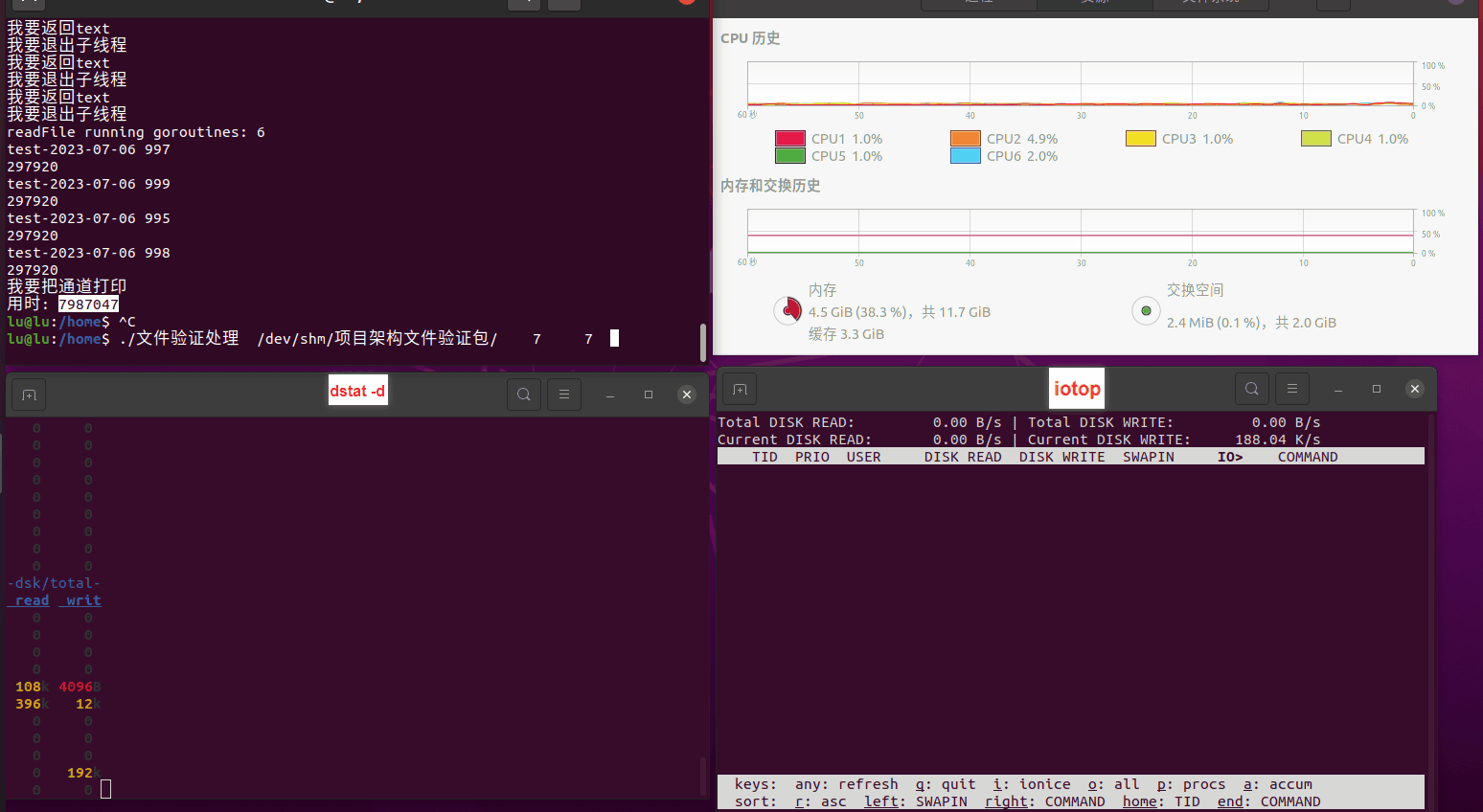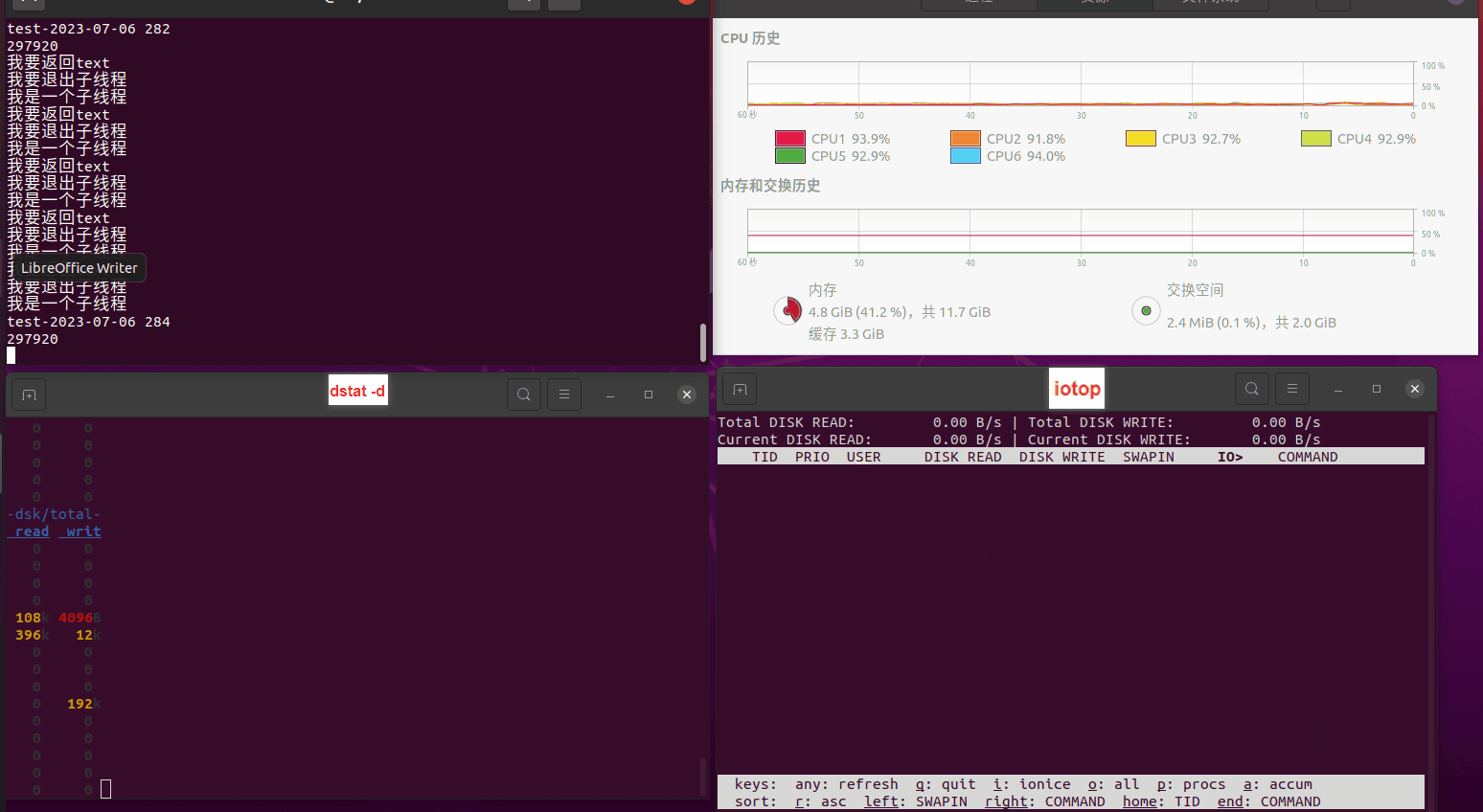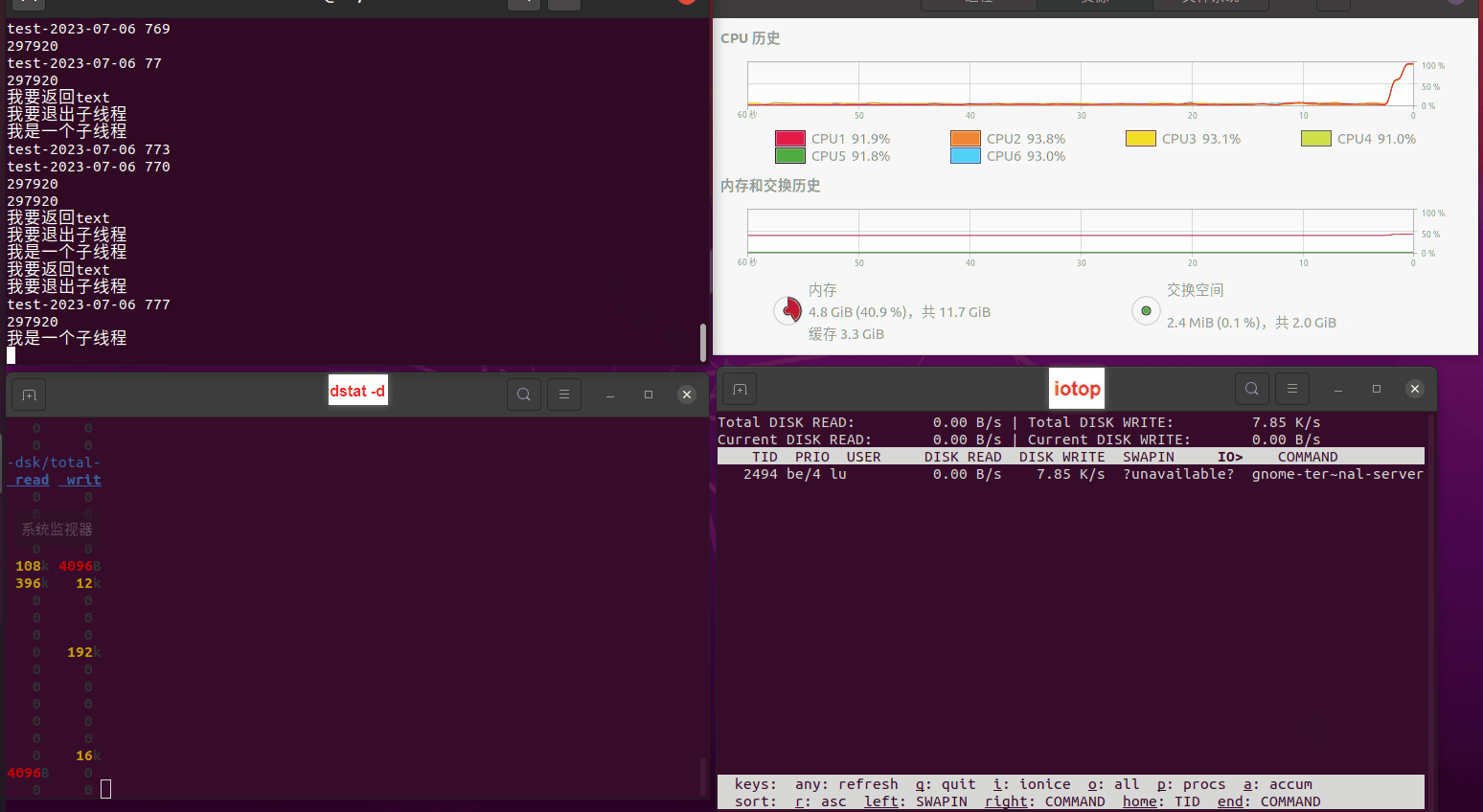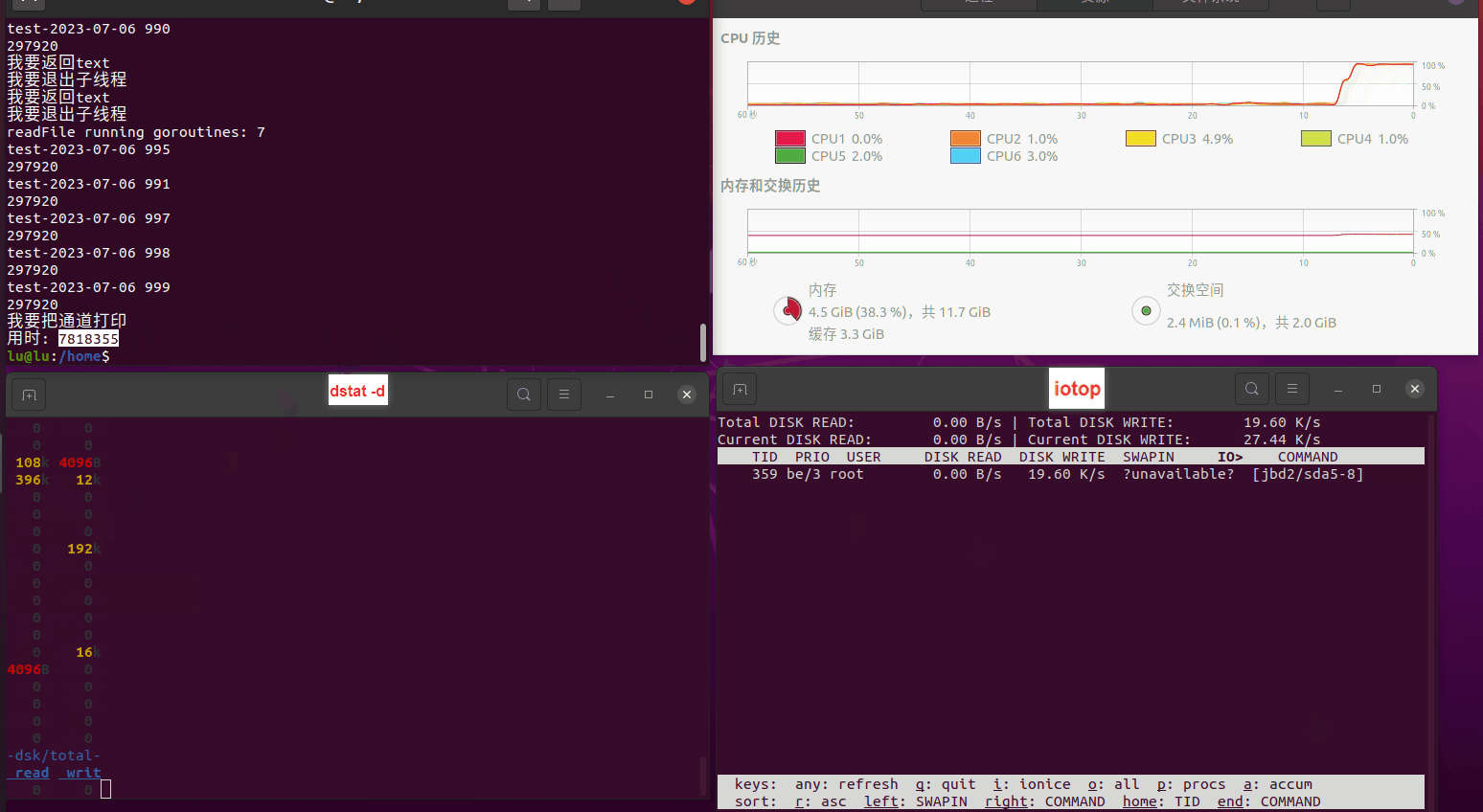
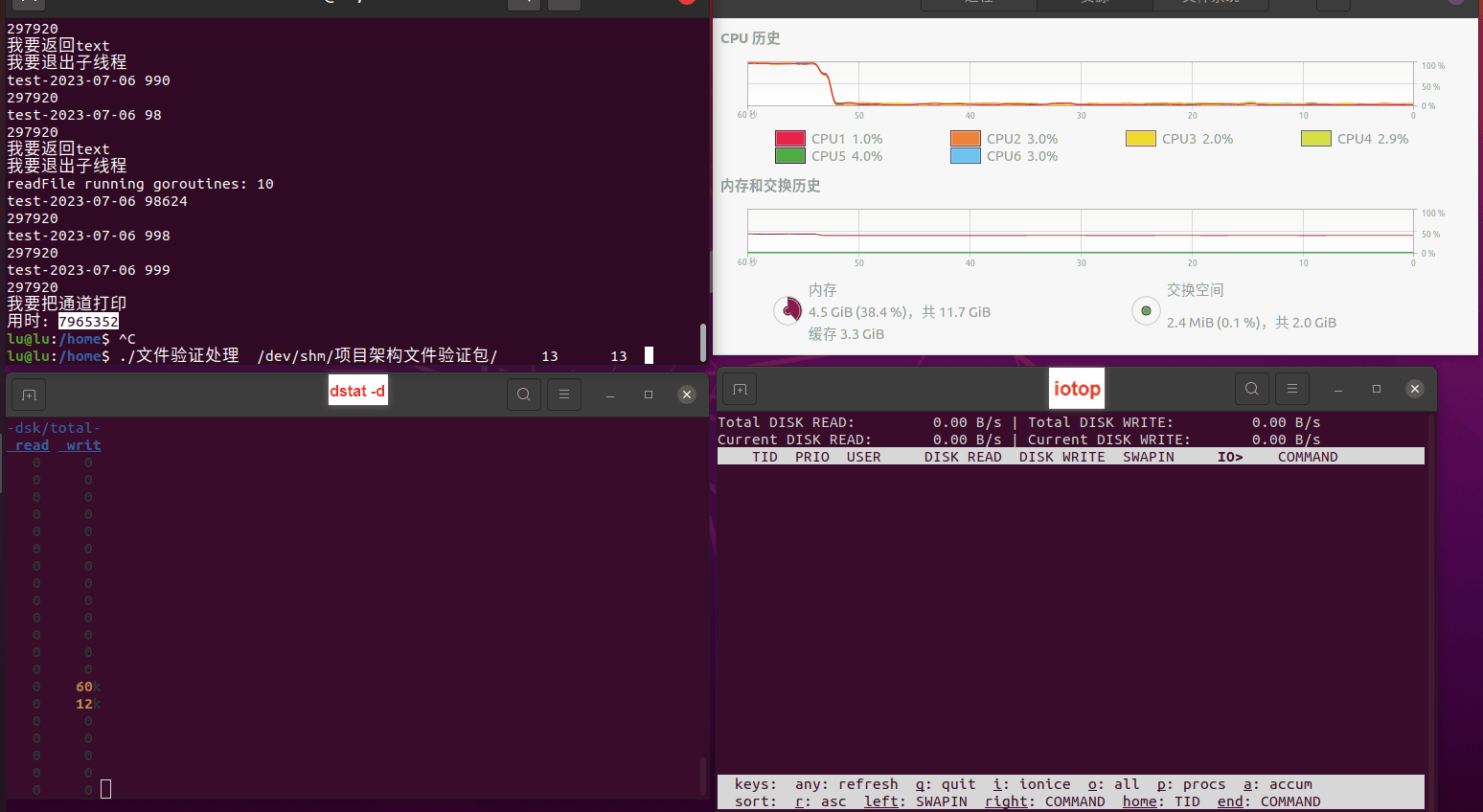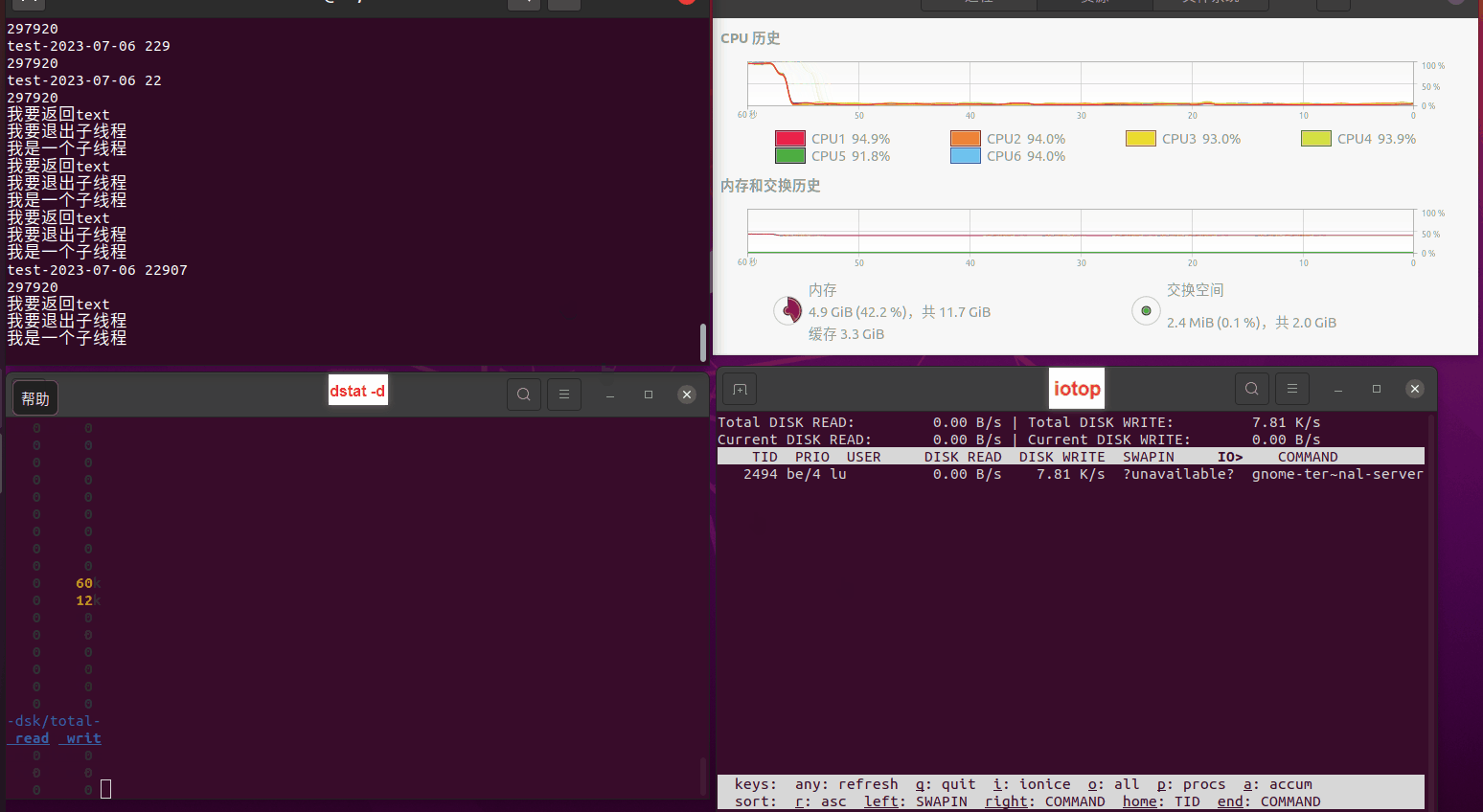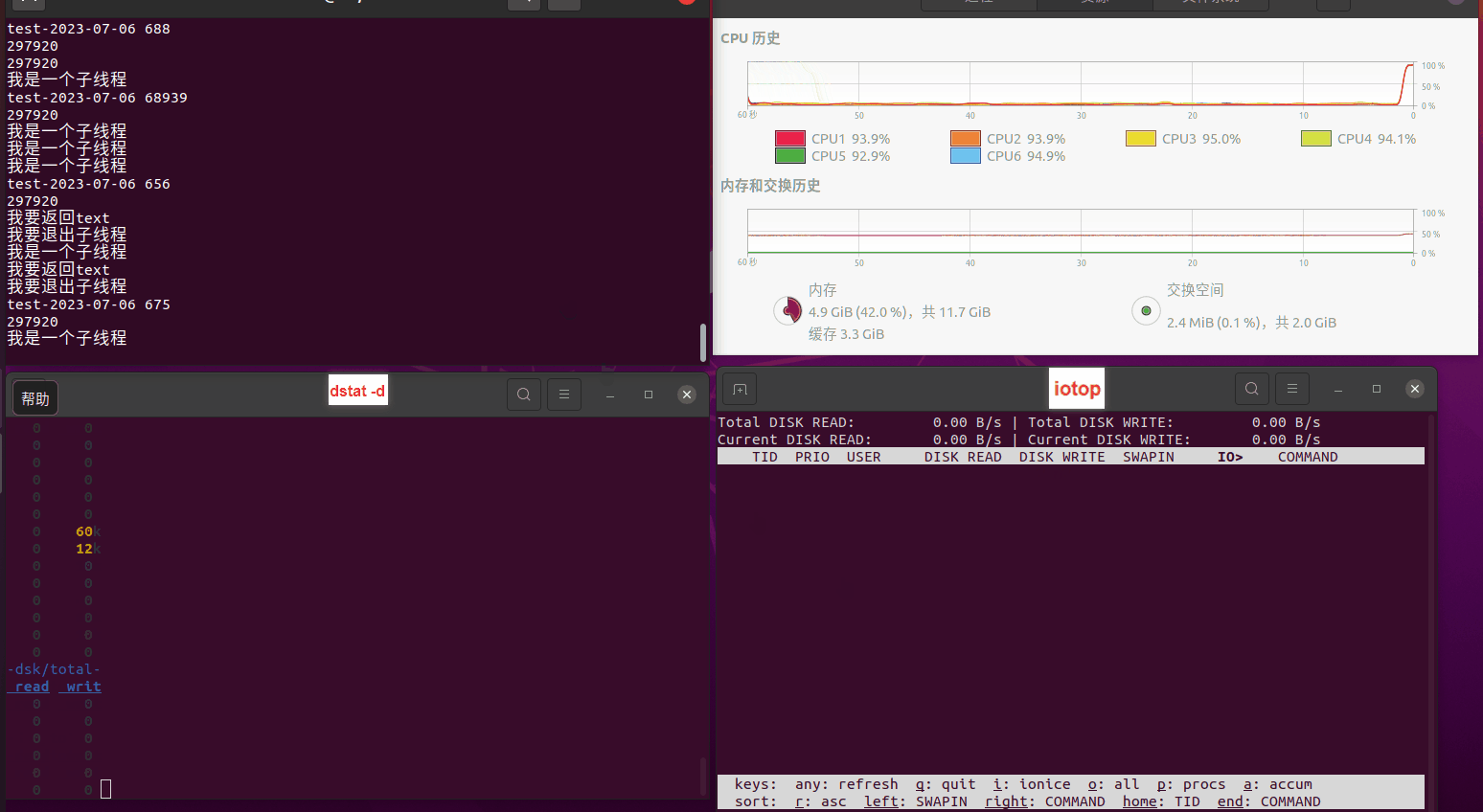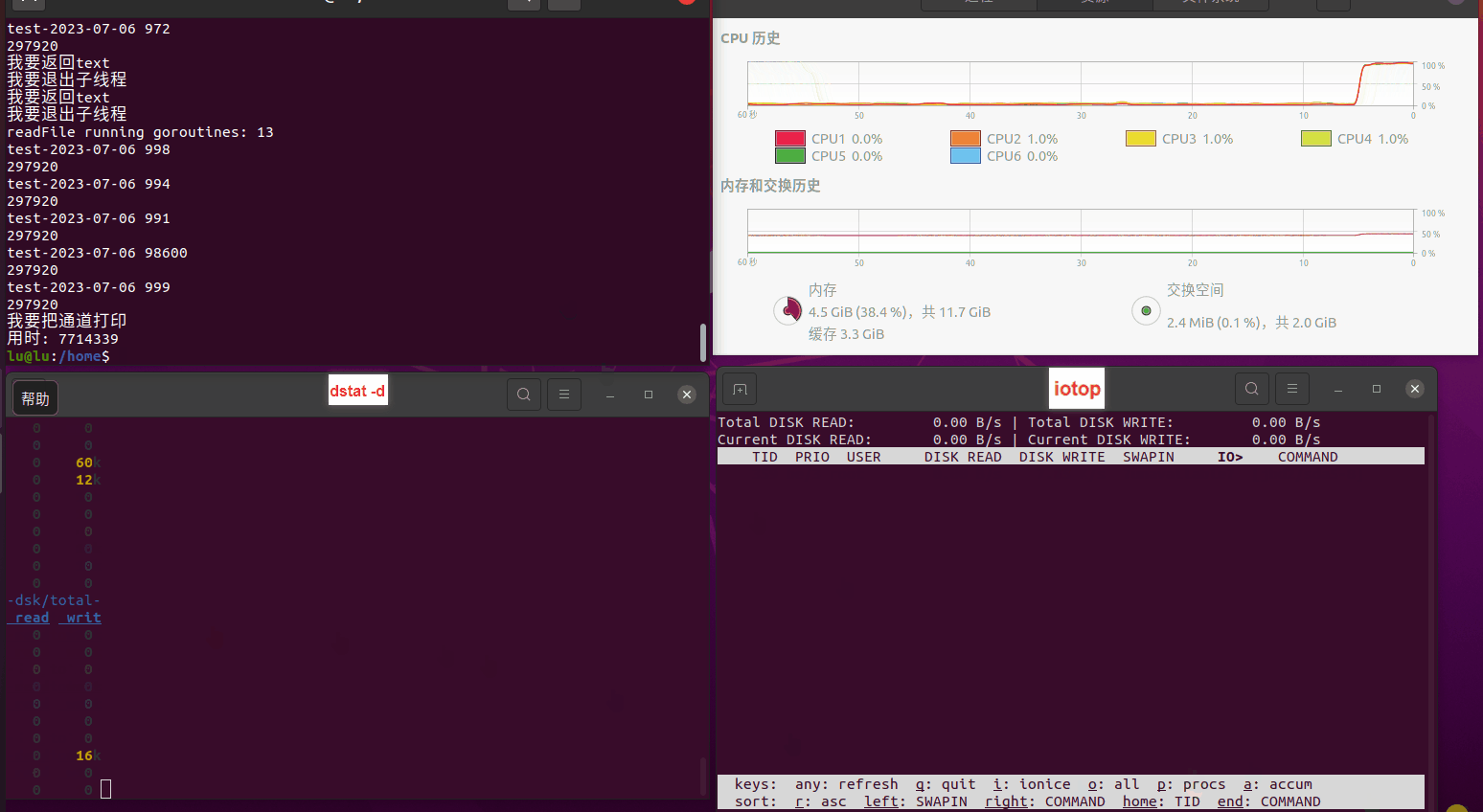
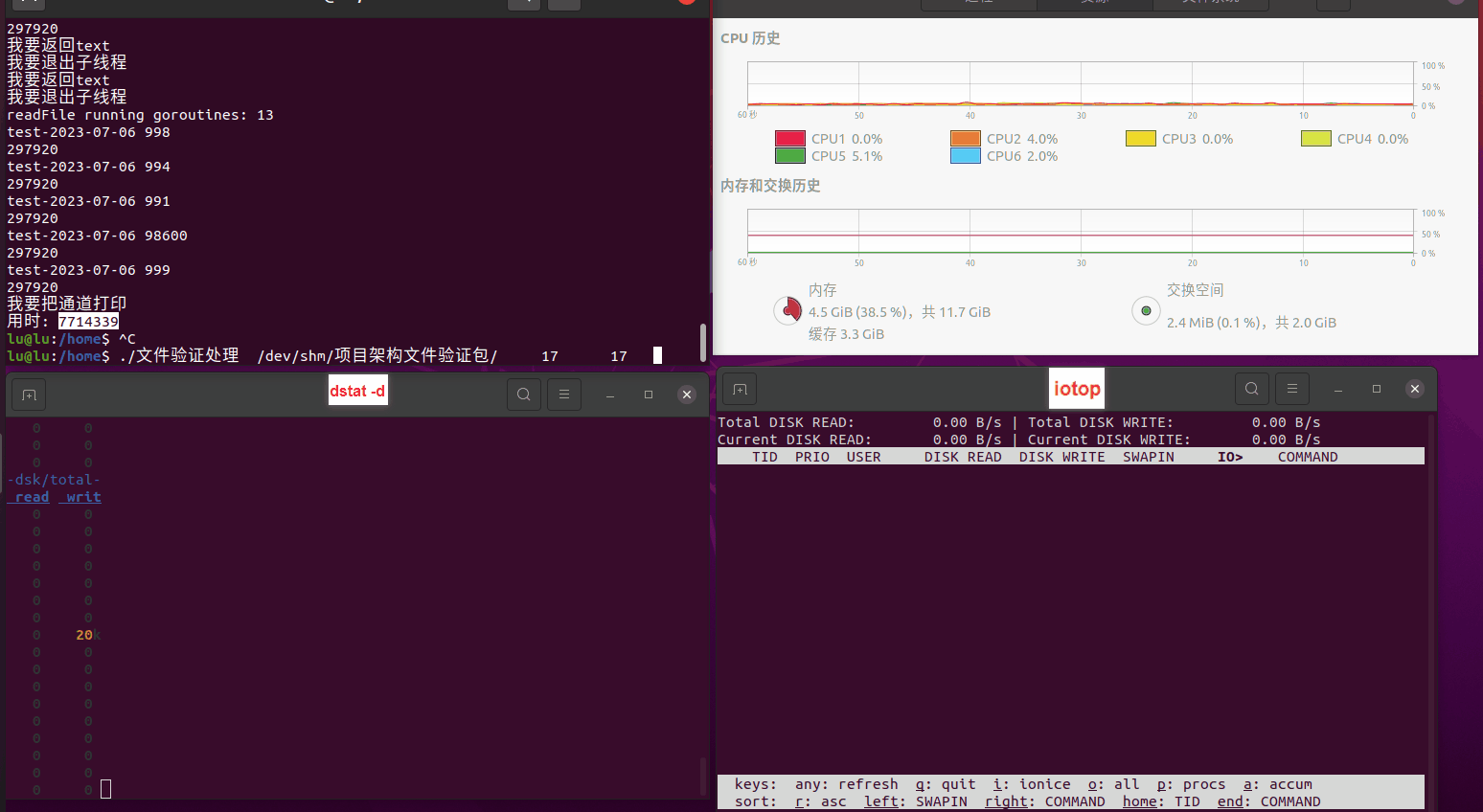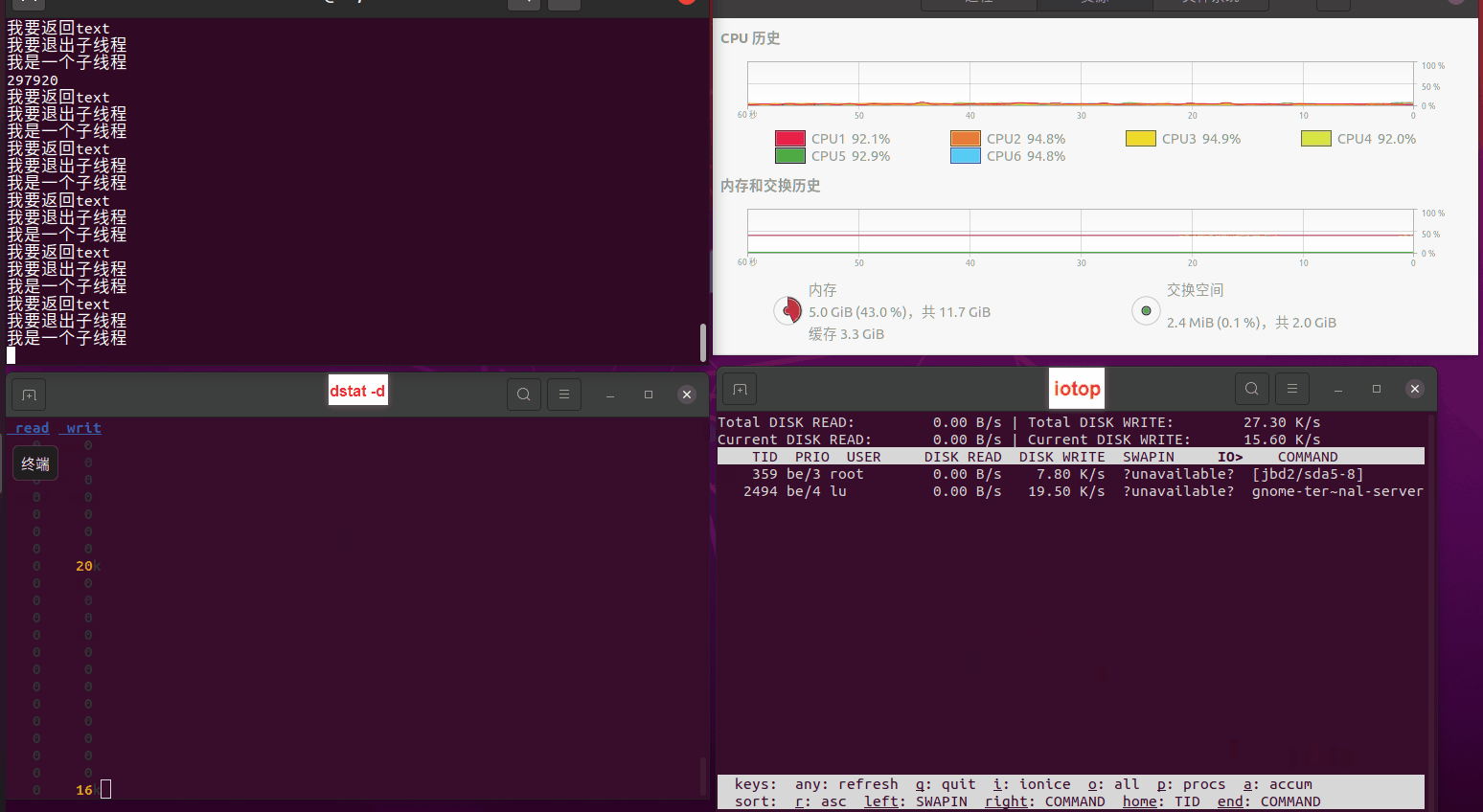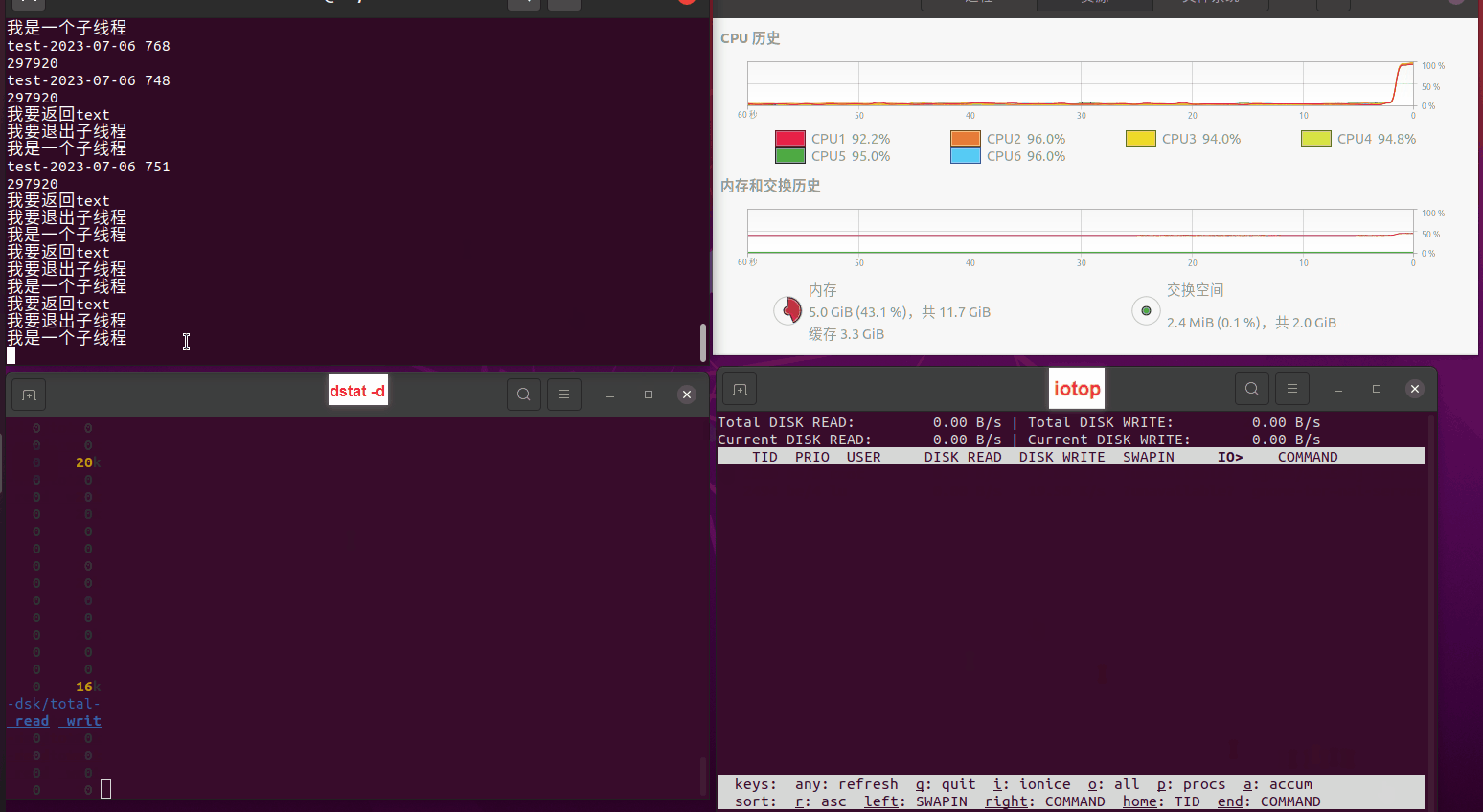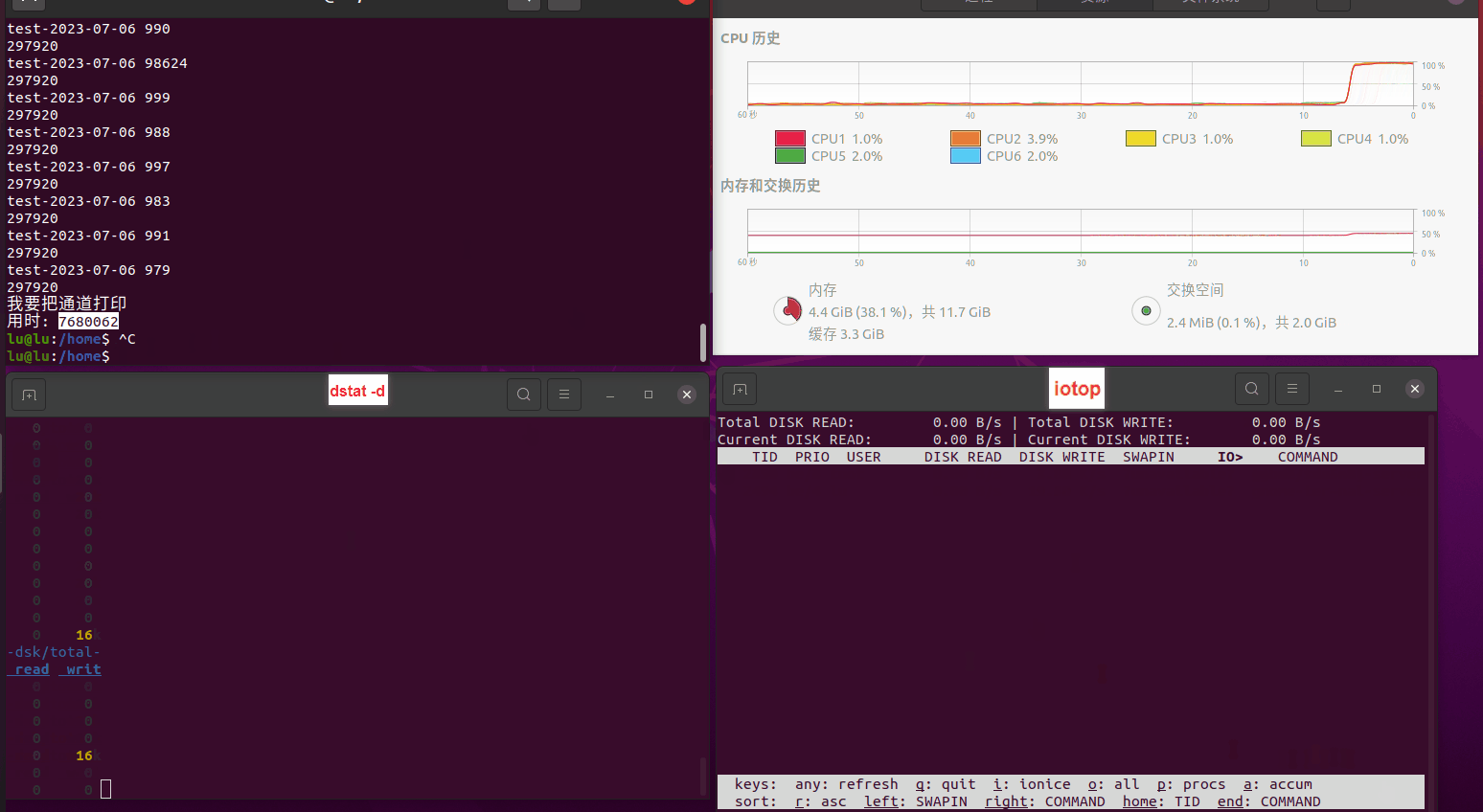
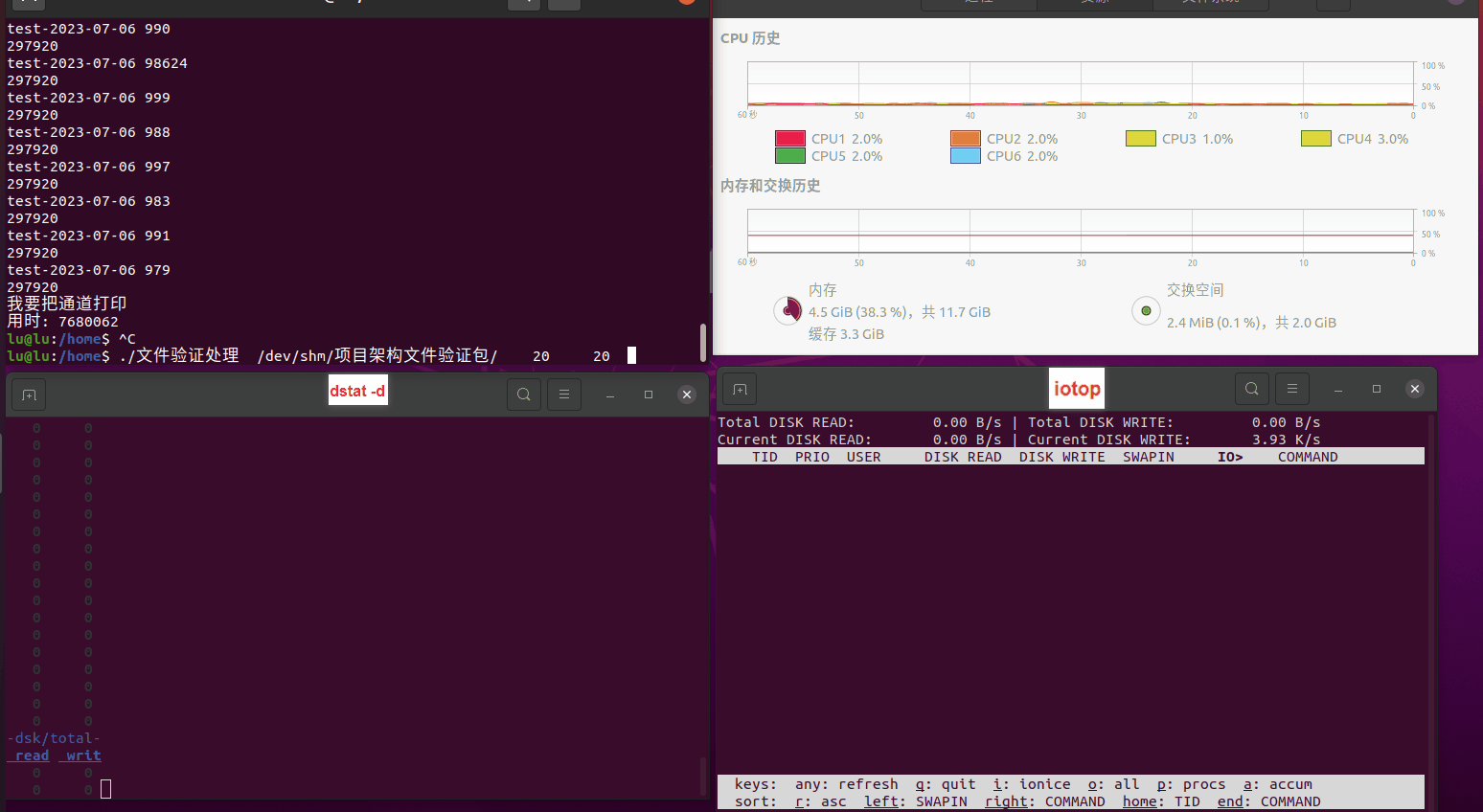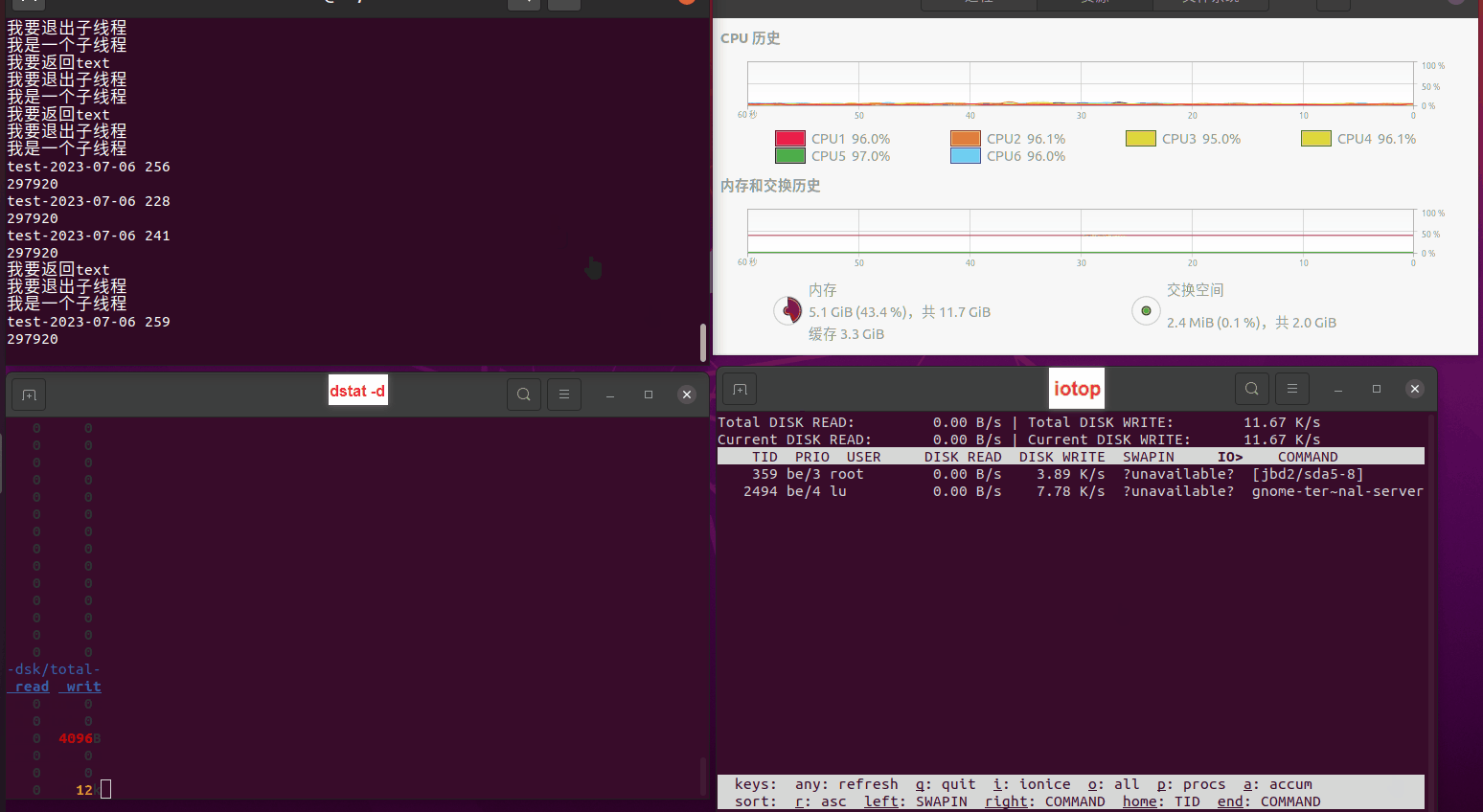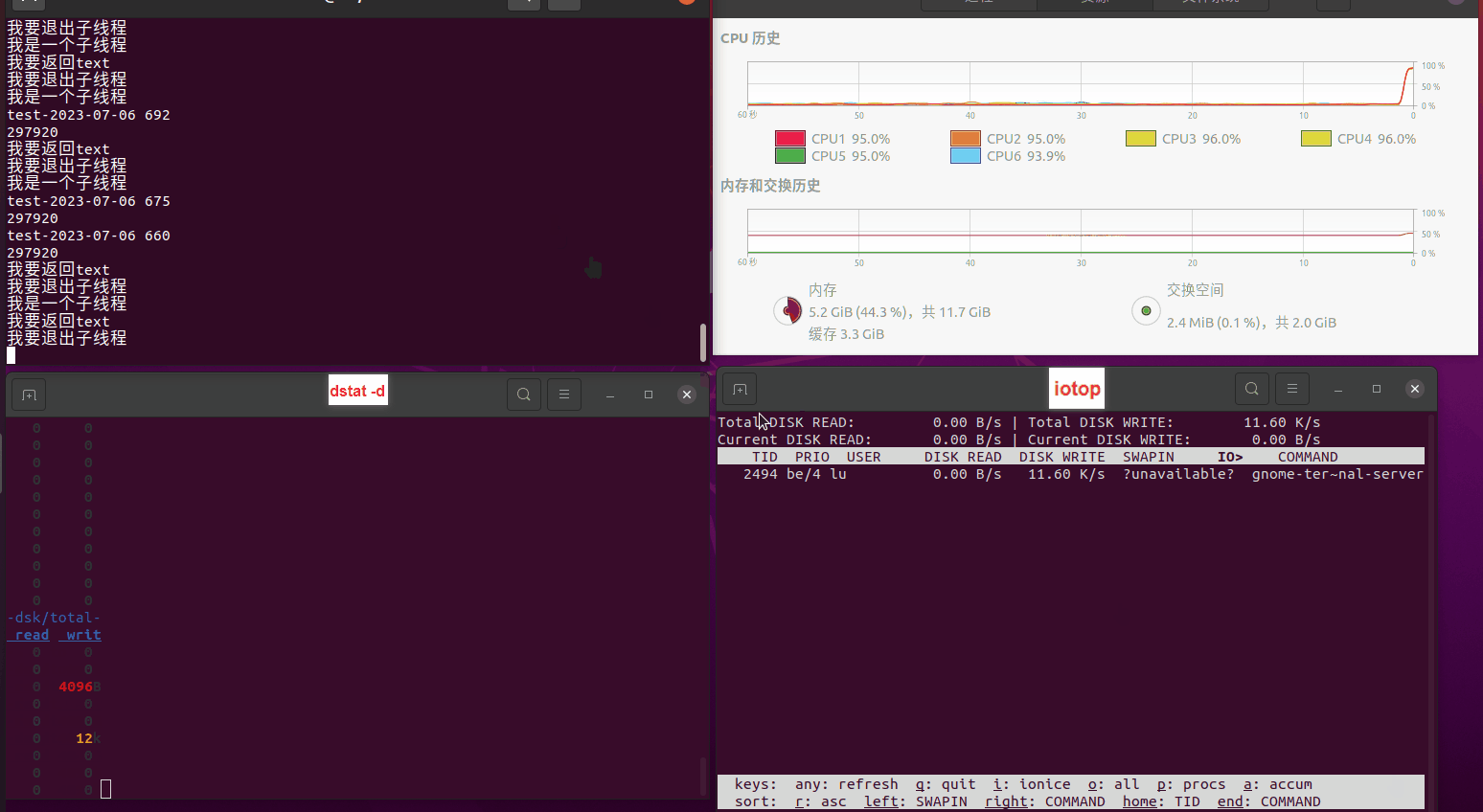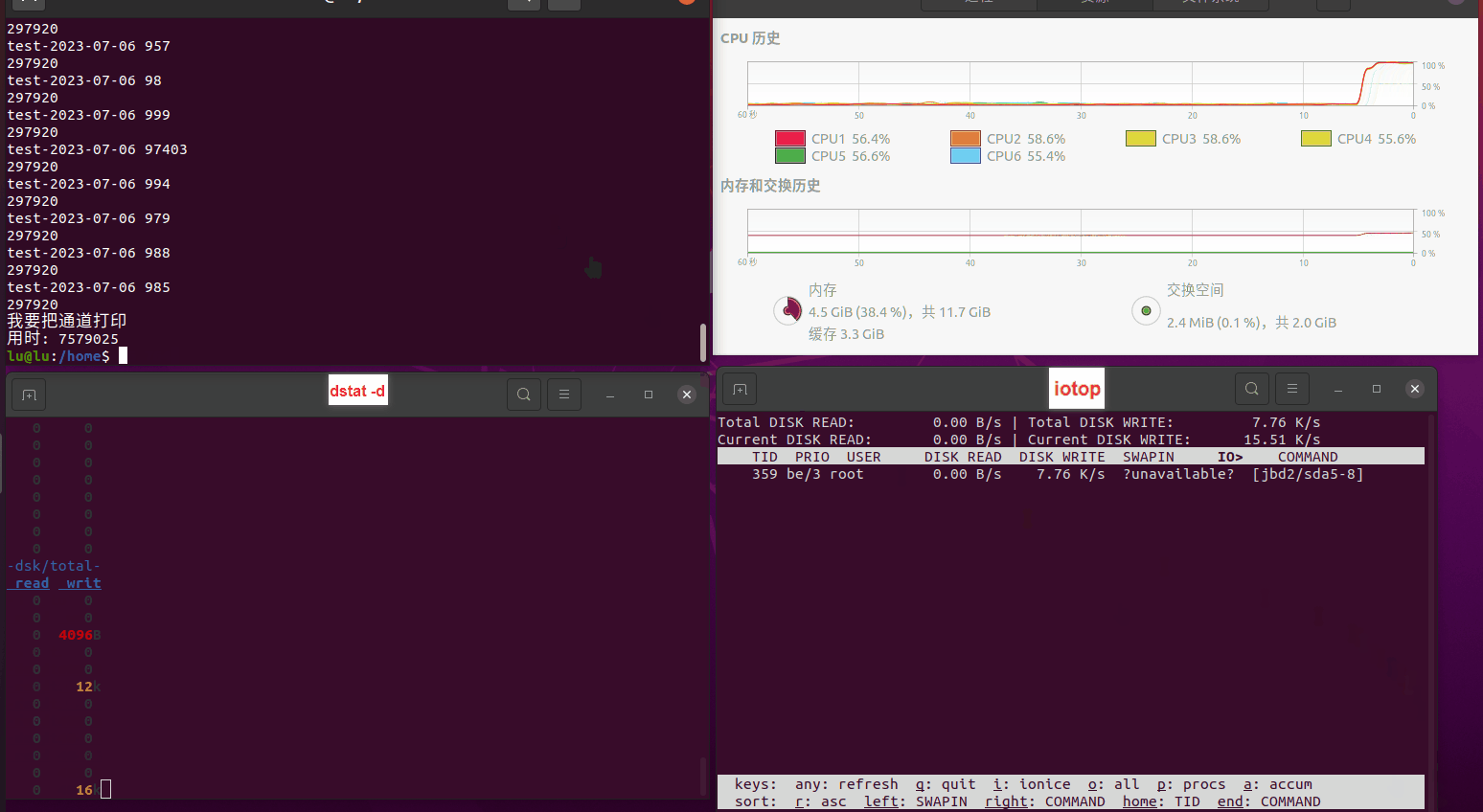
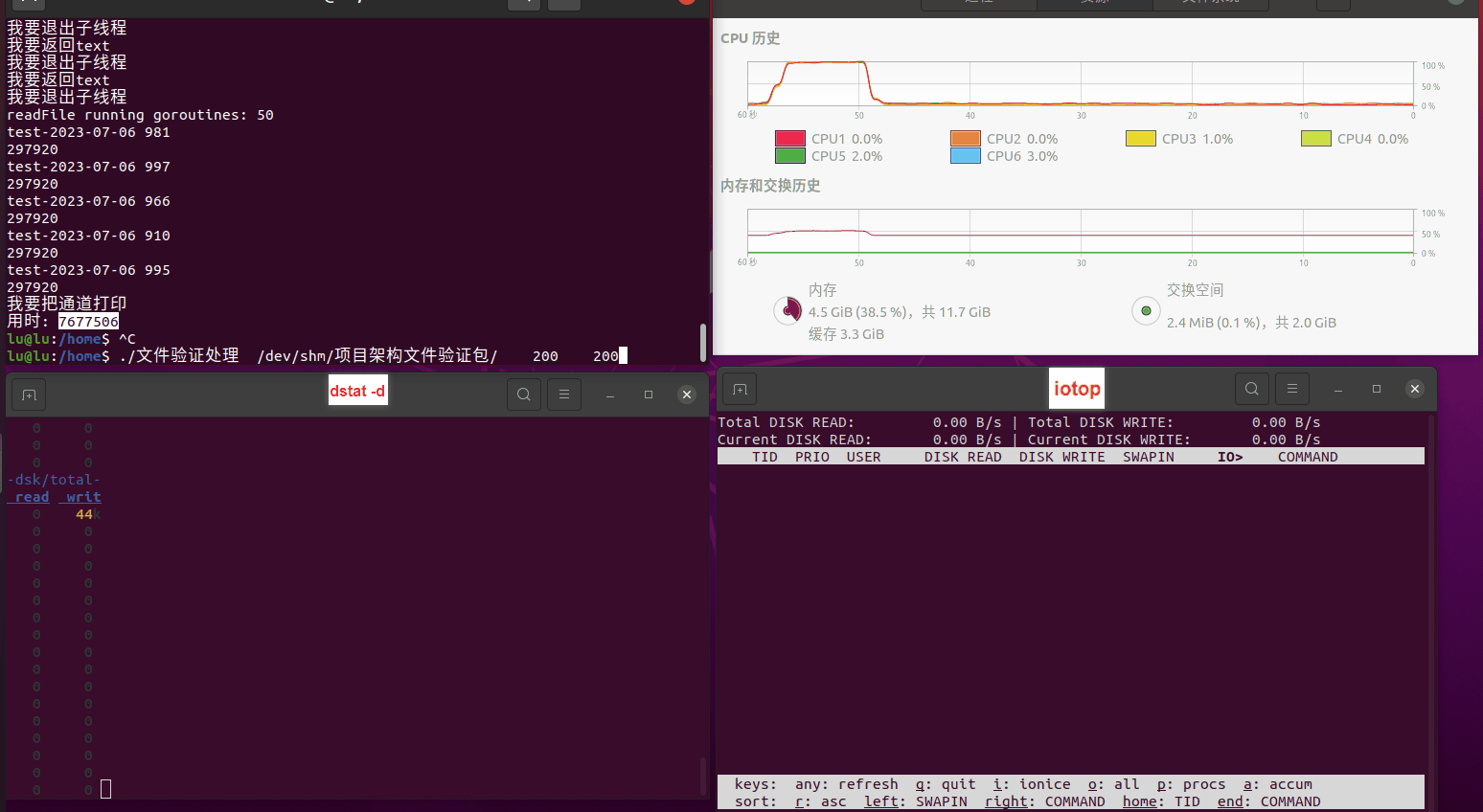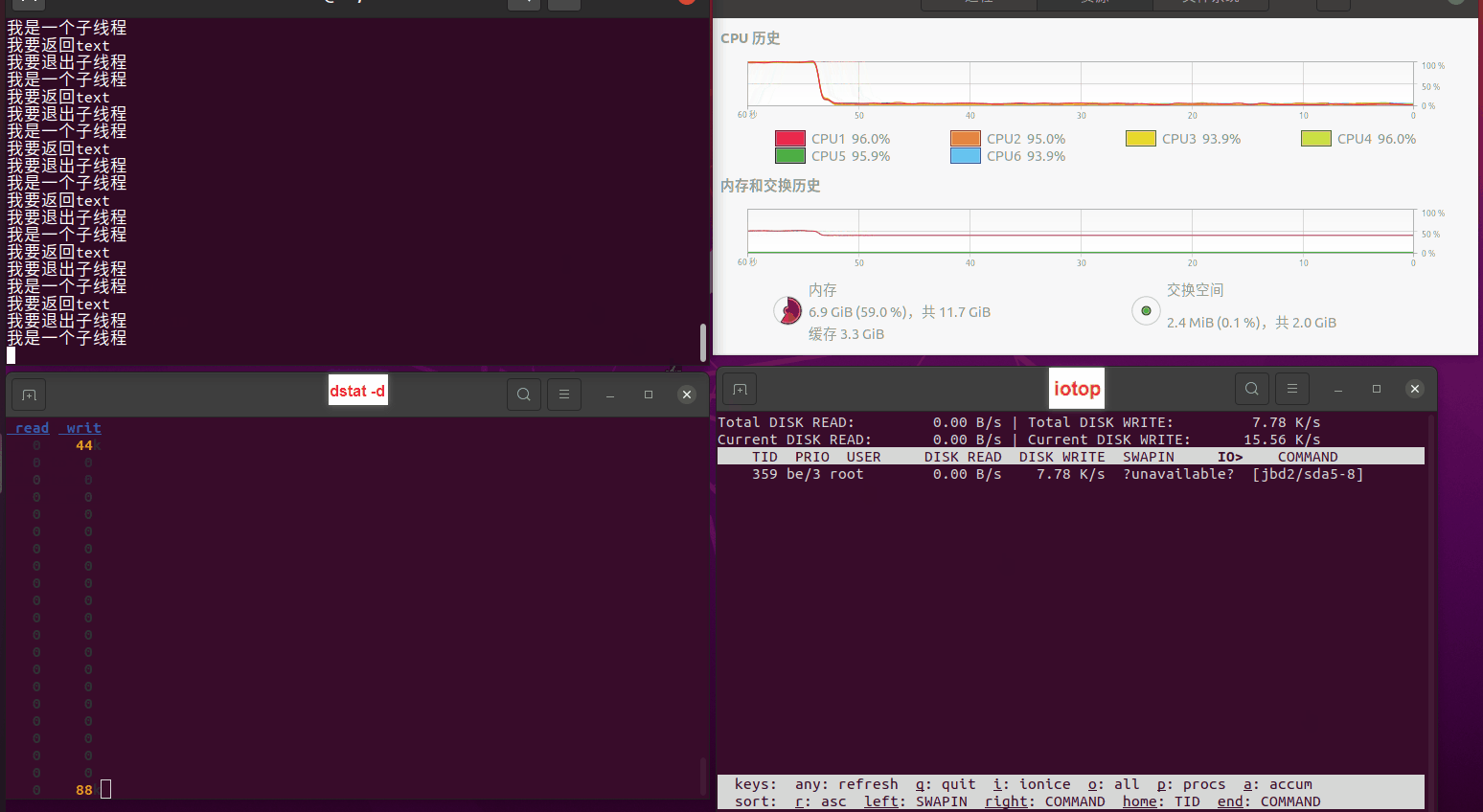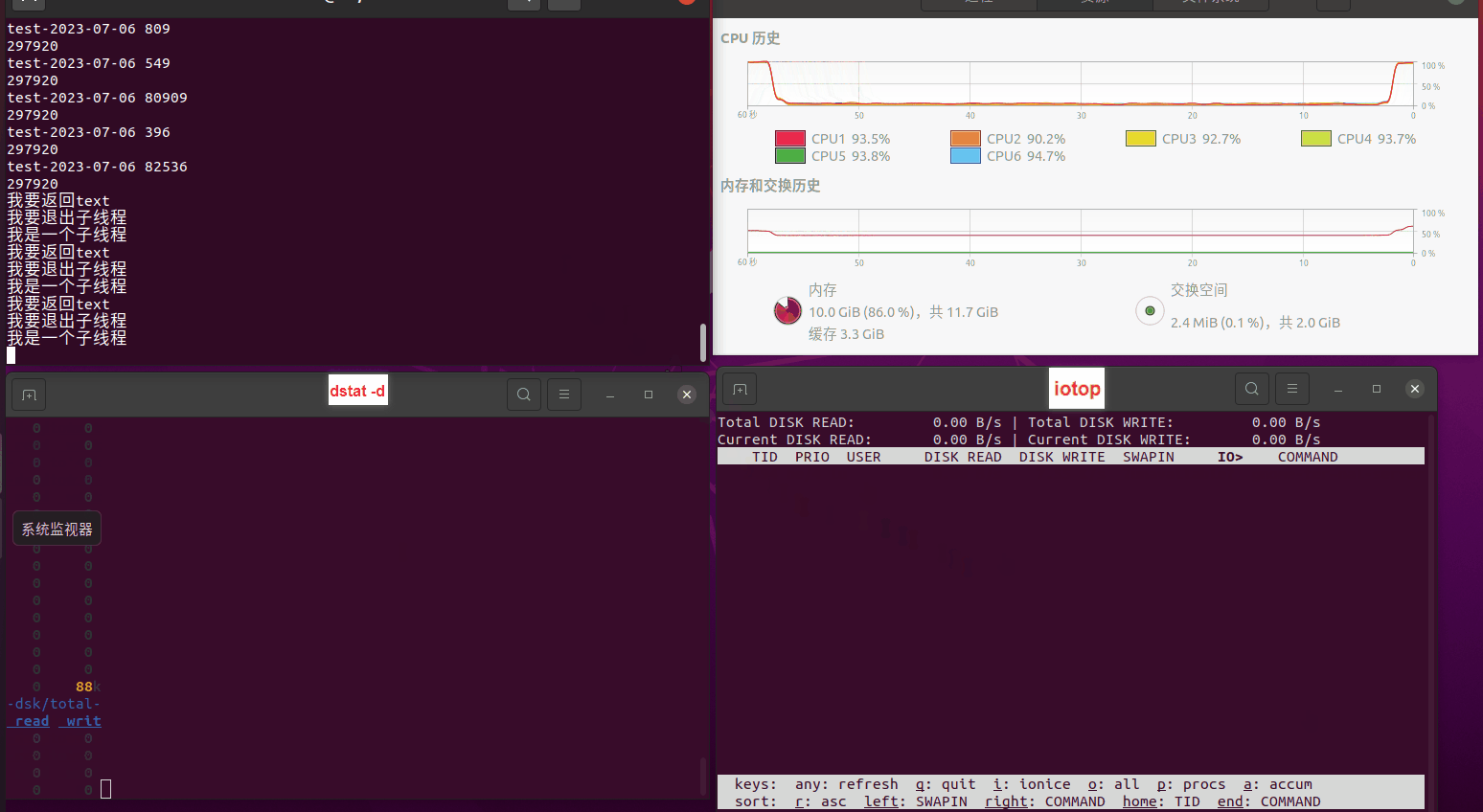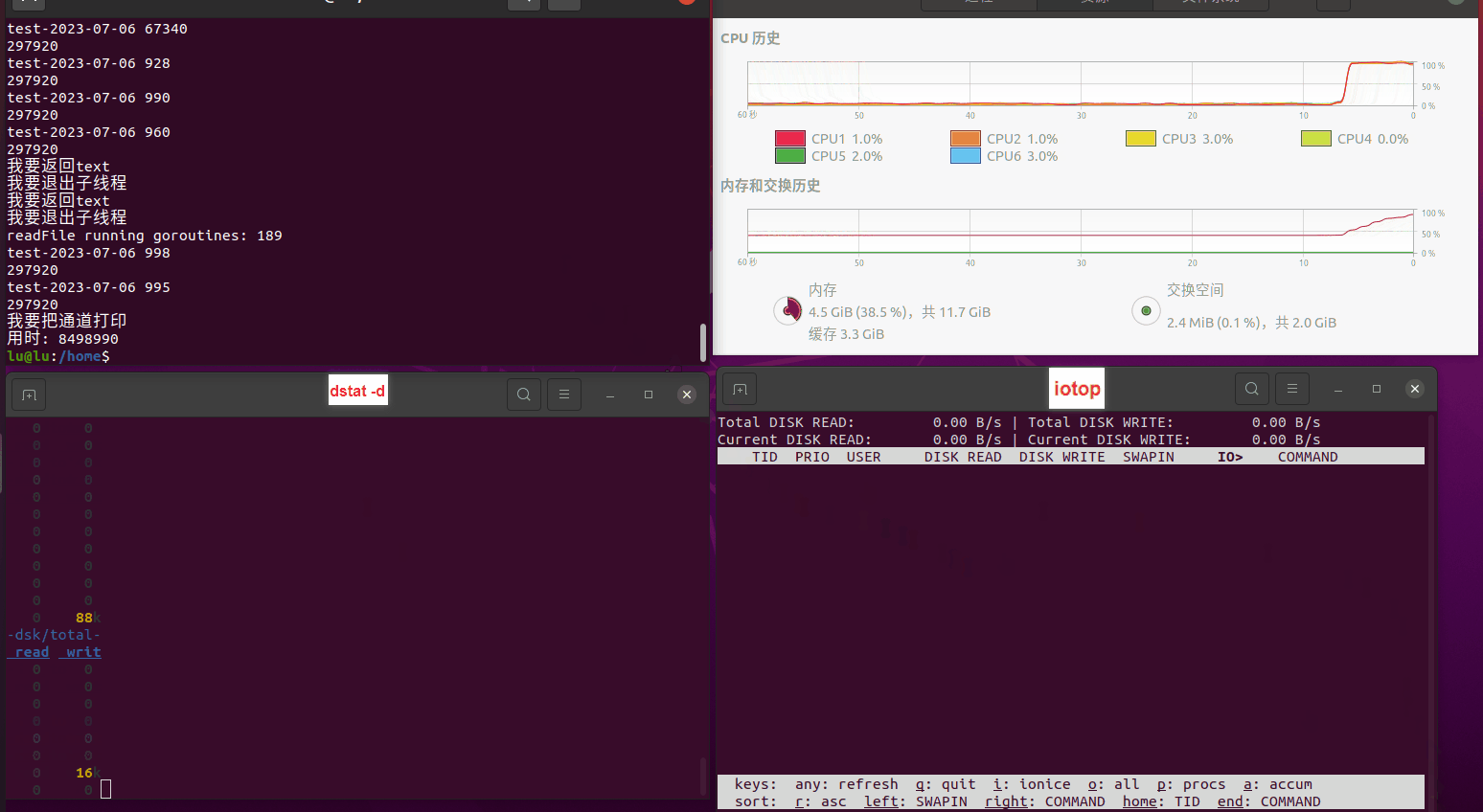
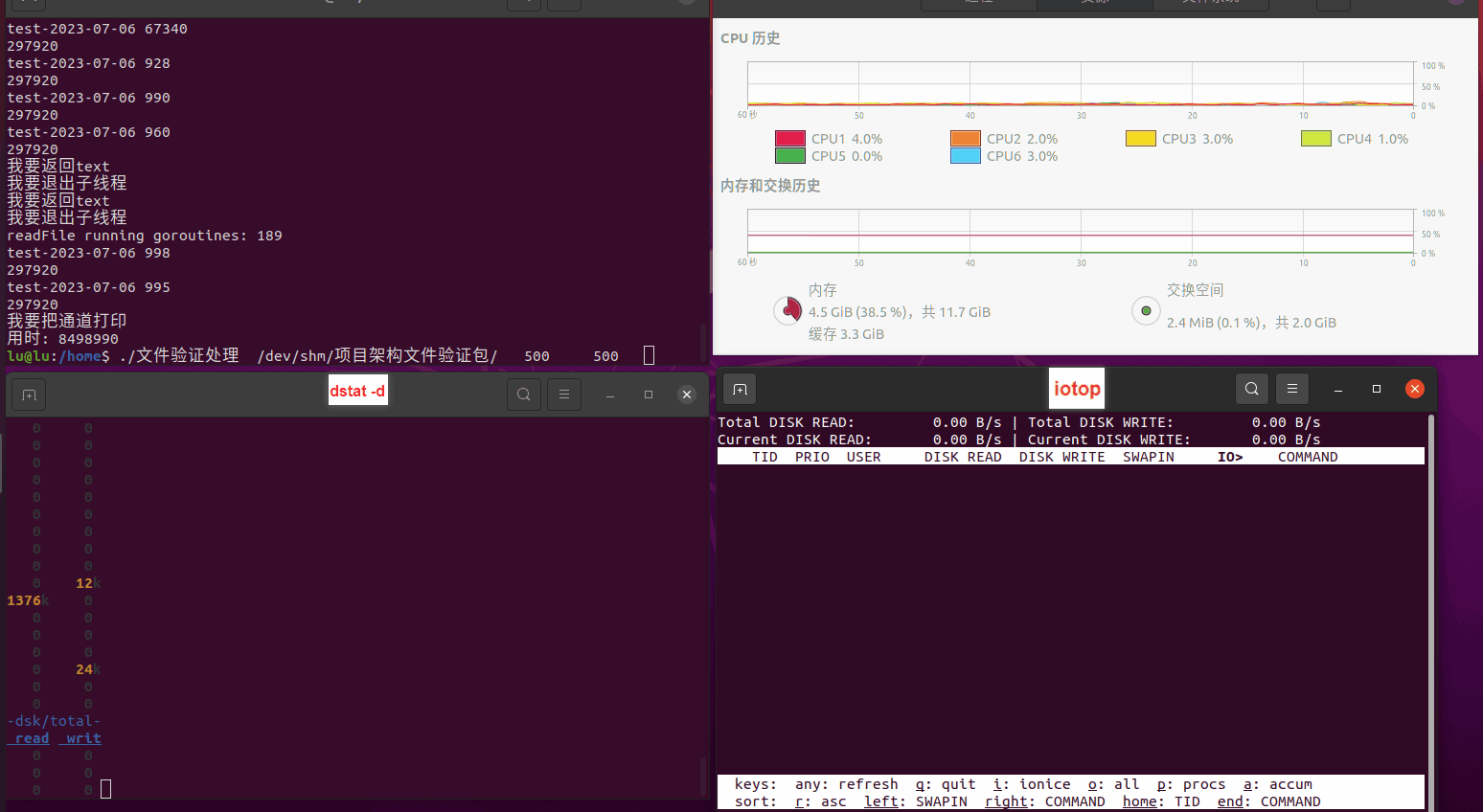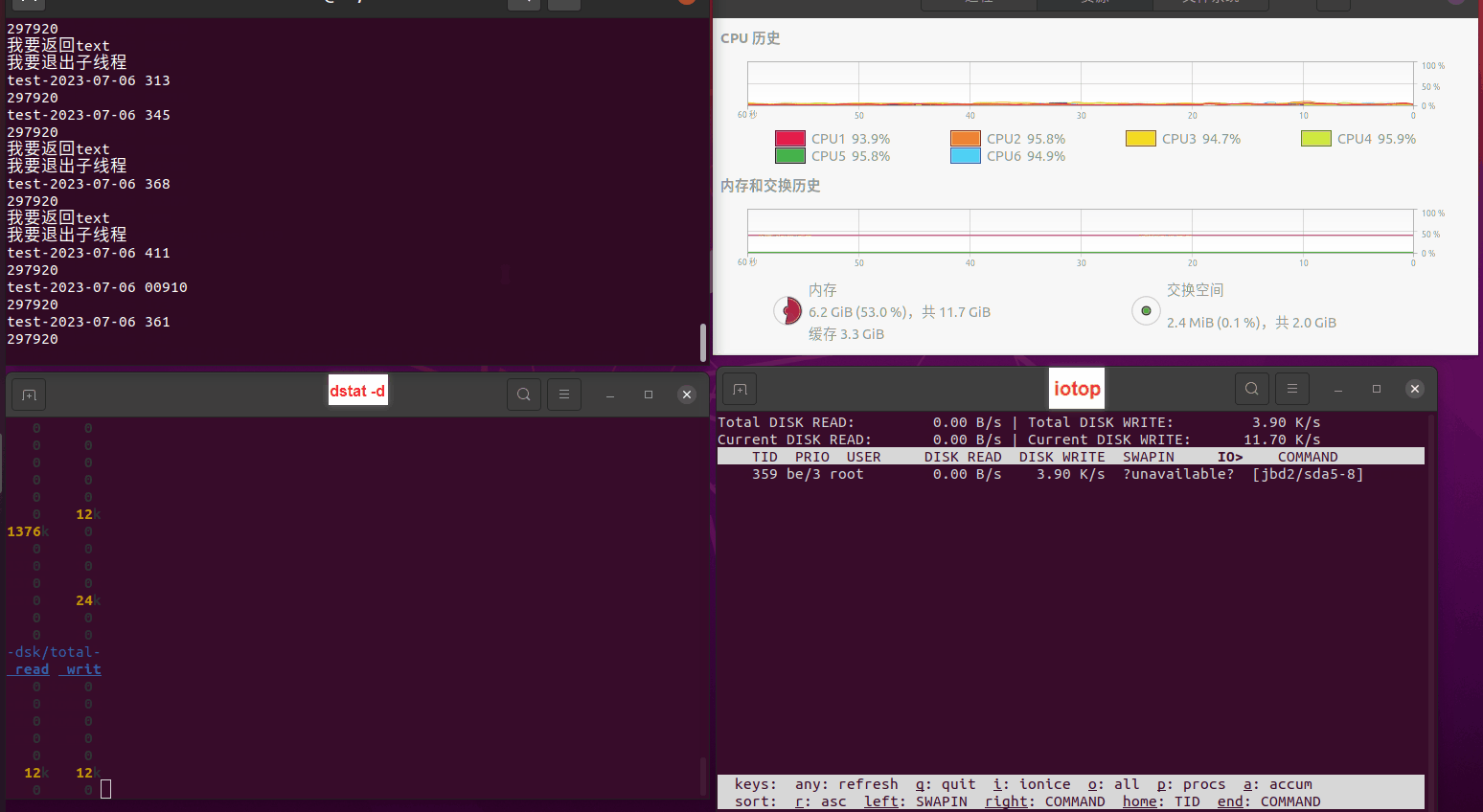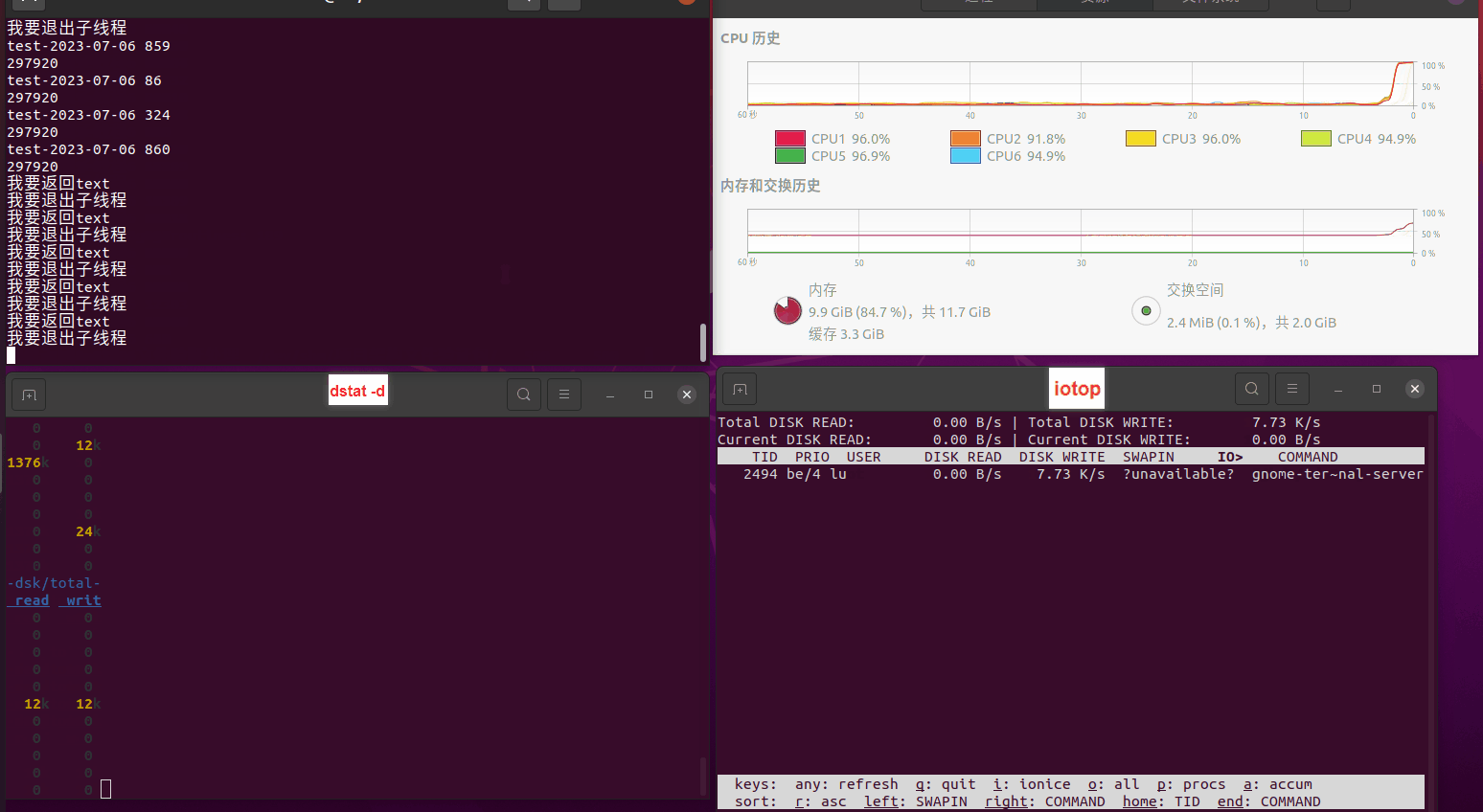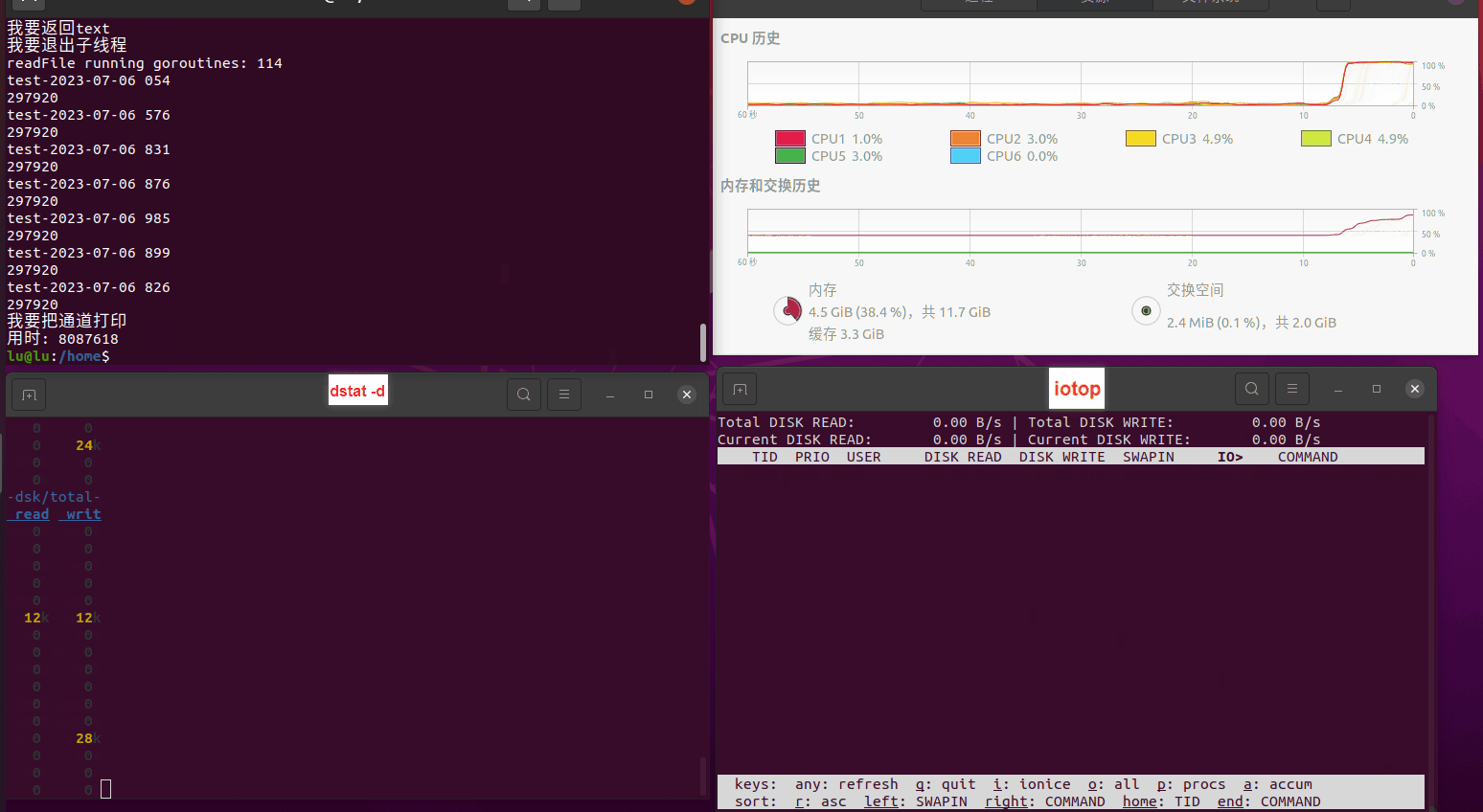
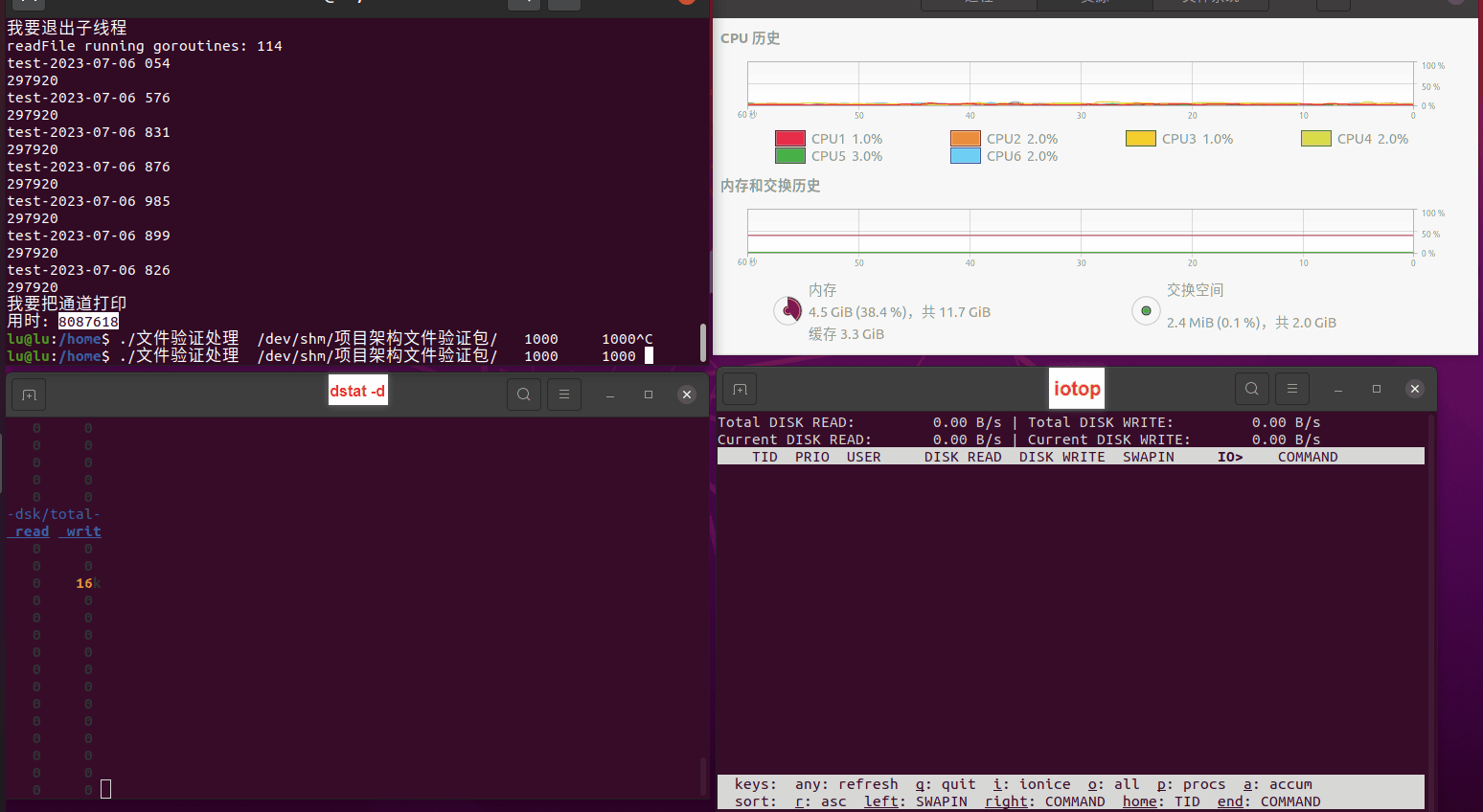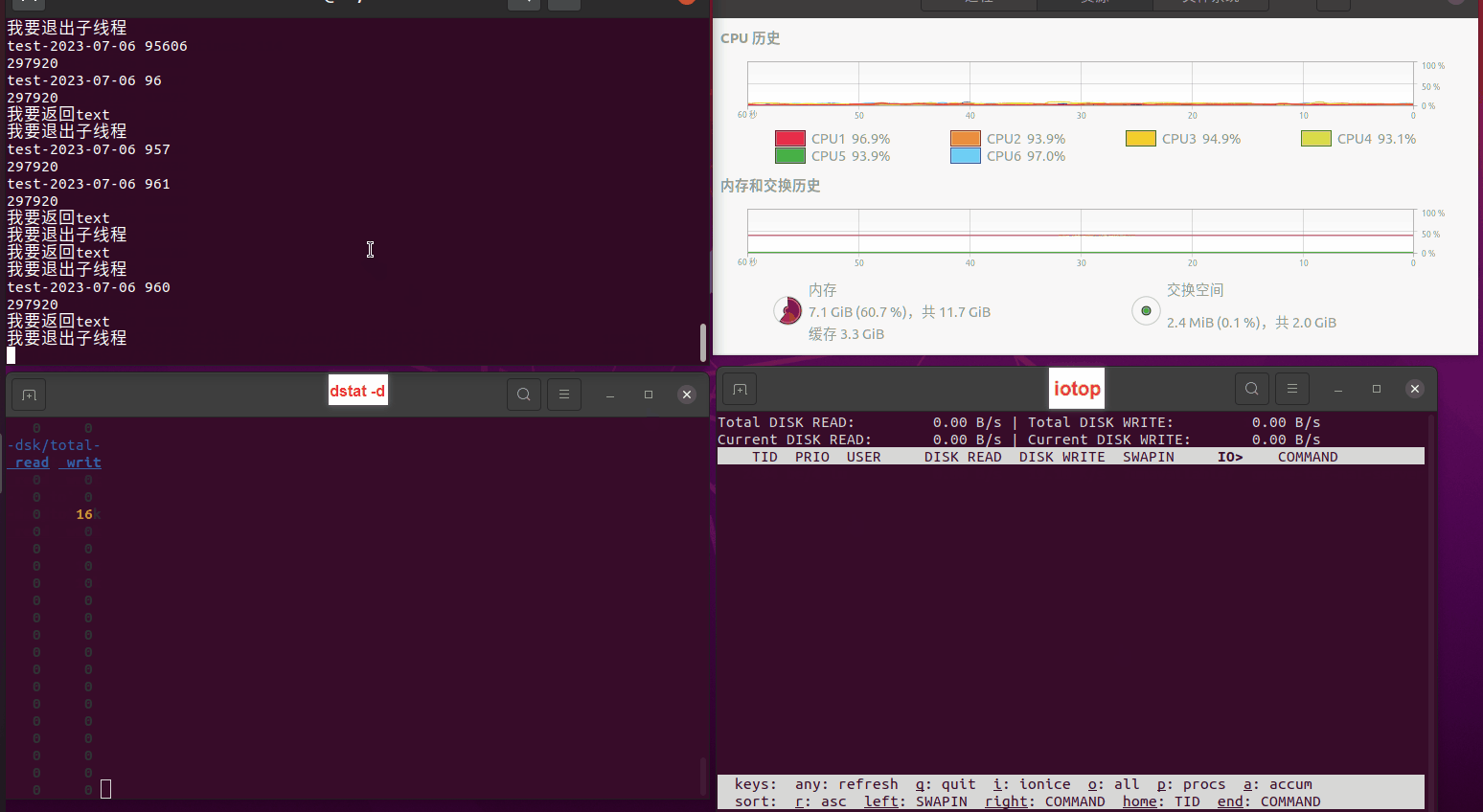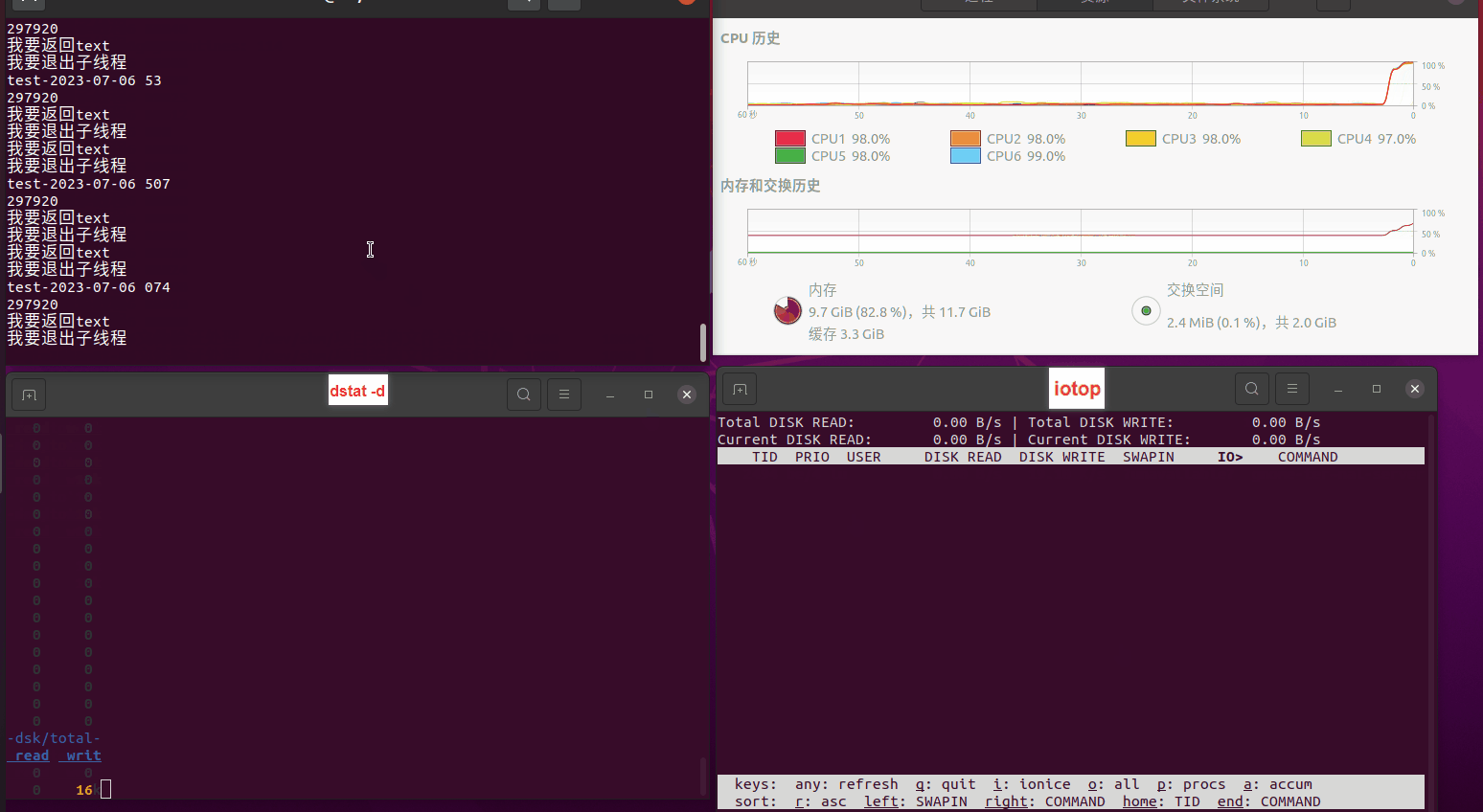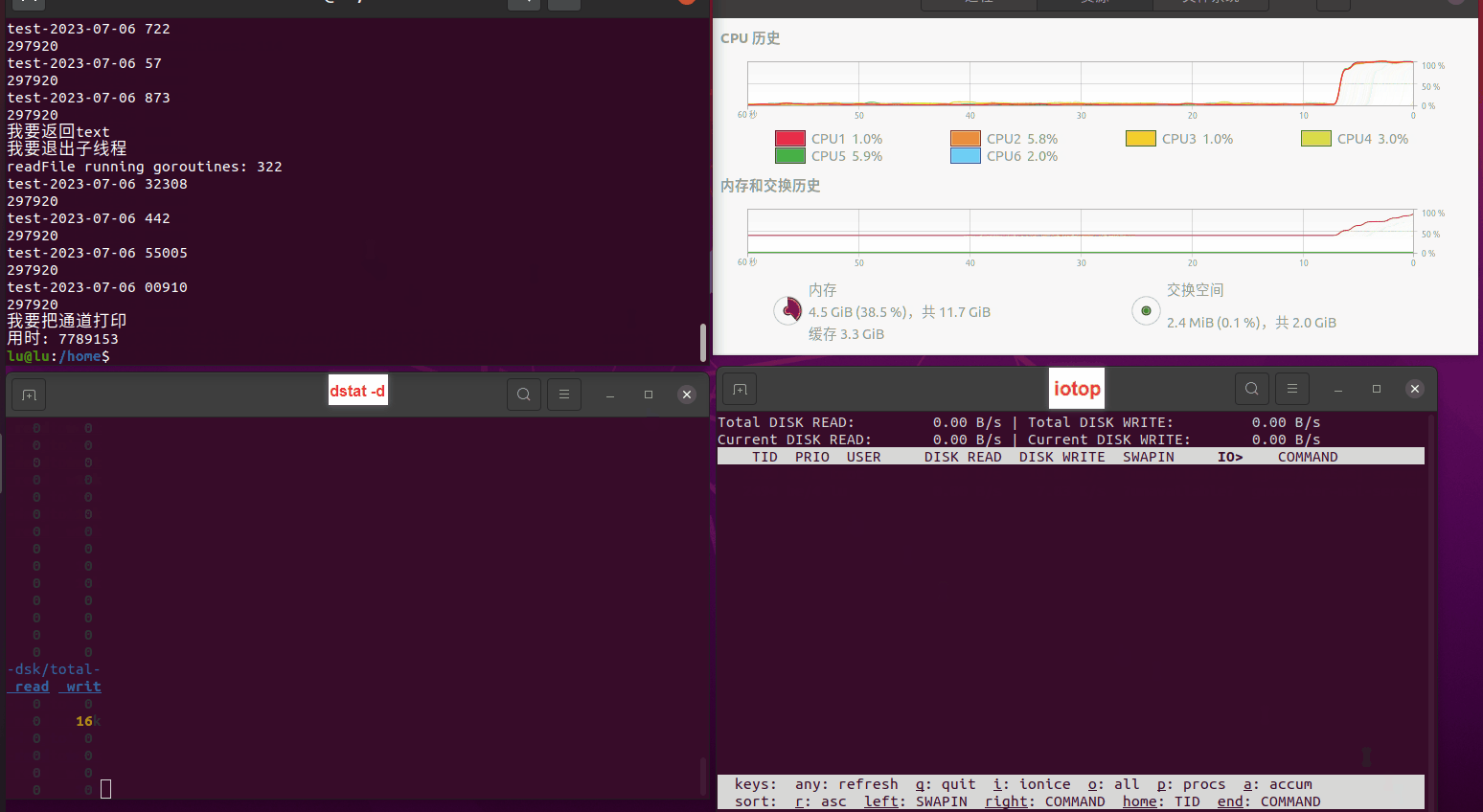
使用相同测试包和代码段2,越 4.8G, 分别在磁盘组 和 tmpfs组, 进行对照实验。
测试结果如下:
磁盘组:
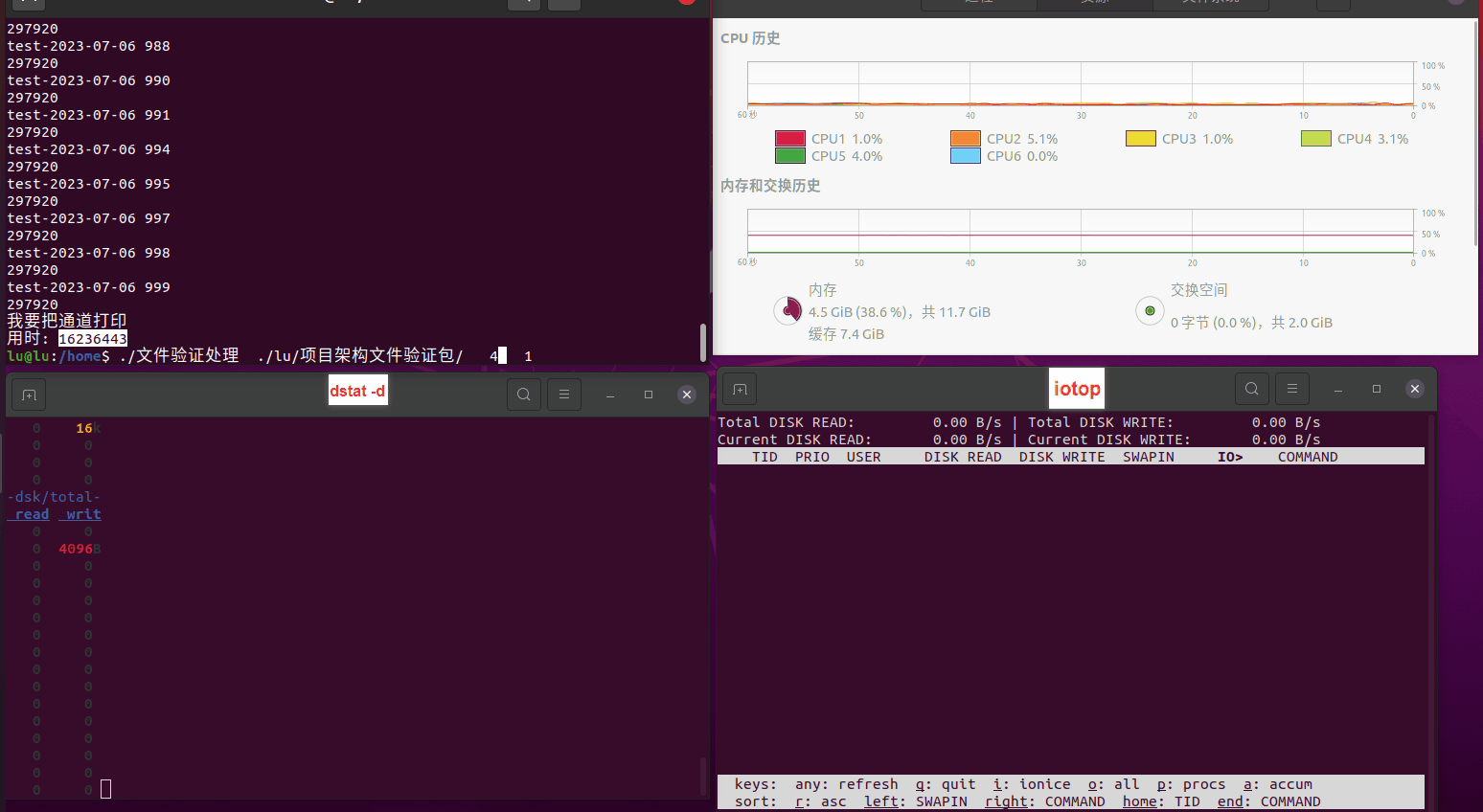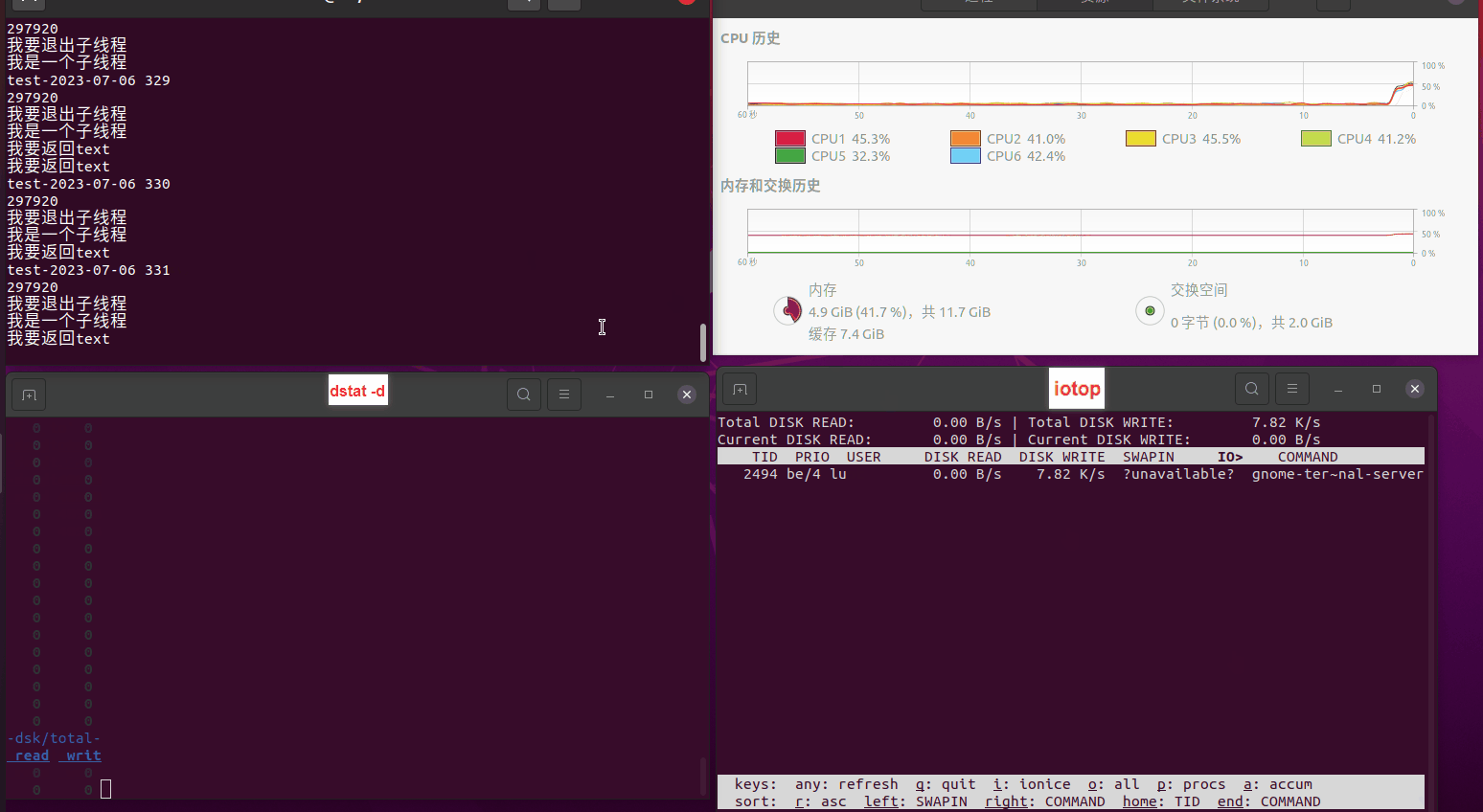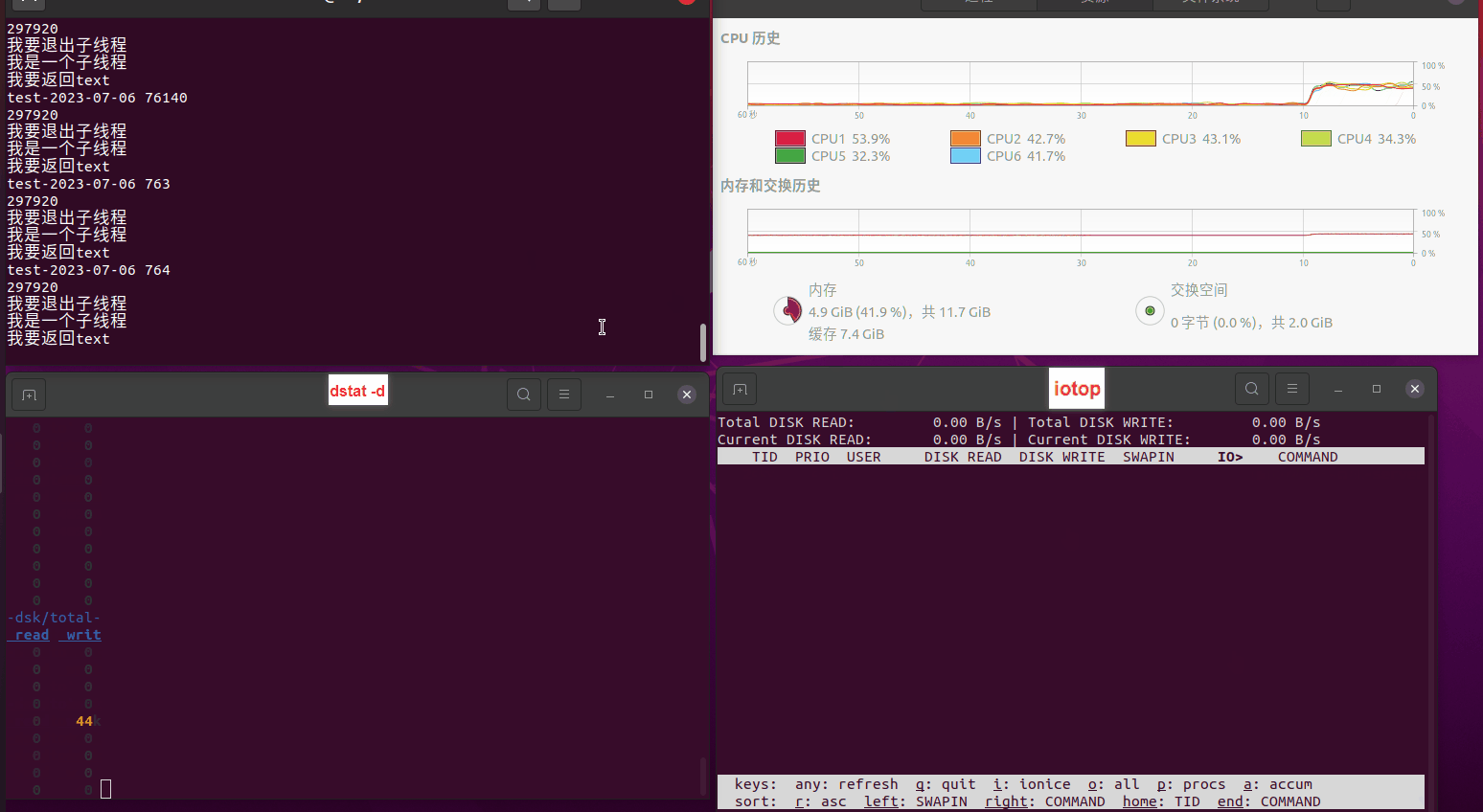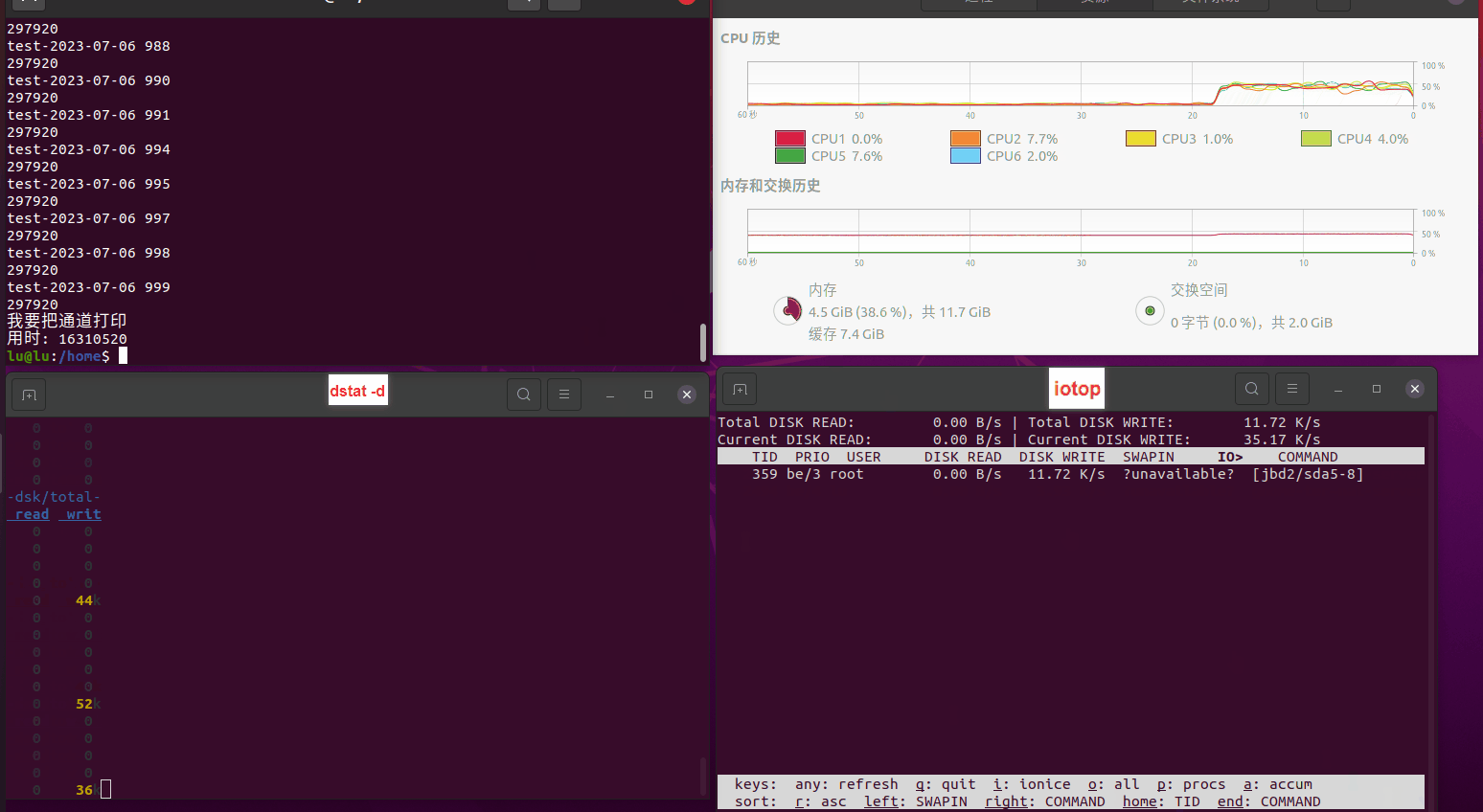
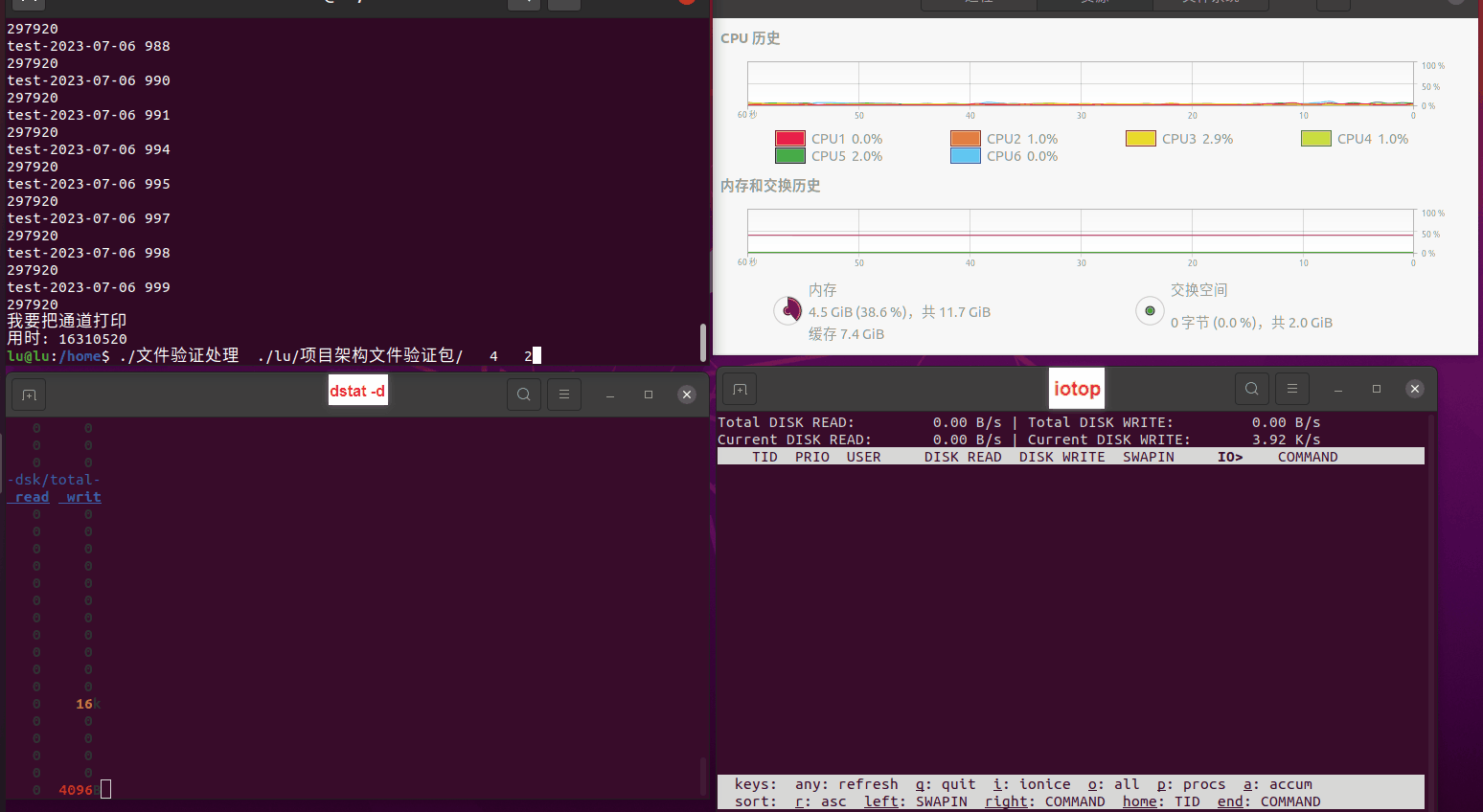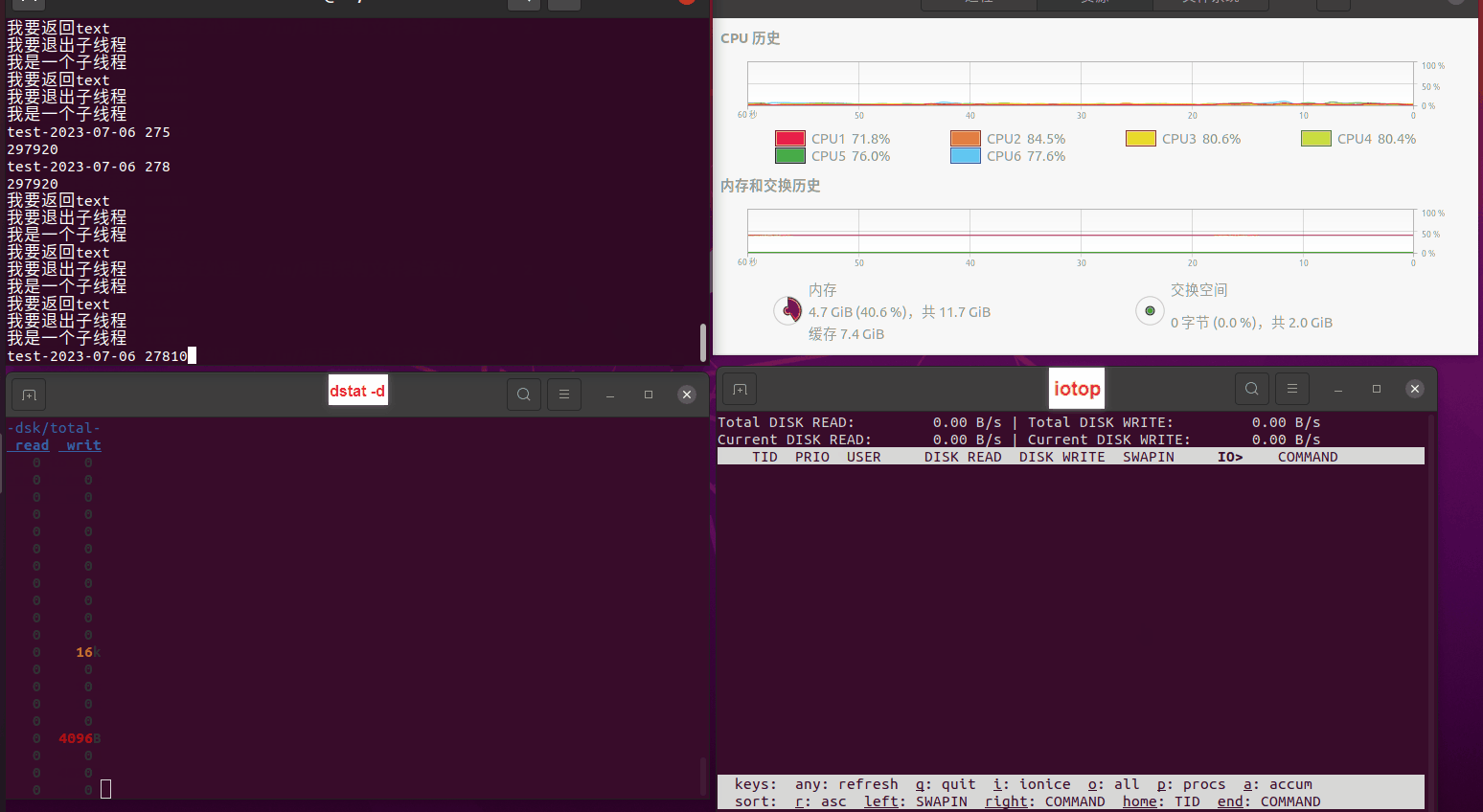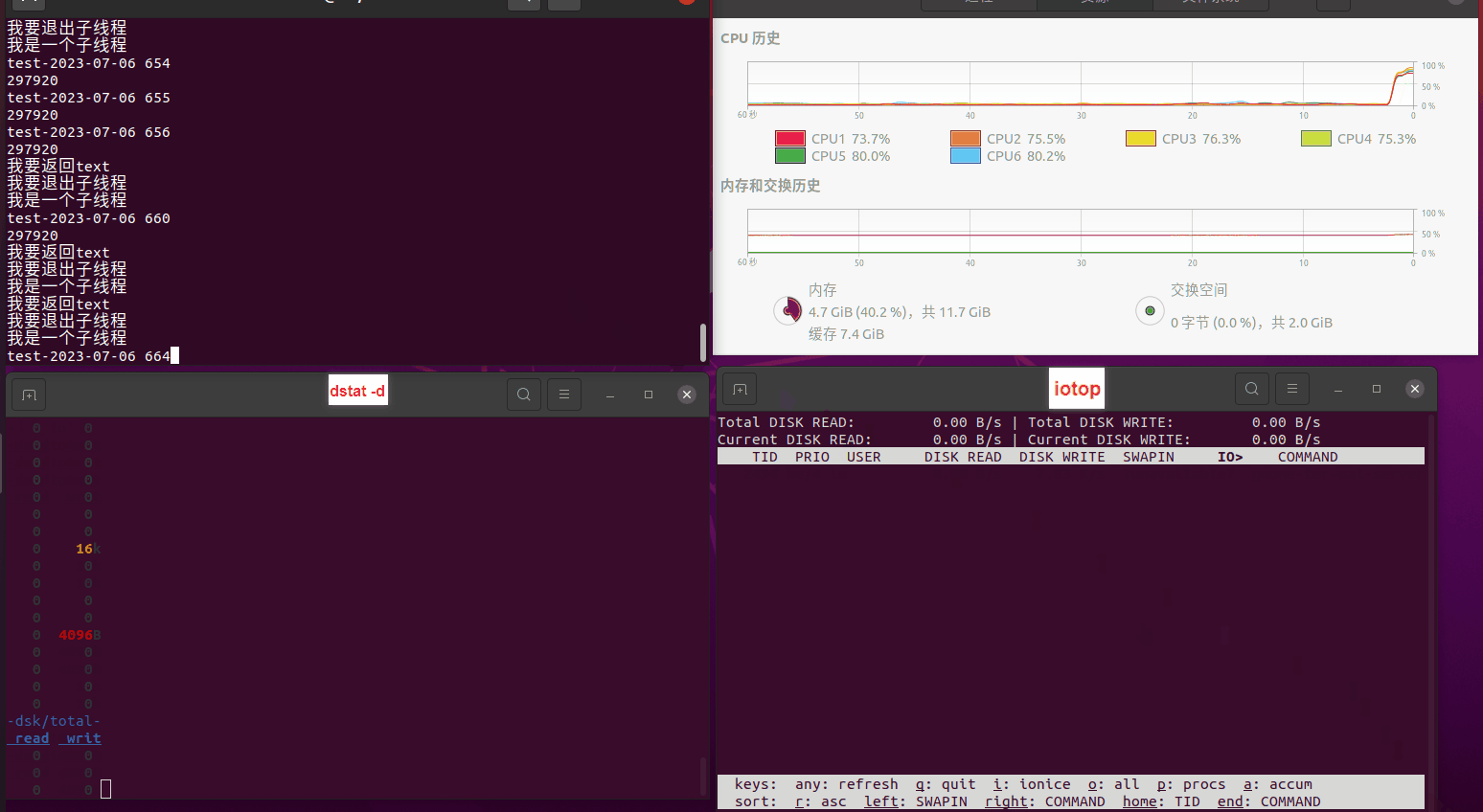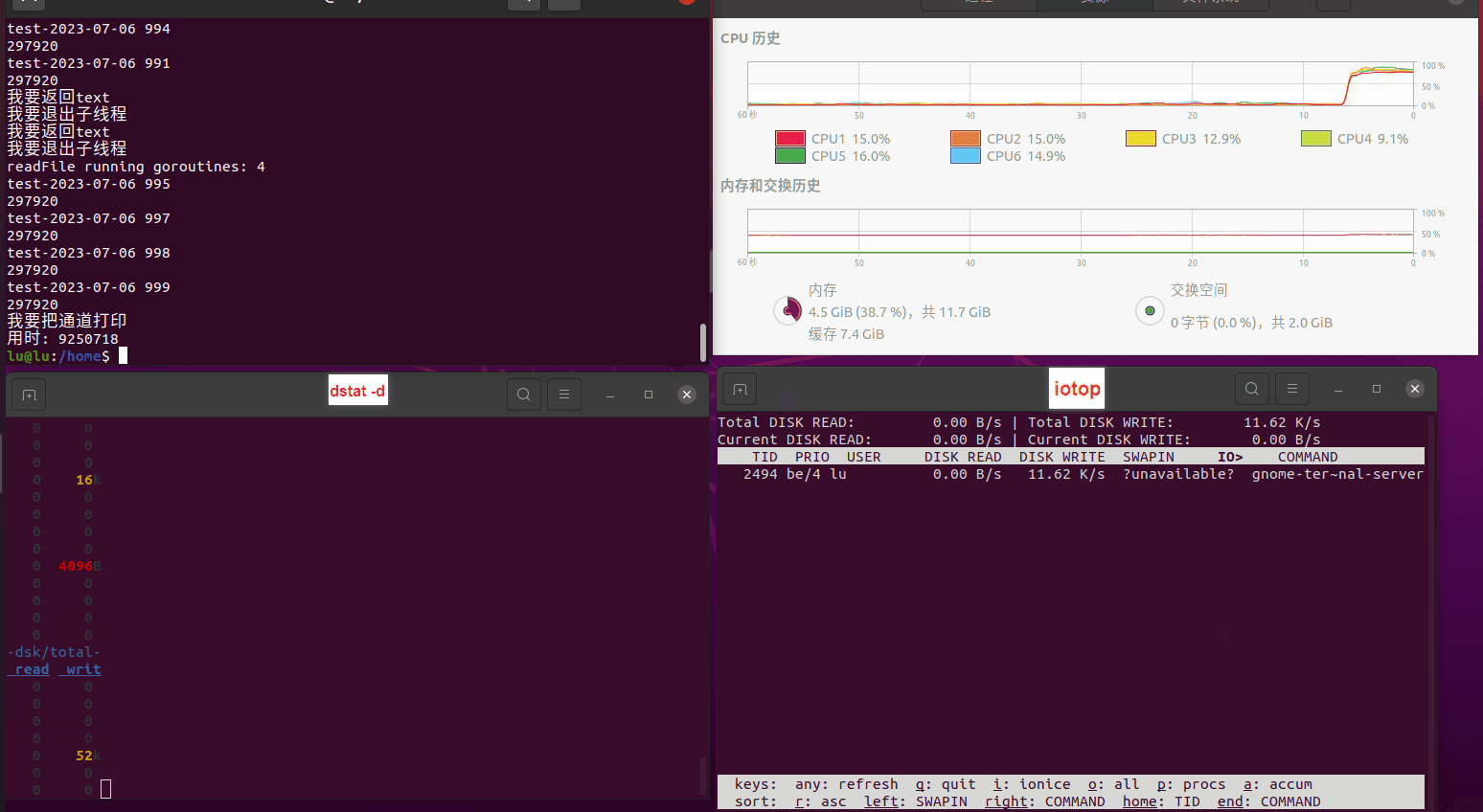
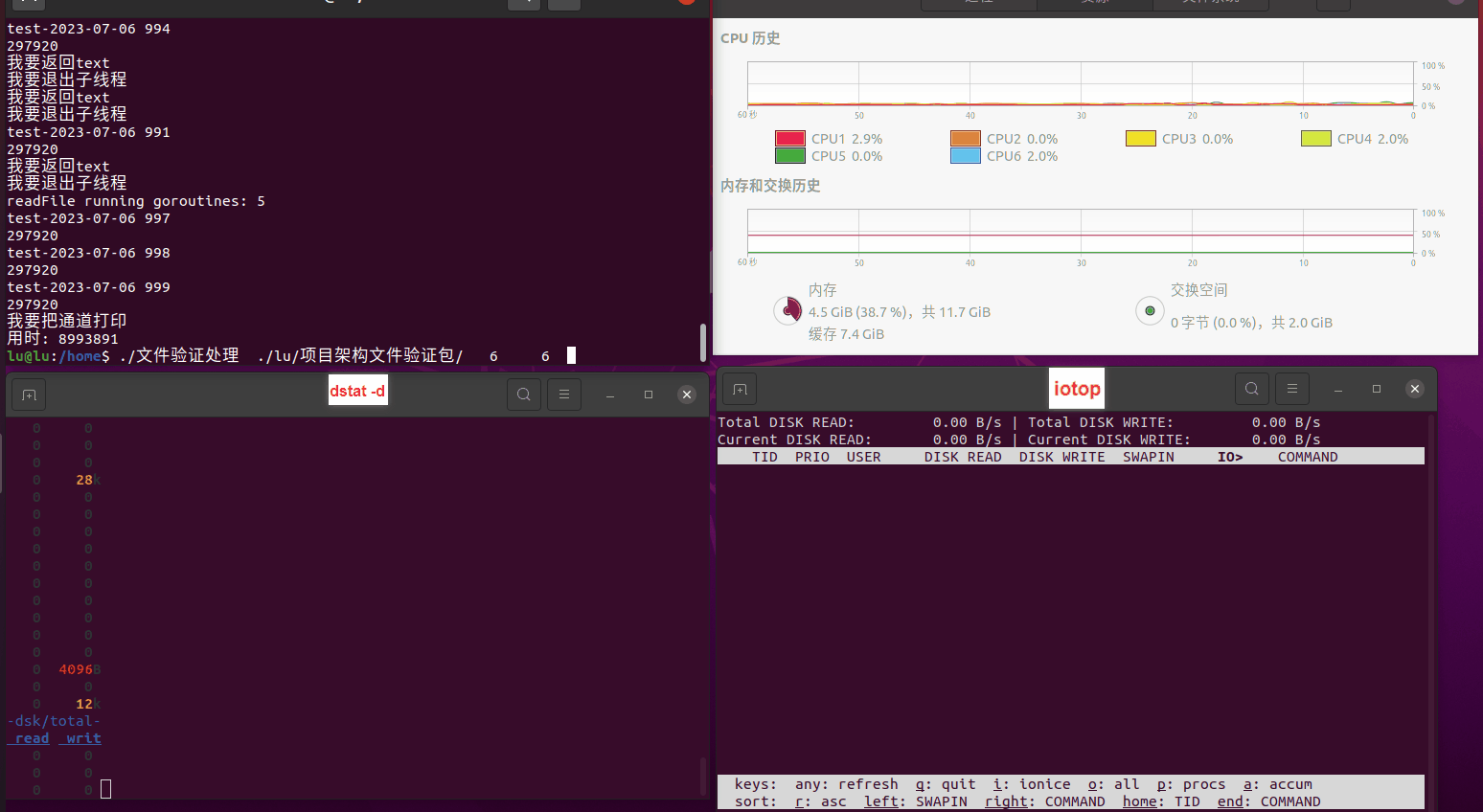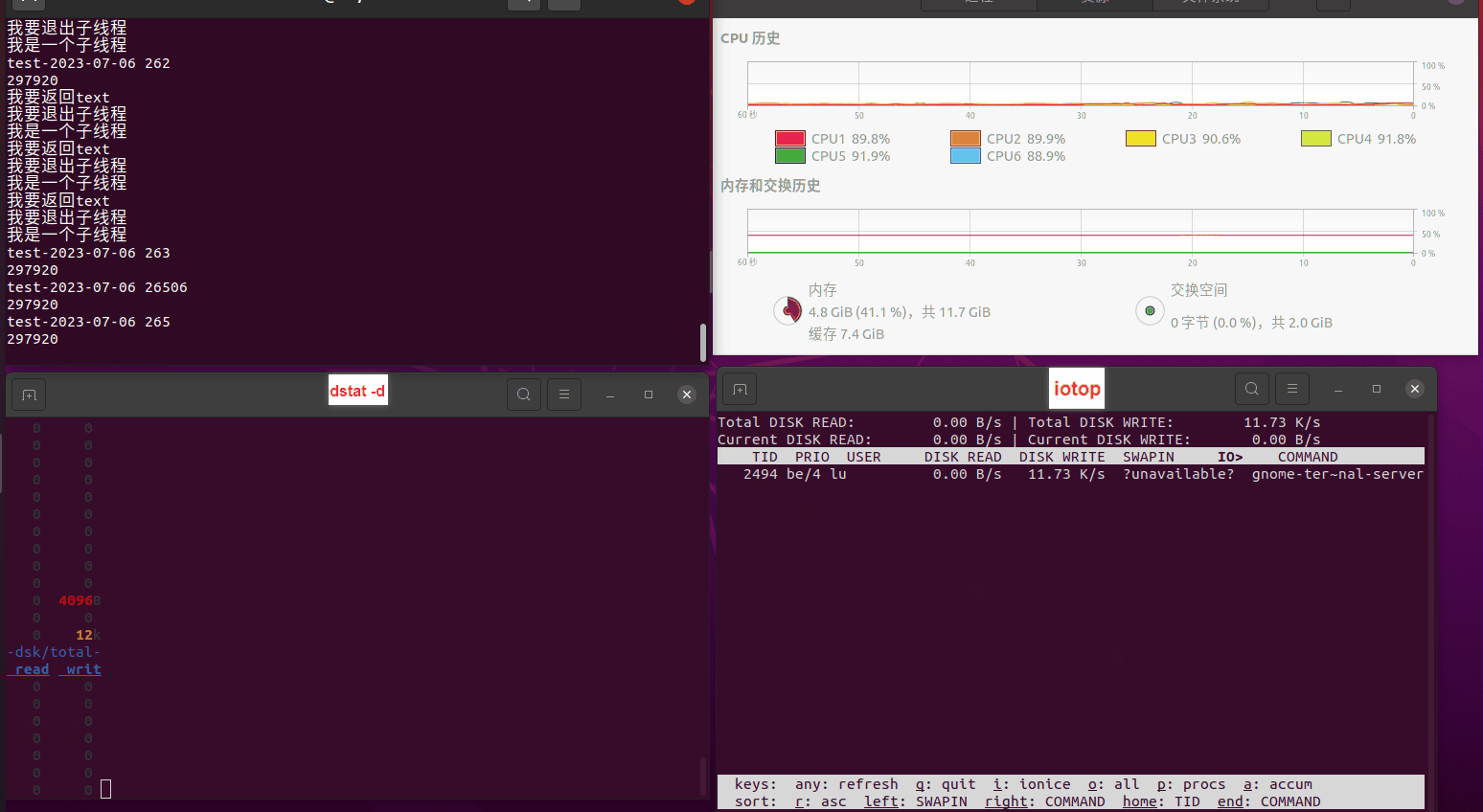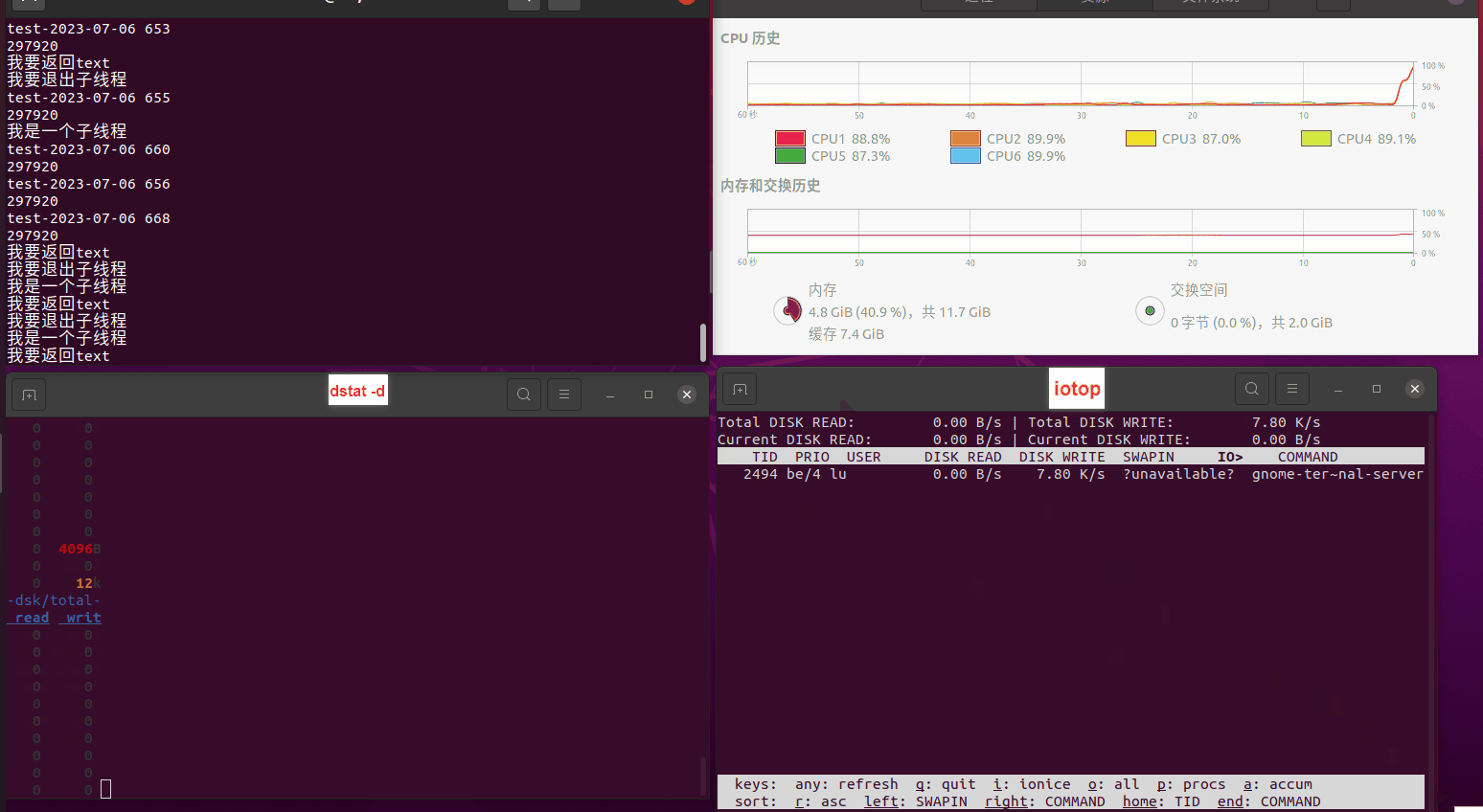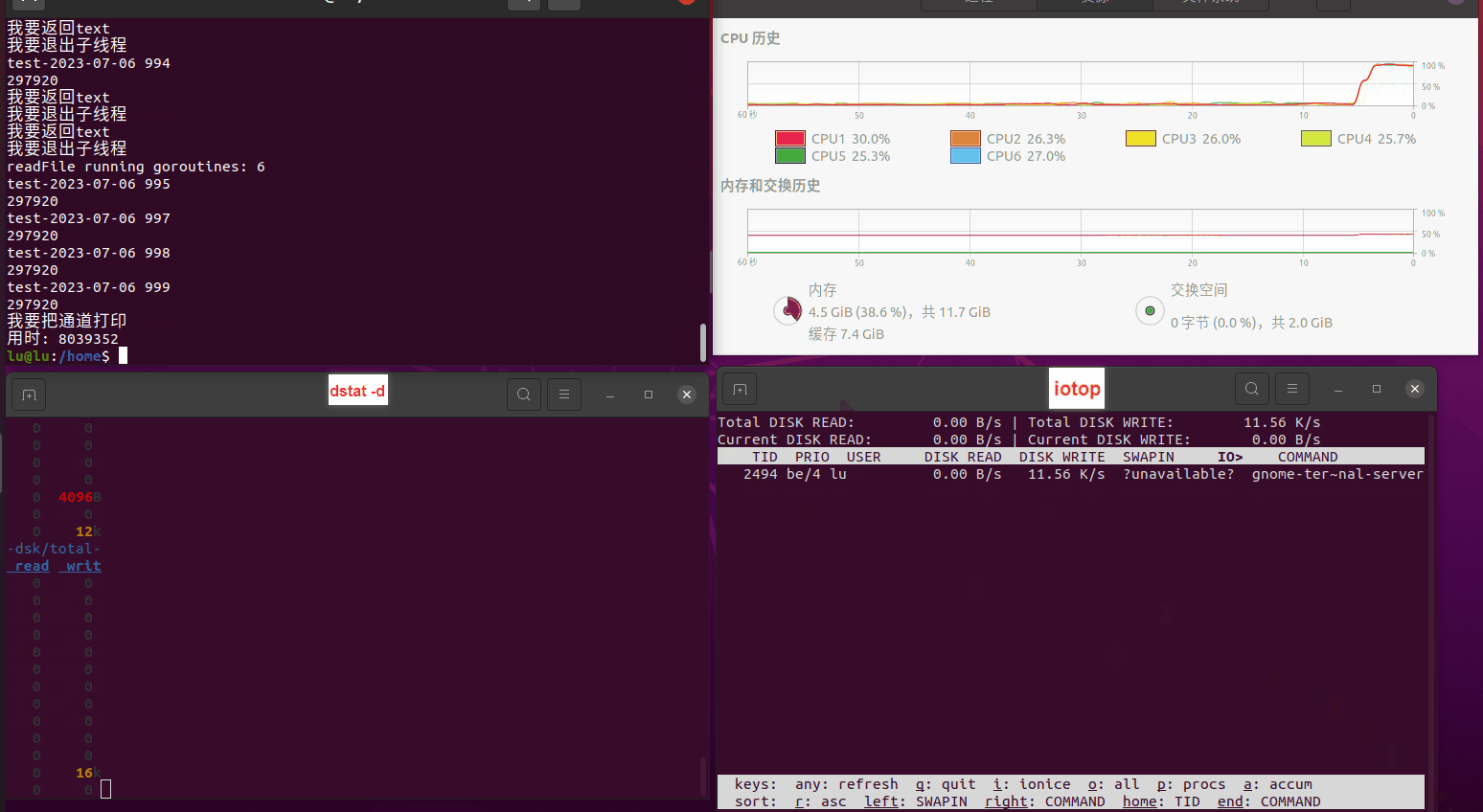
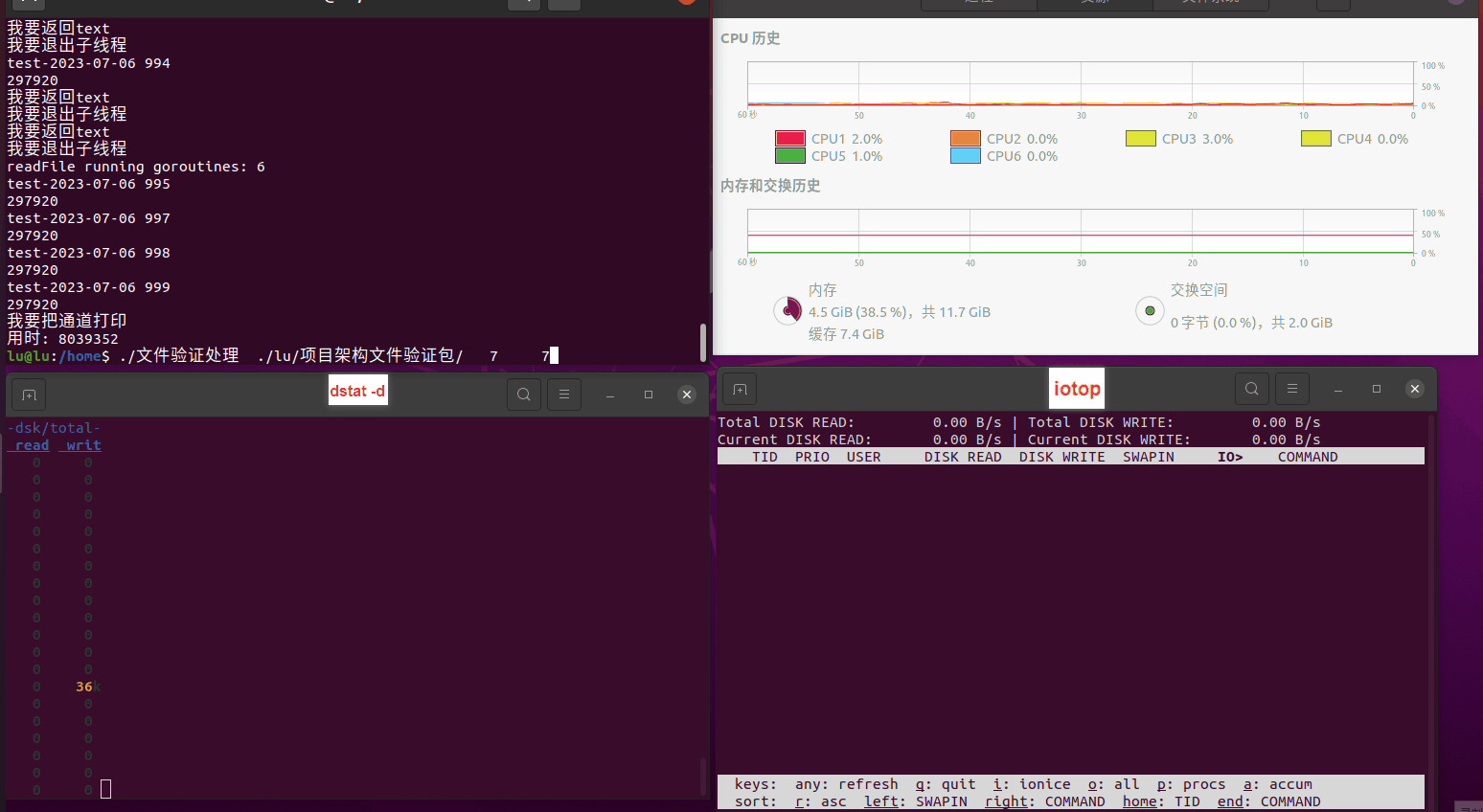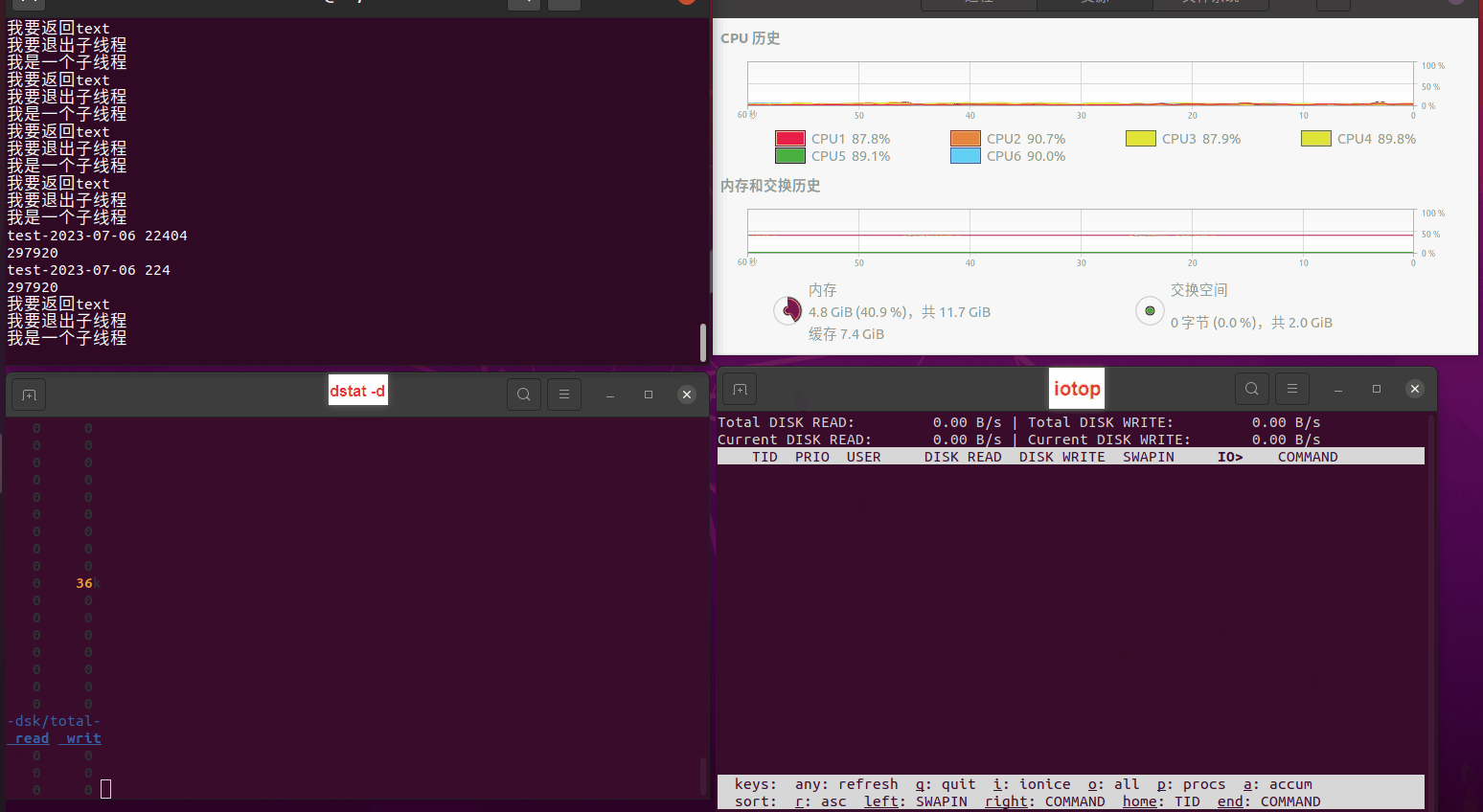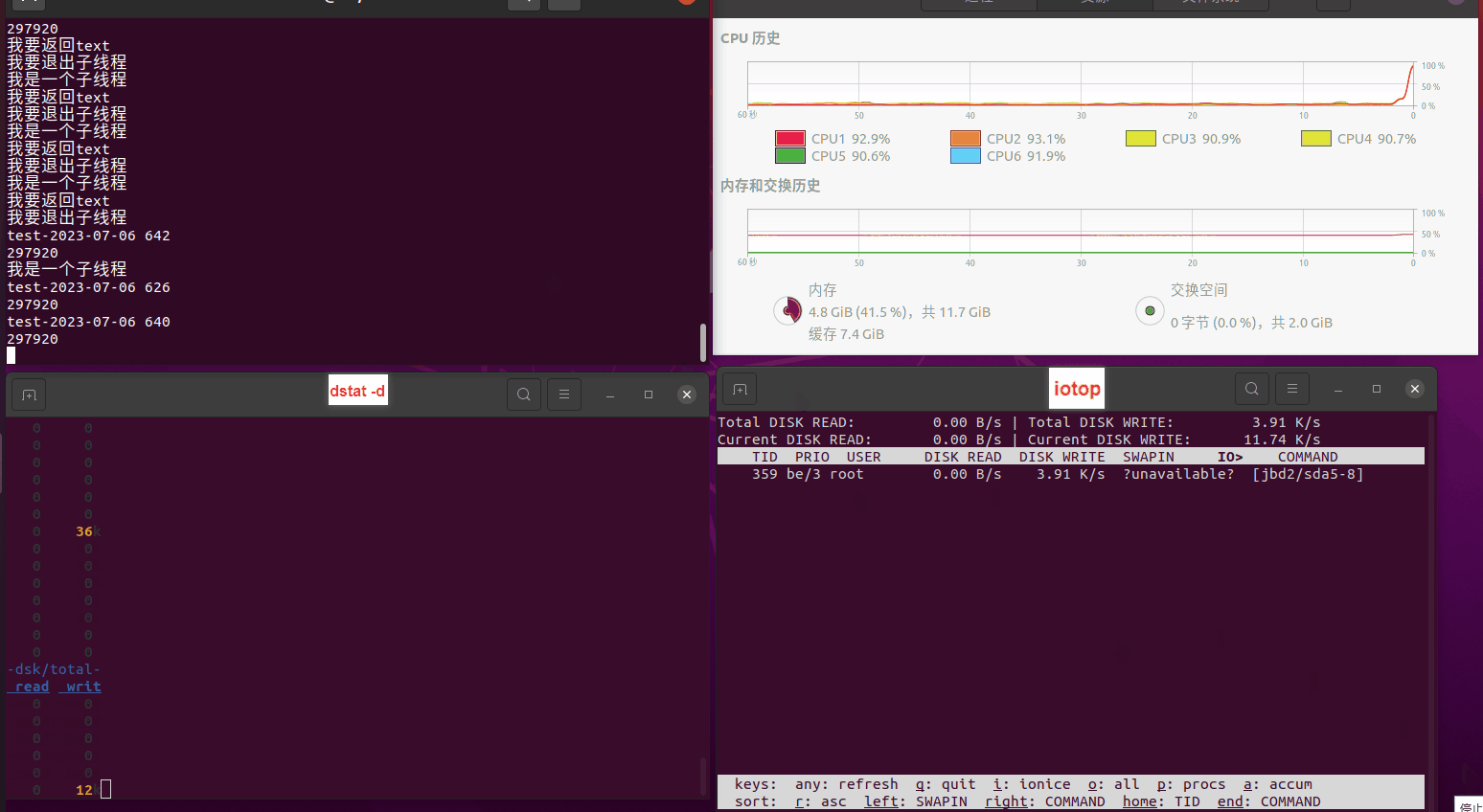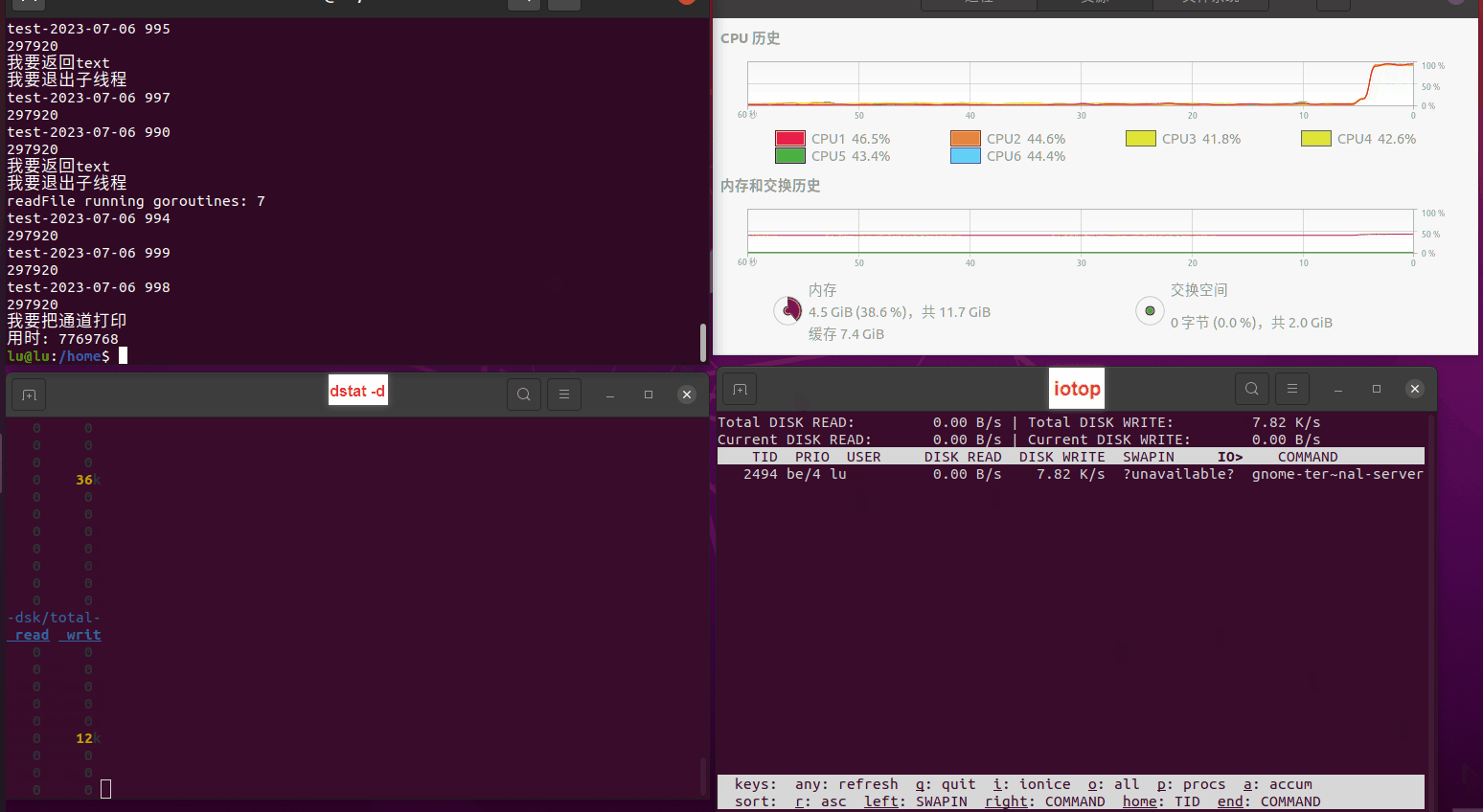
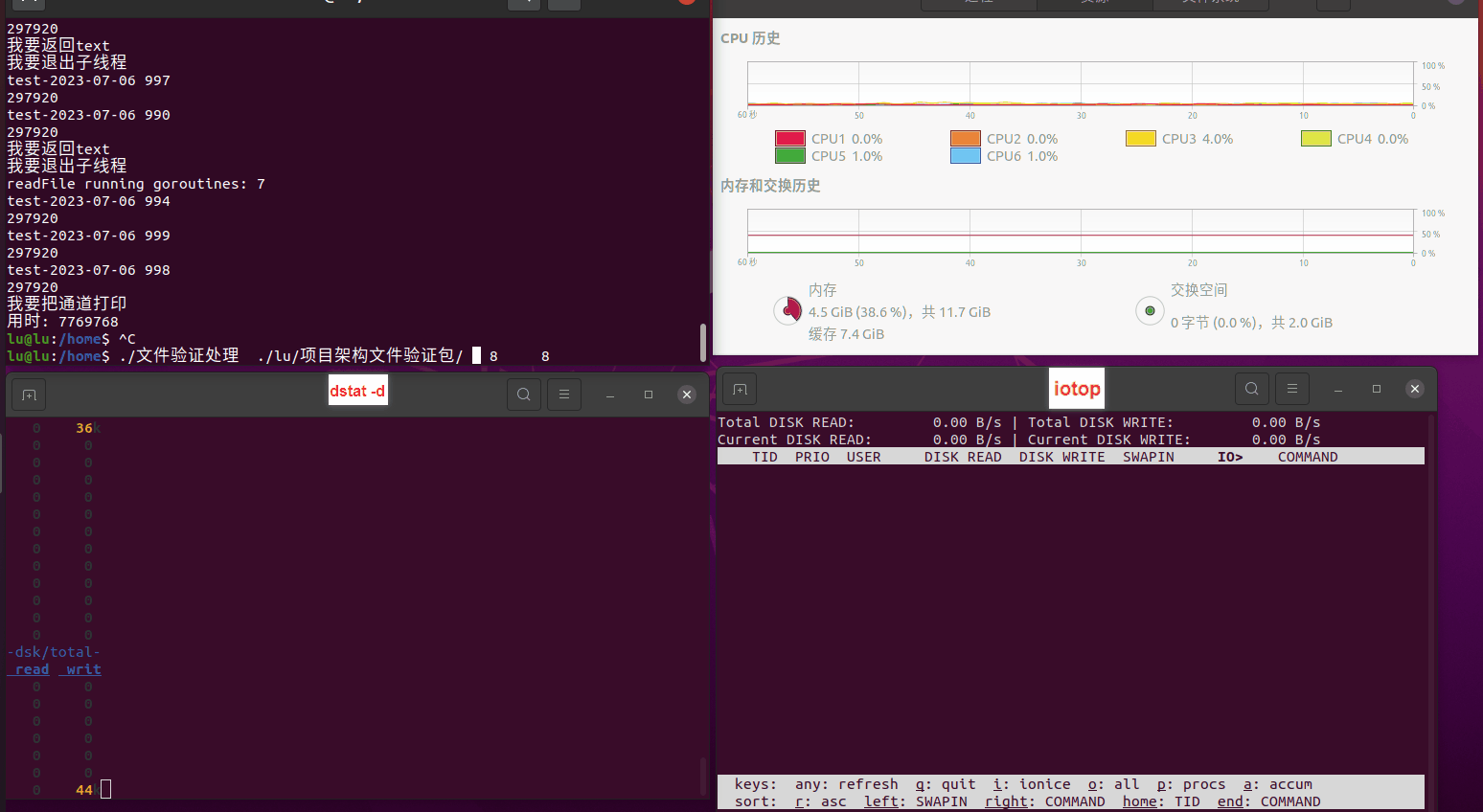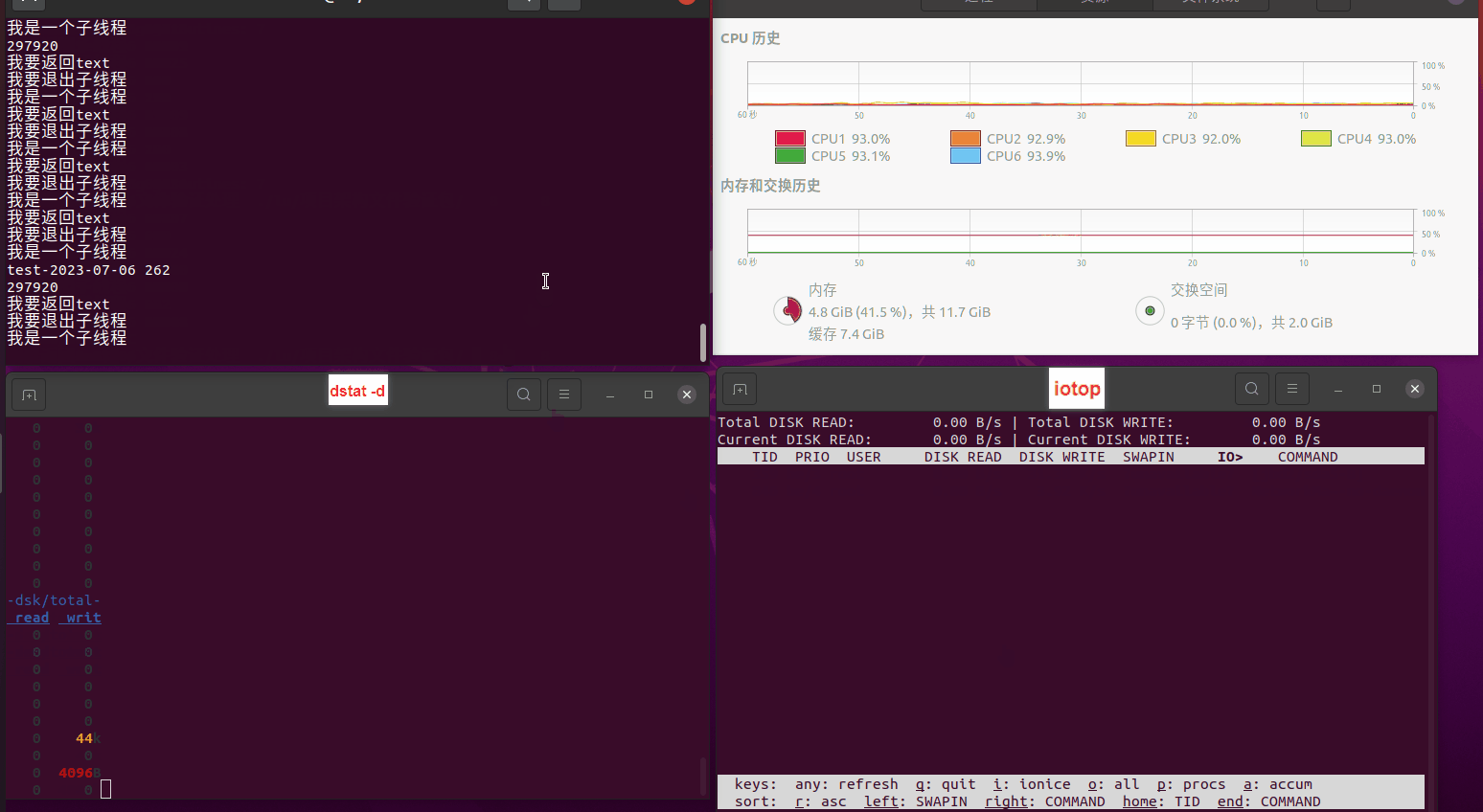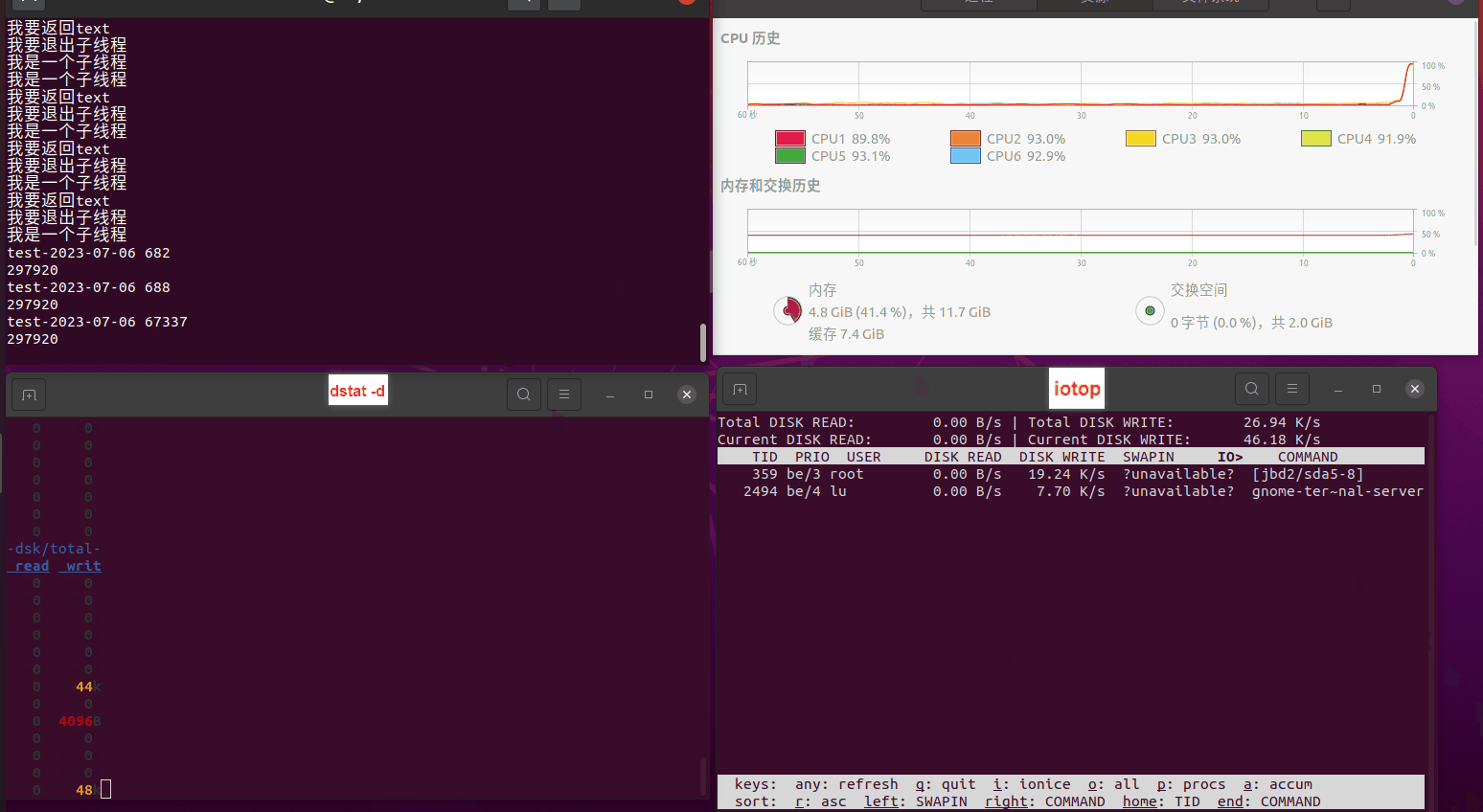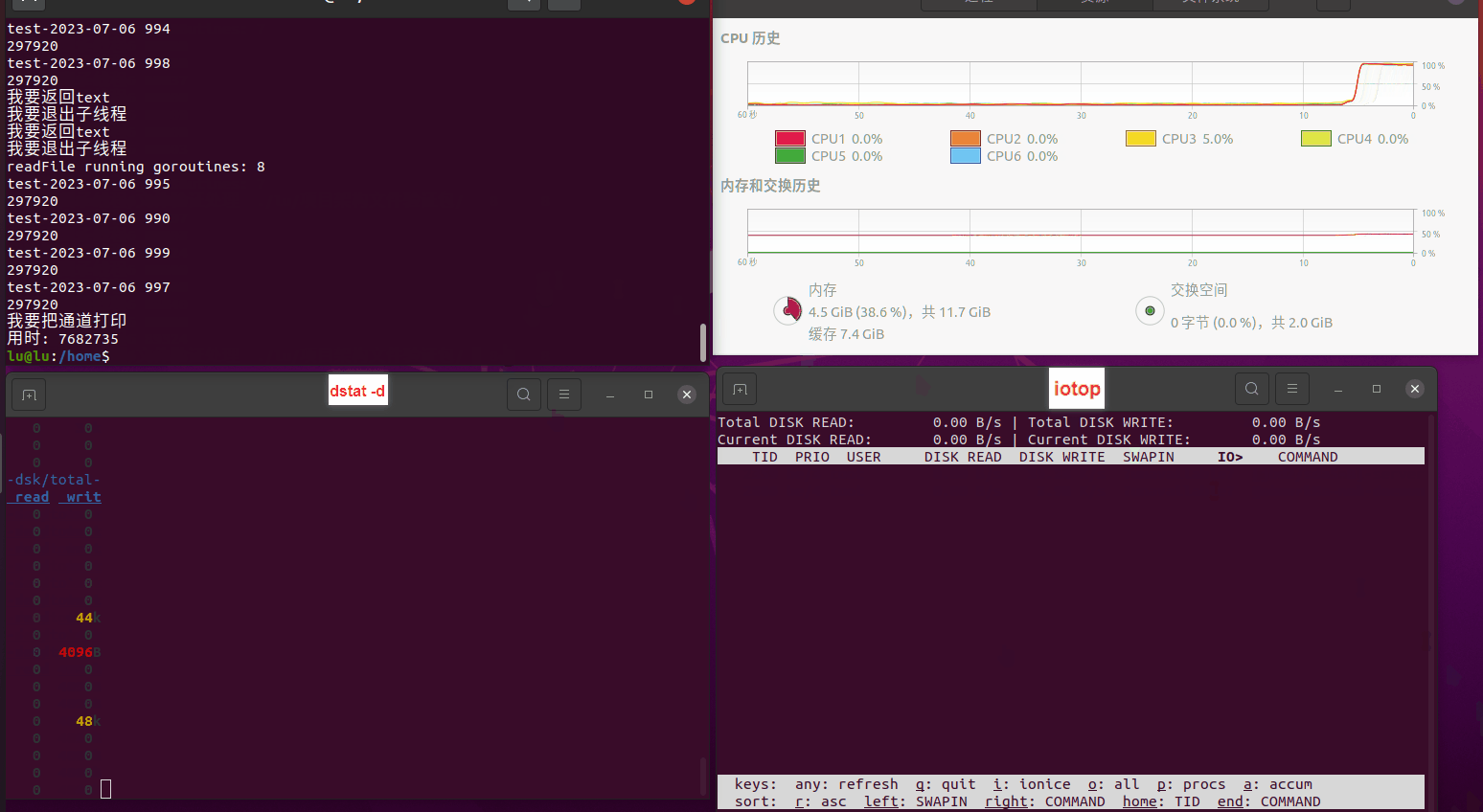
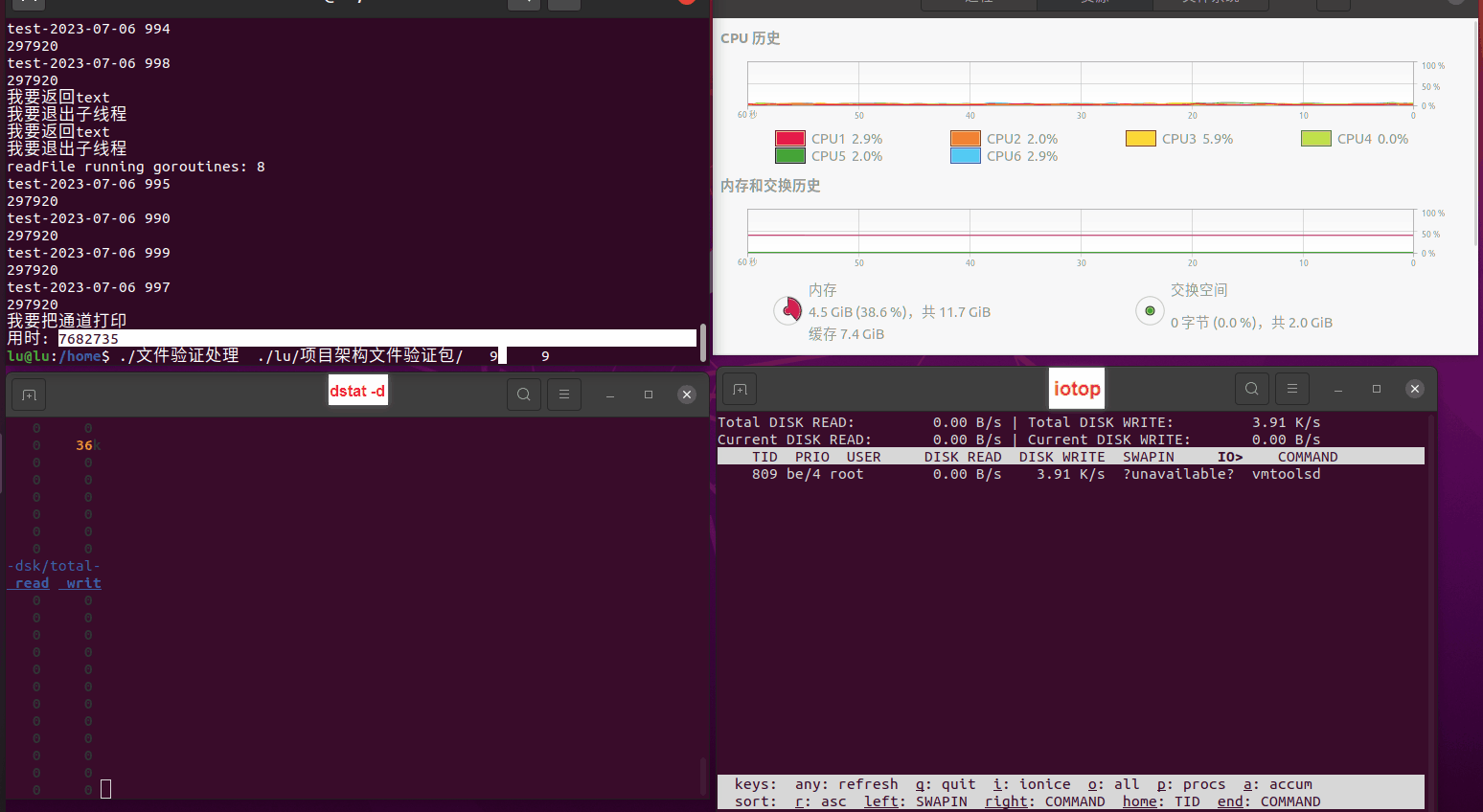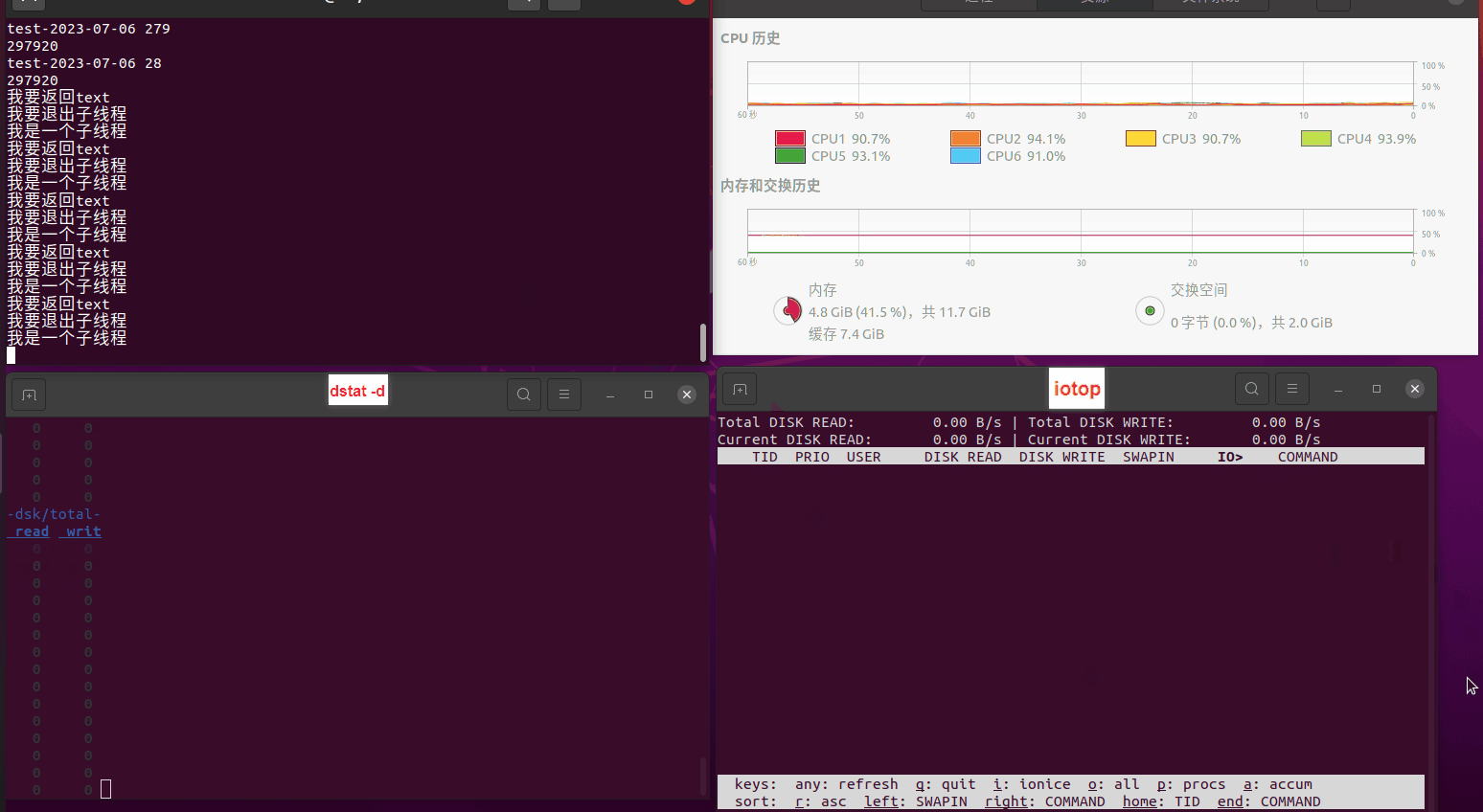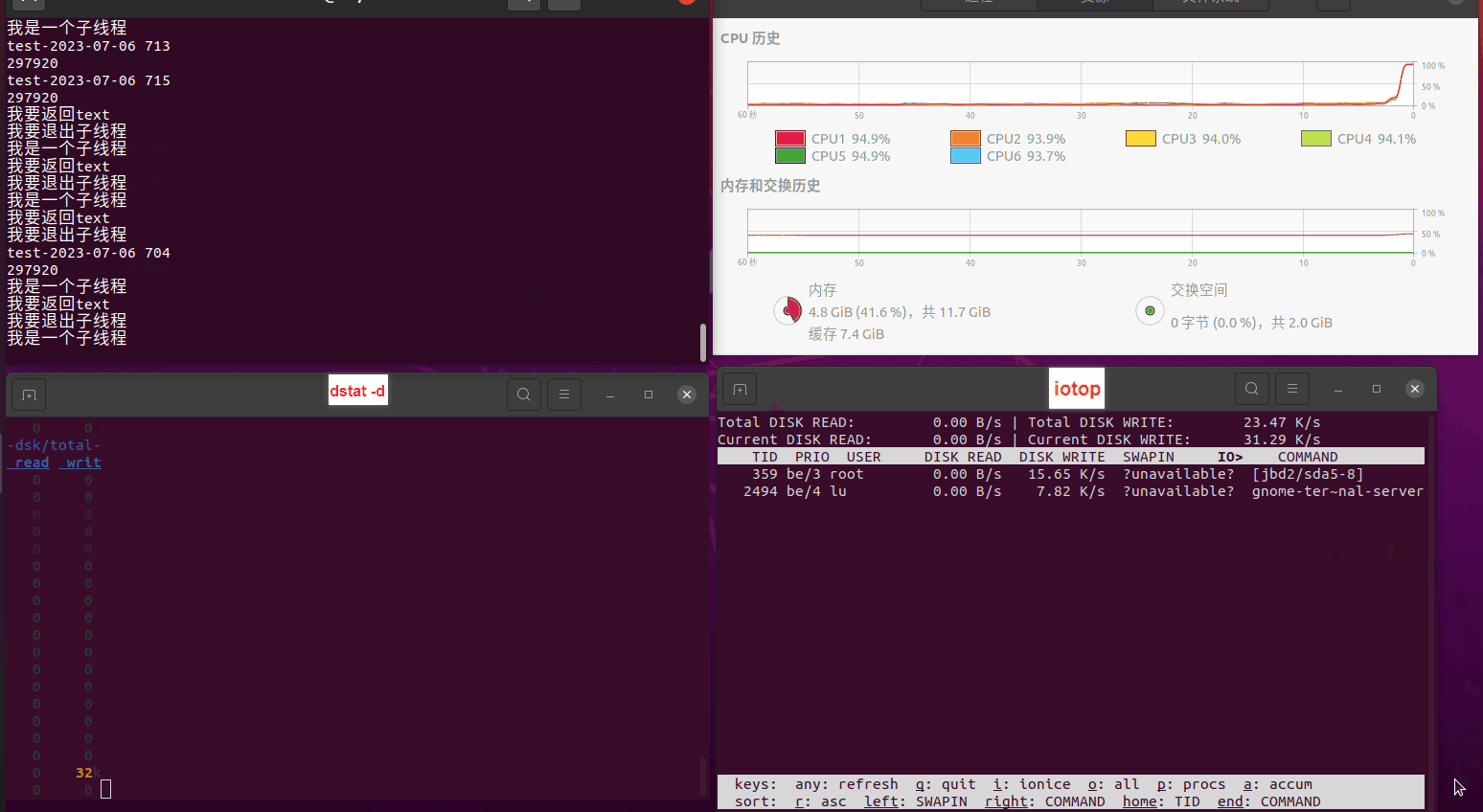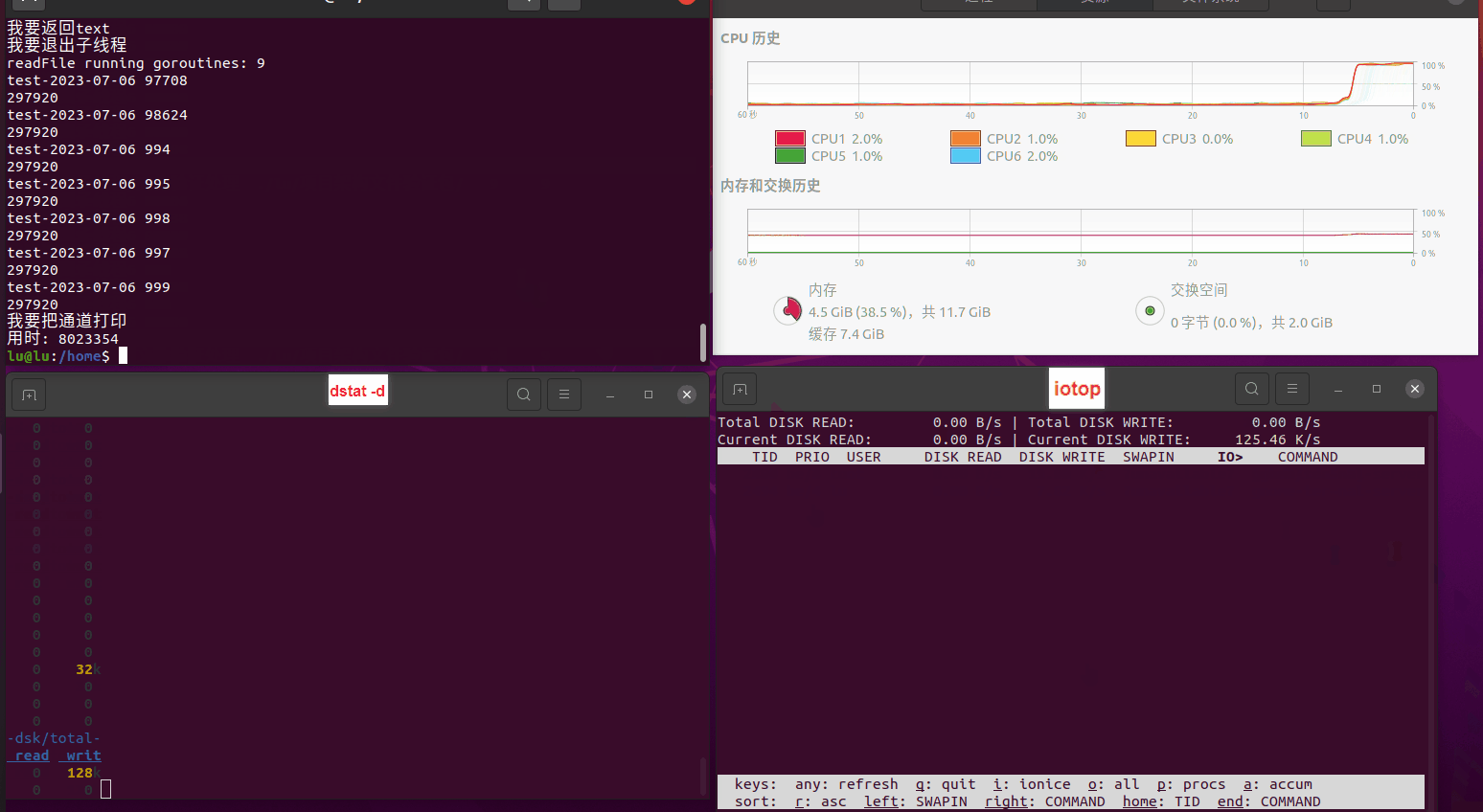
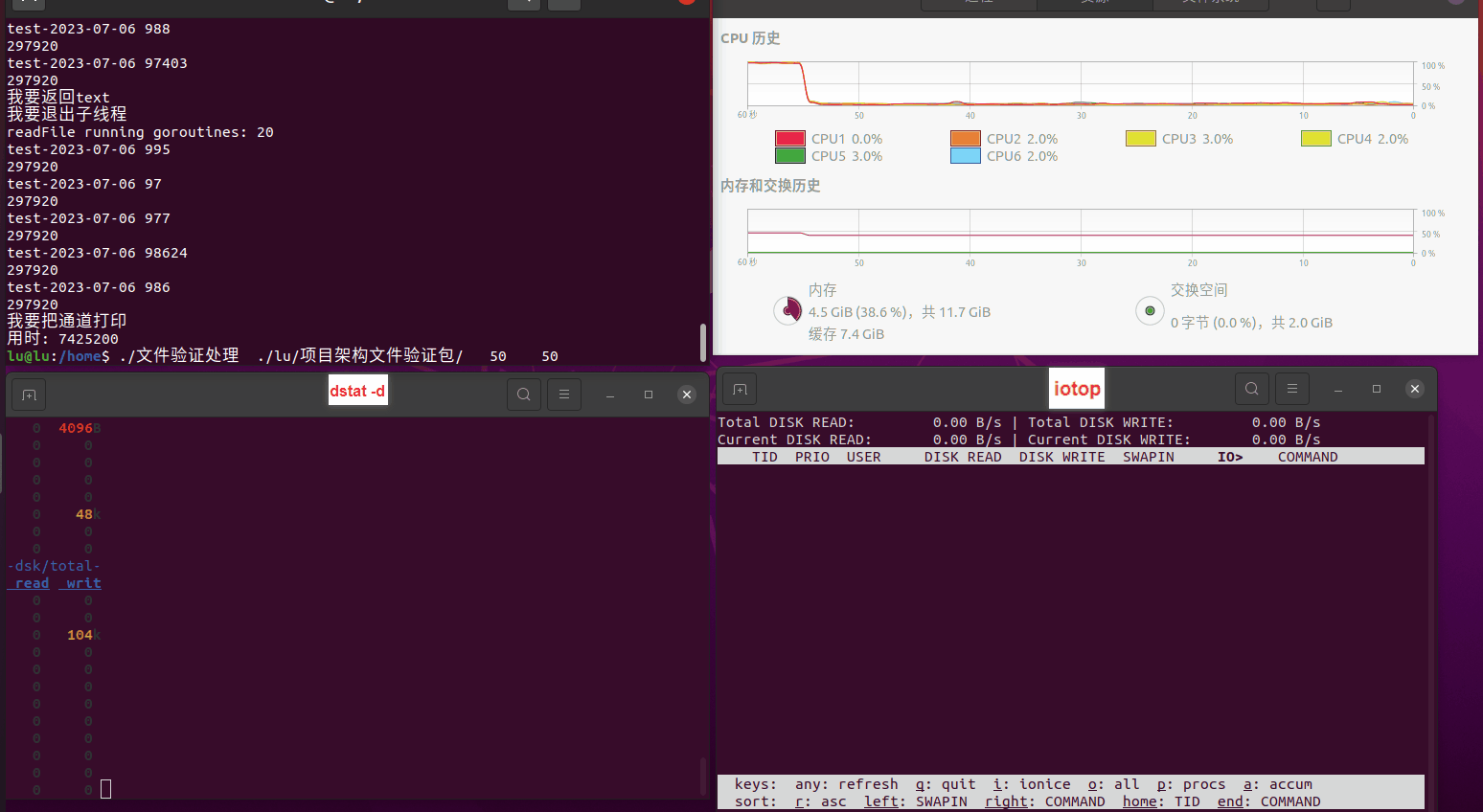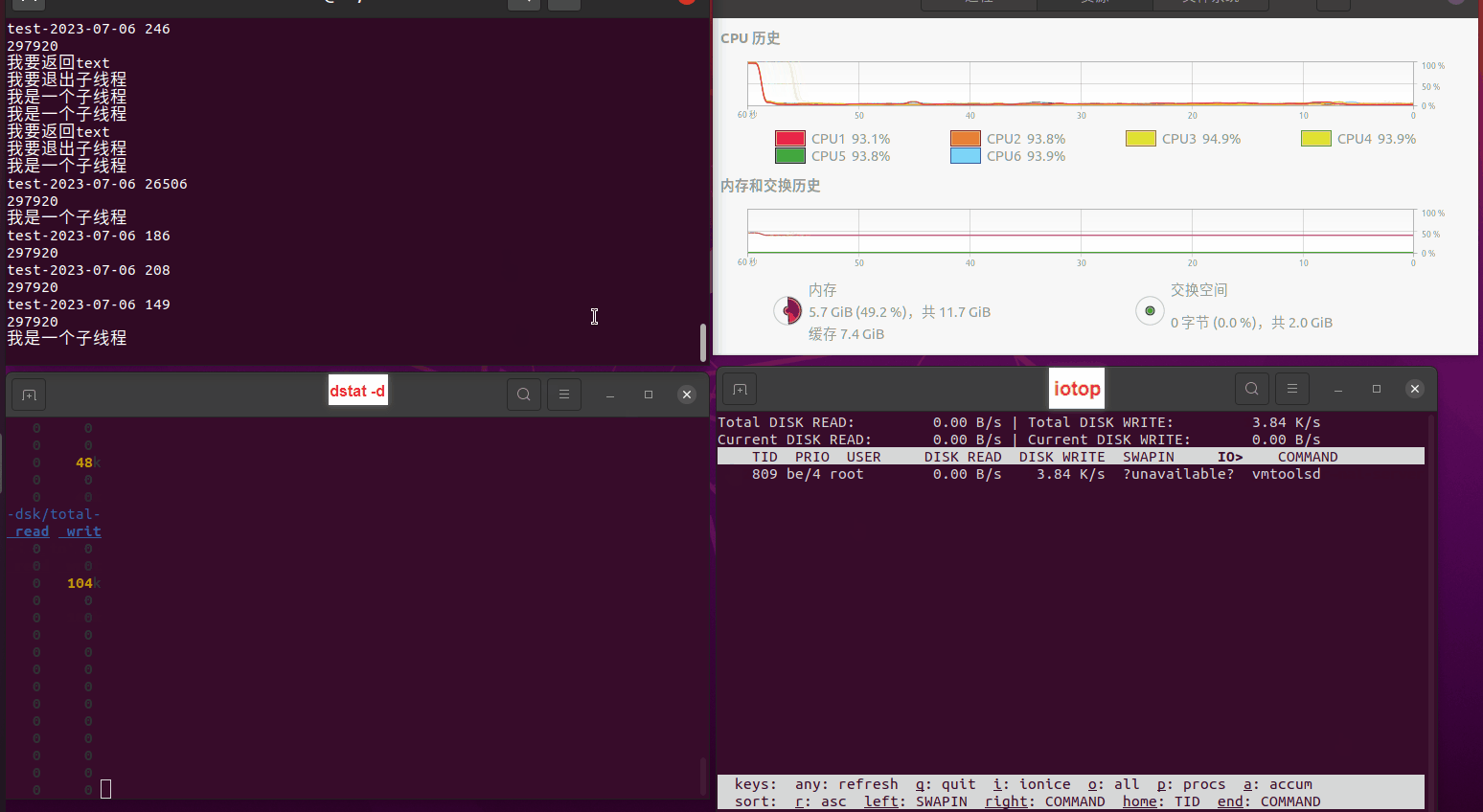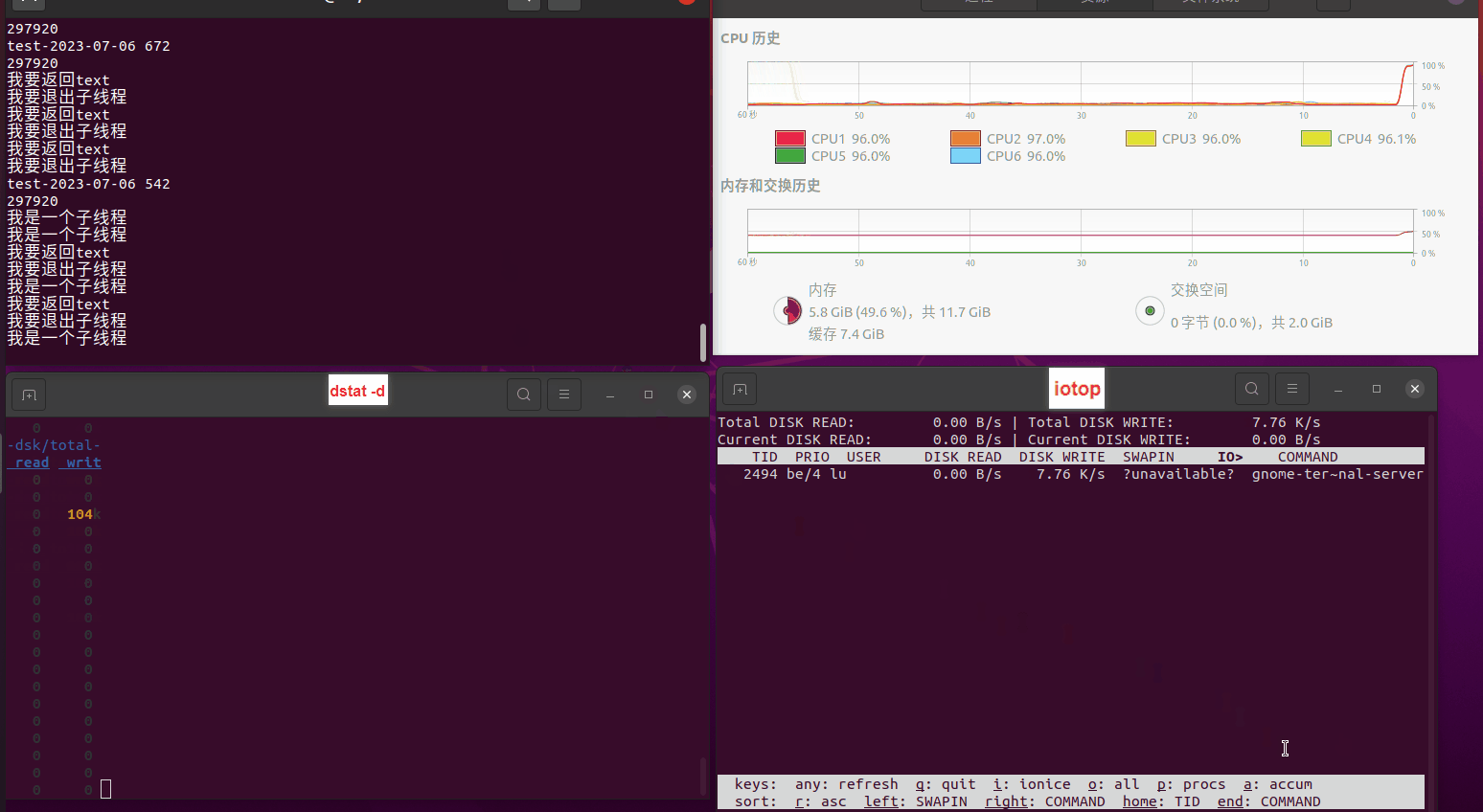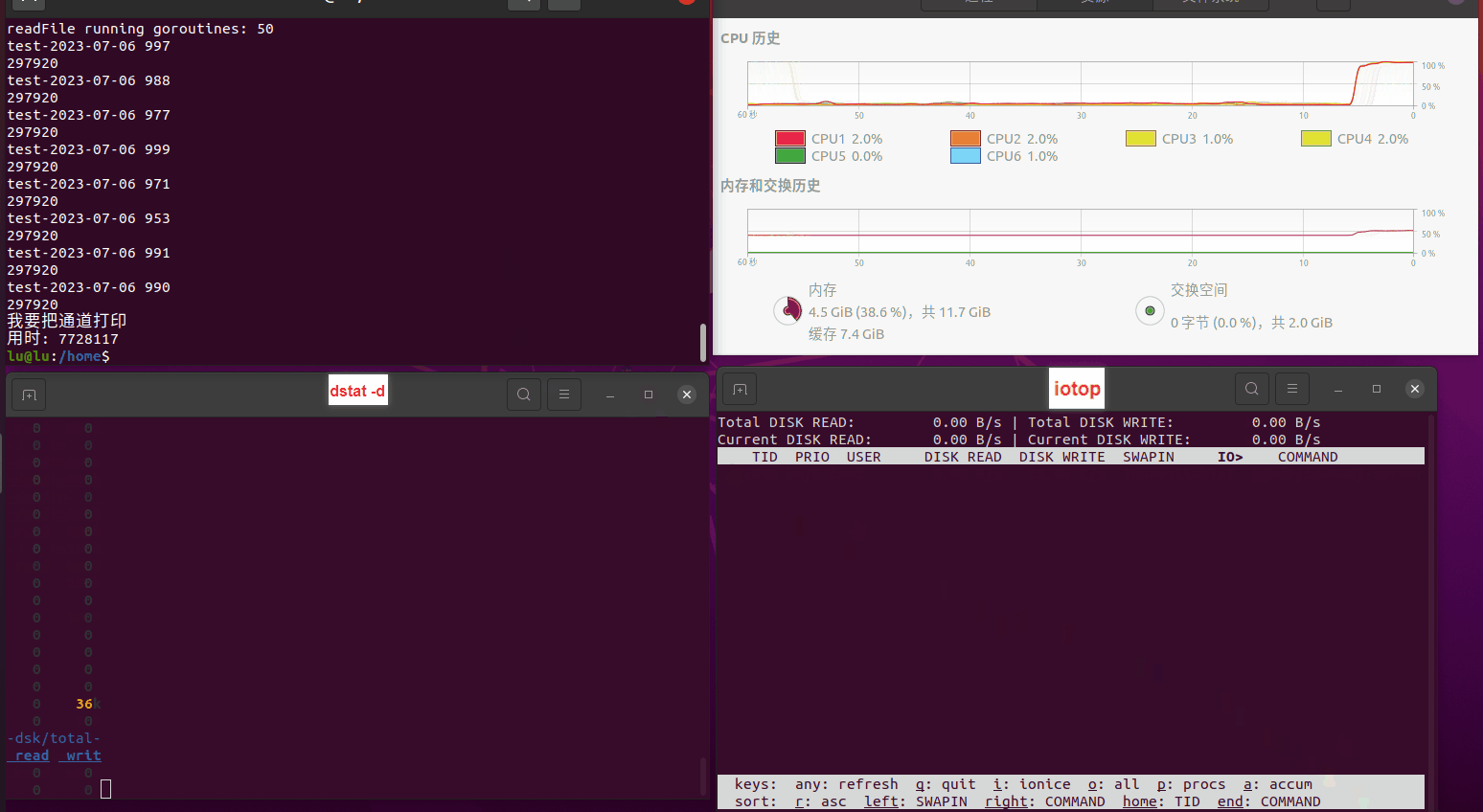
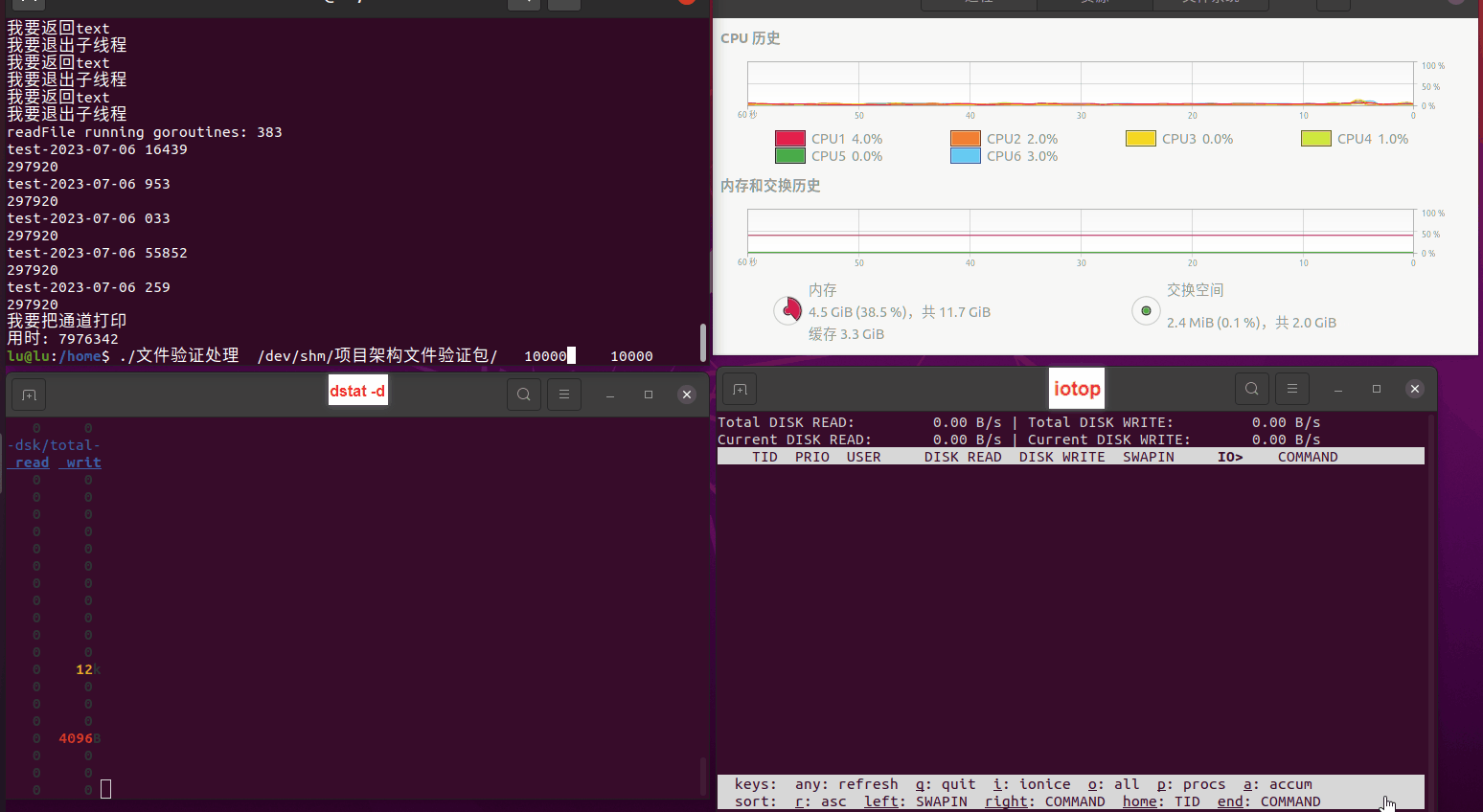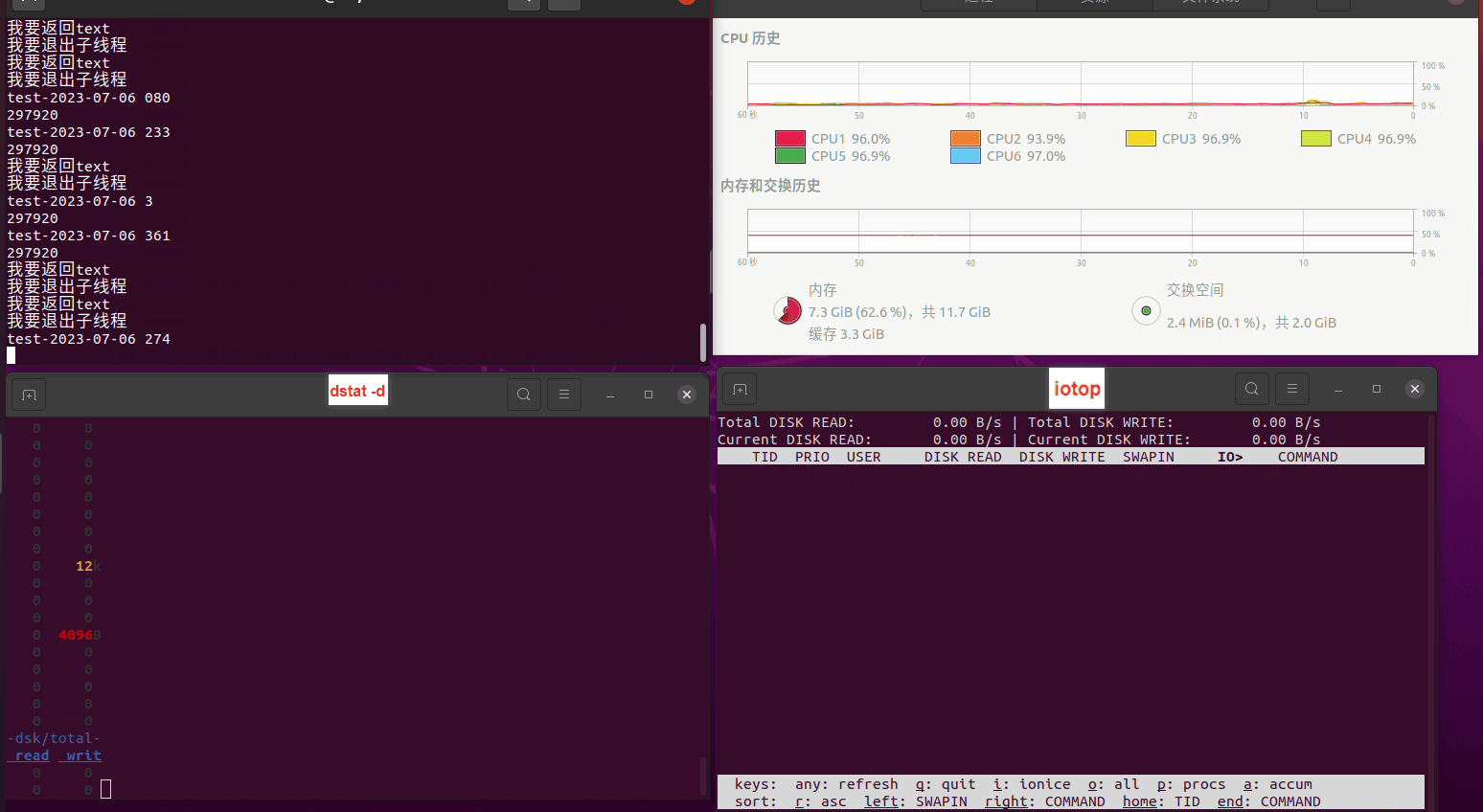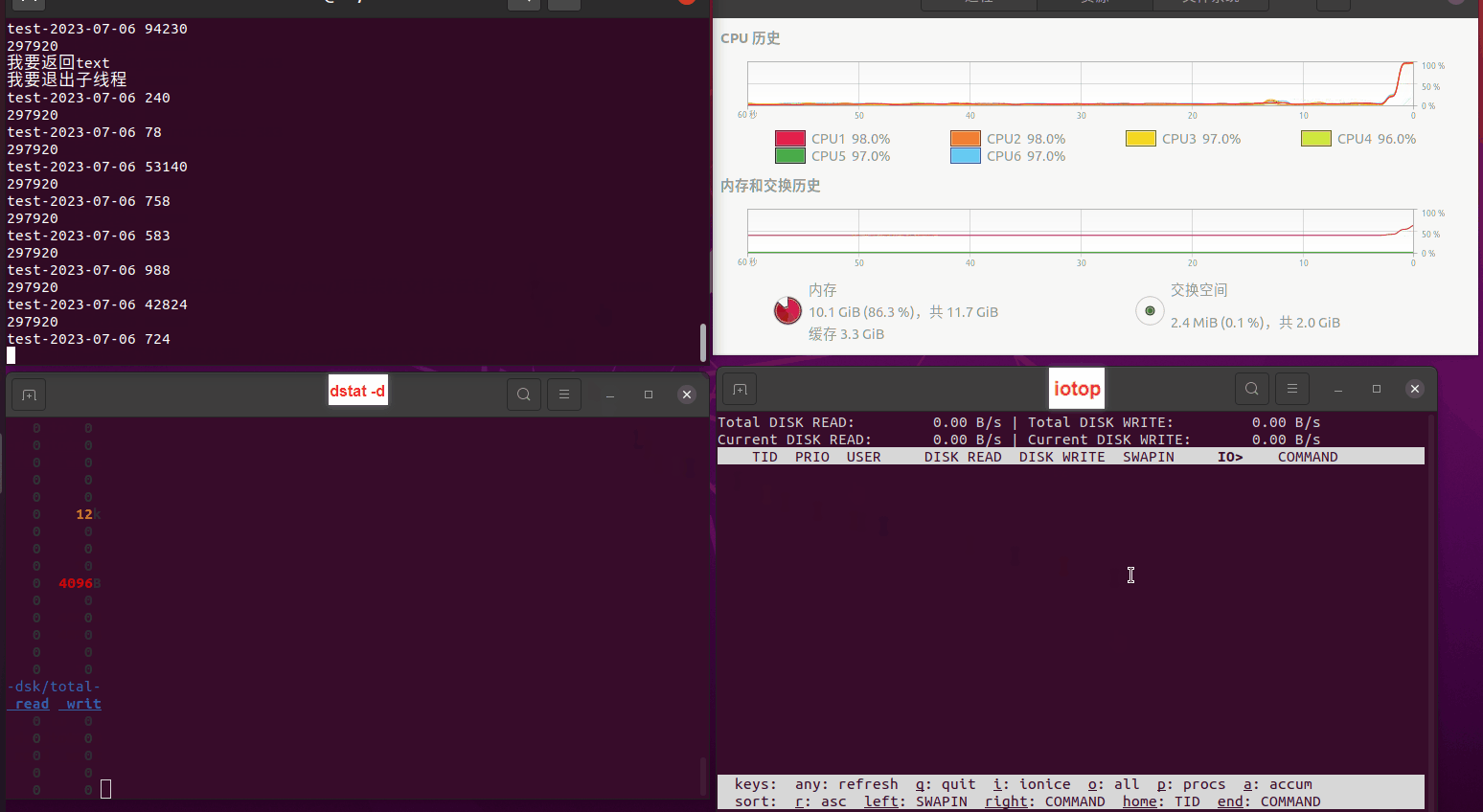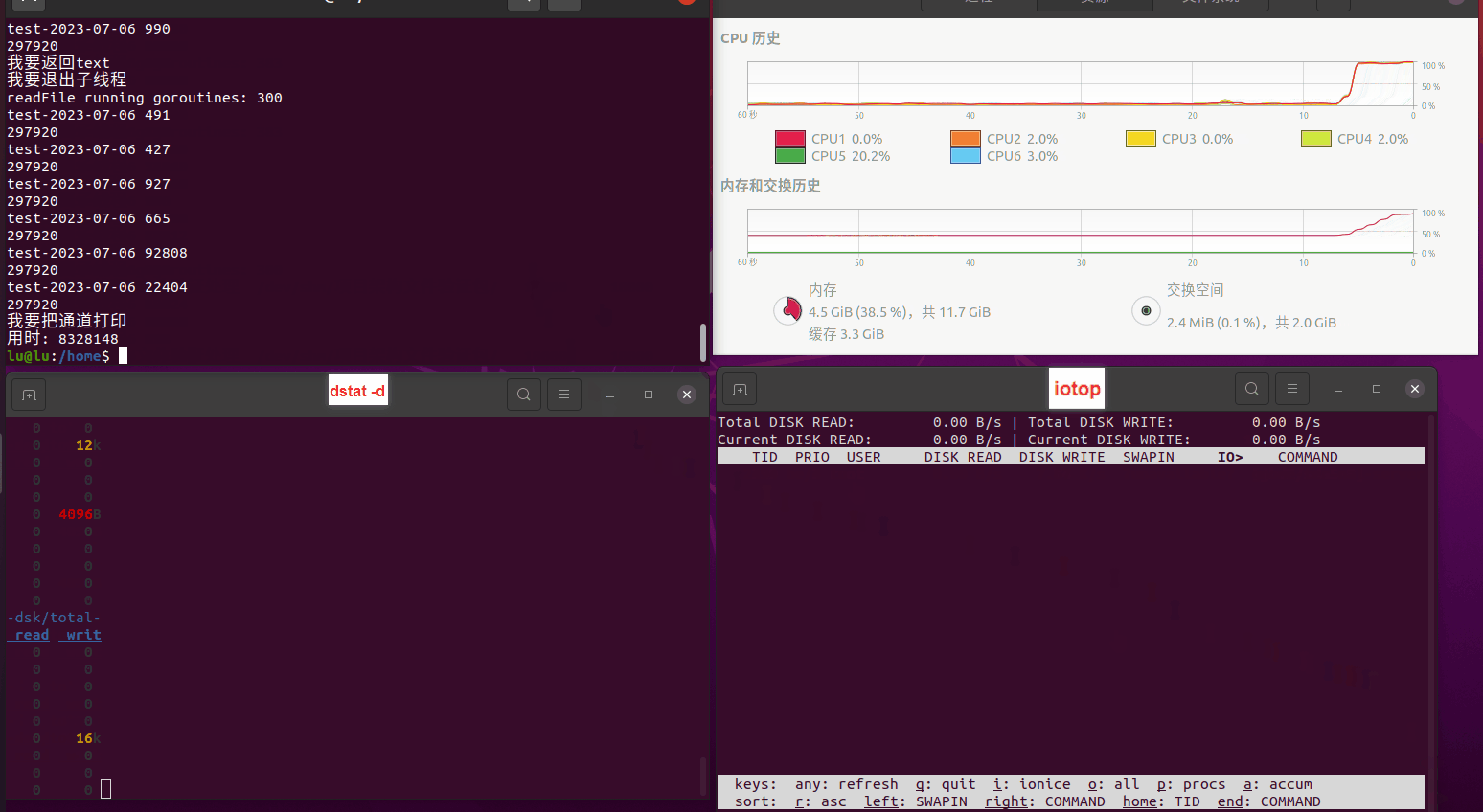
读任务线程池最大线程数量 解析任务线程池最大线程数量 最终用时(us) 1 1 33684140 2 1 16304544 3 1 16236443 4 1 16310520 4 2 9250718 4 3 9350257 4 4 9403874 3 3 11490599 5 5 8993891 6 6 8039352 7 7 7769768 8 8 7682735 9 9 8023354 10 10 7713602 13 13 7588479 17 17 7334632 20 20 7425200 50 50 7728117 200 200 11087723 500 500 超出系统资源限制触发保护(多次测试均终止于次,因此此无后续数据) tmpfs组:
读任务线程池最大线程数量 解析任务线程池最大线程数量 最终用时(us) readFile running goroutines 1 1 49289772 2 1 16383011 3 1 16276925 4 1 16273180 4 2 9405793 4 3 9802486 4 4 9638508 3 3 11126555 5 5 8703486 6 6 7987047 7 7 7818355 8 8 8024058 9 9 7554108 10 10 7965352 13 13 7714339 17 17 7680062 20 20 7579025 50 50 7677506 200 200 8498990 500 500 8087618 1000 1000 7789153 322 5000 5000 7976342 383 10000 10000 8328148 300 50000 50000 9828172 116 80000 80000 15584471 202
基于代码段3的实验->引入sync.Pool复用大对象,进一步提升性能
| 读任务线程池最大线程数量 | 解析任务线程池最大线程数量 | 最终用时(us) | 评价 | |
|---|---|---|---|---|
| 重跑代码段2 | 8 | 8 | 7828123 | 无sync.Pool |
| 代码段3 | 8 | 8 | 4305494 | 在代码段2的基础上 对大对象使用sync.Pool后 性能明显提升 |
基于代码段4的实验->用实例说明,对于小对象的复用,意义不大
| 读任务线程池最大线程数量 | 解析任务线程池最大线程数量 | 最终用时(us) | 评价 | |
|---|---|---|---|---|
| 重跑代码段2 | 8 | 8 | 7977741 | 无sync.Pool |
| 重跑代码段3 | 8 | 8 | 4520122 | 在代码段2的基础上 对大对象使用sync.Pool后 性能明显提升 |
| 代码段4 | 8 | 8 | 4406185 | 在代码段3的基础上, 对小对象使用sync.Pool后 性能仅存在一丁点变化且不一定是提升波动也可引起这种幅度的变化 故对小对象的复用, 意义不大 |























.png)